【跟李牧学AI】 ChatGPT是什么?--先看看InstructGPT
最近OpenAI公司的ChatGPT非常火爆,虽然正式的论文还没有发布,但是按照OpenAI一贯的工作思路,基于前期工作进行相应的改造,我们可以跟着沐神一起来看看InstructGPT,也算法对了解ChatGPT有个前期的知识储备。
instructGPT论文地址:
Training language models to follow instructions with human feedback
沐神视频链接:InstructGPT 论文精读【论文精读·48】
目录
摘要
介绍
数据集
模型
1)SFT
2)RM
RM损失函数
3)Reinforcement learning(RL)
RL损失函数
摘要
大型的语言模型效果虽然很好,但是会产生很多对用户不真实的,带有种族歧视的,甚至是有害的言论。而InstructGPT则是基于GPT3,在人工反馈的数据上训练了一版有监督的模型。效果是:1.3B 参数的 InstructGPT优于175B 参数的GPT-3,可以证明,通过人工反馈进行fine-tune是个有前景的方向。
介绍
instructGPT是如何工作的呢?
 step1:
step1:
挑一些prompt,让标注者写答案,基于这部分数据使用GPT-3进行fine-tune,得到模型SFT(supervised fine-tune)
step2:
第一步可以得到一个还不错的模型,但是成本高,也无法穷尽所有答案,所以第二步则是由SFT模型对问题采样出几个答案(GPT-3得到词的概率,再通过beam search采样出4个答案),再由人工判断这几个答案的优劣,然后训练出一个奖励模型RM(reward model)
step3:
使用强化学习的框架优化得到输出的策略:使用RM模型计算reward,并用PPO(后面会讲)来更新策略。
数据集
那么prompt是如何生成的呢?
1/Plain 让标注人员自己想---确保问题的多样性
2/Few-shot 让标注人员写指令,以及指令的答案。比如找出这段代码的错误。
3/User-based 标注人员根据用户让OpenAI回答的问题构建一部分prompt
用户问题分布:

基于这些数据,划分成了3个数据集:
1/ SFT,标注人员直接写答案,13k样本,API+人工标注
2/ RM,标注人员打分,33k样本,API+人工标注
3/PPO,31k样本,只有API的结果
然后开放在OpenAI的playground中,让用户使用,再根据用户ID收集一部分的问题(一个用户最多200个)。用户可能会针对一个问题,用不同的句子提问,所以根据用户ID划分不同的数据集,避免一个用户的问题同时出现在多个数据集中,污染结果。
这样就可以持续对模型进行迭代。
模型
InstructGPT中一共用到了3个模型
1)SFT
SET的训练比较简单,就是标注数据fine-tune,13k样本较少,结果会过拟合,但这个模型只是为了初始化后面的模型,后续发现过拟合反而对后续的训练反而是有帮助的。
2)RM
的话,输入是prompt和回答,输出是一个reward。用前面的SFT的模型,去除掉最后的softmax层,转而使用一个线性投影层得到一个输出为1的标量,这个标量就可以视作是RM中的reward。
RM损失函数
是一个比较常见的pair-wise ranking loss。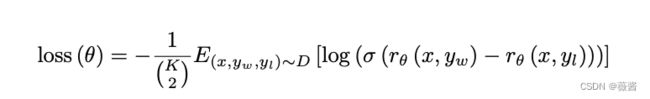
这里的K取的是9,每个prompt产出9个回答,9个回答两两匹配中生成36个pair对,在损失函数中,第一项的分母中除以pair对数,为了就是平衡掉不同K值带来的影响。
注意:OpenAI之前的工作中用的K=4,这里用的是K=9,好处有:
- 标注资源增长较少
对于同一个问题,标注9个答案仅仅比4个多出了一些时间,因为节约了读题和理解题目的时间(我不是很认可啊,排序我觉得还挺麻烦的)
- 6倍的训练数据
9个答案能产生36个pair对,而4个答案却只能产生6个pair对,训练数据量增加了6倍。
- 节约时间
最费时间的是![]() 的计算,9个回答只需要计算9次,但是能产出36个标量,相当于节省了4倍的时间。
的计算,9个回答只需要计算9次,但是能产出36个标量,相当于节省了4倍的时间。
相当于是标注资源增加不多的情况下,训练数据量变多,同时时间没有增加很多。
同时,前作是4个里面选最好的一个,会有过拟合的情况,这里改为全排序的话,帮助缓解过拟合。
3)Reinforcement learning(RL)
在强化学习的框架内,随着模型的更新,每次采样到的y是不一样的,相当于是强化学习的环境变了,那相应的,获得的奖励也变了。
RL损失函数
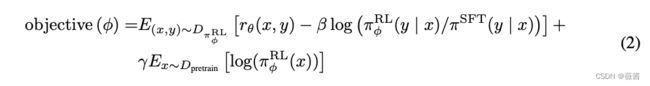
![]() 就是强化学习学到的结果
就是强化学习学到的结果
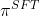 就是SFT学习到的结果
就是SFT学习到的结果
第一项:对于每个prompt,丢进RL模型中产生一个y,使用第二步的RM模型来计算![]() ,这里的RM模型是模拟人类,对每个y给出一个实时反馈。
,这里的RM模型是模拟人类,对每个y给出一个实时反馈。
第二项:而RM训练时产生的y是来自于,为了减小更新模型导致的数据分布不一致,所以第二项中使用了KL散度,使得模型学出来的结果和SFT的不要相差太多
最后一项:GPT-3原始的目标函数,使得整个模型能生成更有效回答的情况下,其他任务的性能不要下降太多。
前2项就是ppo模型,加上最后一项就是ppo-ptx模型。
沐神给了些其他建议:
1.大模型模型不稳定的话,使用小模型
2.与其使用不稳定的RL,不如在数据集上多下点功夫,多找人标注些数据集,效果也未必不好。
(ps:论文中间还提到了如何挑选标注人员,这个真的蛮重要的,低质的标注人员真的非常拖累整个项目进程。。。这个还有专门的论文讲这个事情,感兴趣的可以自己搜搜看)