js逆向系列之猿人学爬虫第17题-天杀的http2.0
文章目录
- 1. 目标网站
- 2. 抓包分析
- 3. 编码测试
1. 目标网站
网址:
https://match.yuanrenxue.com/match/17

2. 抓包分析
这道题目,叫天杀的http2.0,估计应该是用的http2.0协议。
我们验证一下,打开谷歌浏览器的console输入:window.chrome.loadTimes()
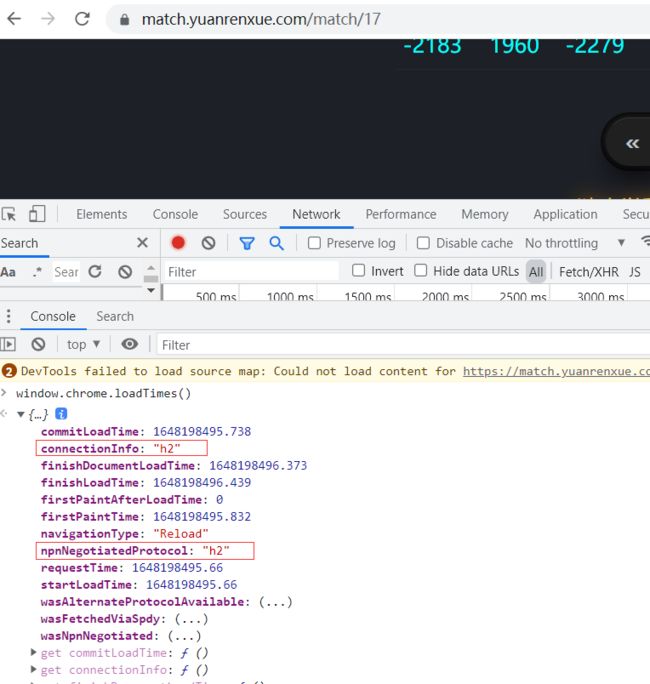
可以看到输出的connectionInfo 和 npnNegotiatedProtocol 是h2就说明使用的是http2。
再把我以前的博客粘一下。
现在的大部分网站都是基于HTTP/1.x协议的,但是还有一小部分是HTTP/2.0的,遇到这样的网站,爬虫的很多常用库都没法用了,目前python 的requests库并不支持http/2.0网站,scrapy2.5.0 即2021.4更新开始支持HTTP2.0,但是官网明确提示,现在是实验性的功能,不推荐用到生产环境,当前 Scrapy 的 HTTP/2.0 实现的已知限制包括:
- 不支持 HTTP/2.0 明文(h2c),因为没有主流浏览器支持未加密的 HTTP/2.0。
- 没有用于指定最大帧大小大于默认值 16384 的设置,发送更大帧的服务器的连接将失败。
- 不支持服务器推送。
- 不支持bytes_received和 headers_received信号。
关于其他的一些库,也不必多说了,对 HTTP/2.0 的支持也不好,目前对 HTTP/2.0 支持得还可以的有 hyper 和 httpx。
hyper使用参考
HTTPX使用参考
我们这里用hyper库,安装hyper库也很简单,直接pip install hyper就行了。
我们抓包获取数据包的url:
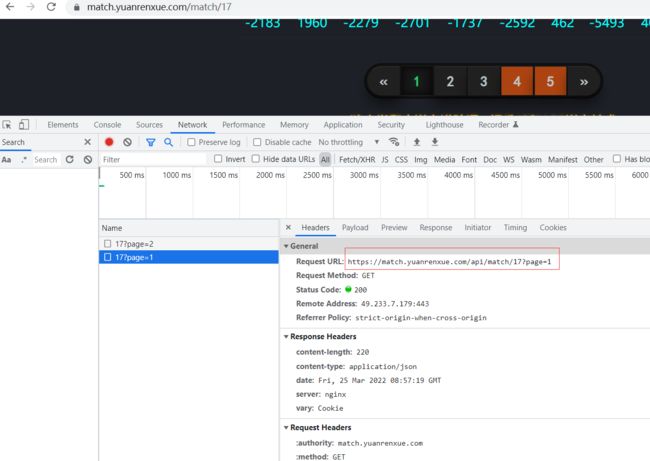
https://match.yuanrenxue.com/api/match/17?page=1
其他没啥需要注意的反爬,我们接下来直接上代码。
3. 编码测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 冰履踏青云
# @File : 17.py
import jsonpath
import requests
from hyper.contrib import HTTP20Adapter
def get_data(page):
url = 'https://match.yuanrenxue.com/api/match/17?page={}'
headers= {
"User-Agent": "yuanrenxue.project",
# 设置我们登陆账号时候的cookie,sessionid必须传 ,否则未登录状态下只可以抓前三页
"cookie": "sessionid=13guppo9dxzbdixi3v8wkqzme9473pij"
}
# 创建session对象,并设置请求头
s = requests.session()
s.headers = headers
# 使用http2.0
s.mount('https://match.yuanrenxue.com', HTTP20Adapter())
data = s.get(url.format(str(page))).json()
values_list = jsonpath.jsonpath(data,"$..value")
return values_list
if __name__ == '__main__':
res_list = []
for i in range(1,6):
values_list = get_data(i)
res_list.extend(values_list)
print(res_list,len(res_list))
print('所有数字之和为:',sum(res_list))

为便于学习交流草创了一个q群: Python炼丹大师交流群
后端 爬虫 数据分析 机器学习等和python相关的都可以在此畅所欲言
编程资源:编程学习资源传送门
文章到此结束,但愿本文能对你有一点点帮助,欢迎三连,点个赞,收个藏啥的,有问题的尽管砸来,我有故事你有酒,好好交流不分手!下次见!