2.Seq2Seq注意力机制
目录
- neural machine translation by jointly learning to align and translate
-
- Decoder解码器
- Encoder编码器
- effective approaches to attention-based neural machine translation
-
- global attention
- local attention
- 基于注意力机制的seq2seq模型原理实现实例
neural machine translation by jointly learning to align and translate
对encoder-decoder扩展,既能做翻译,又能对齐(align)。
预测的目标与下面有关。1.原序列中相关位置组成的上下文,2.之前生成的目标单词。
Decoder解码器
一个RNN构成
p(yi|y1,…,yi-1,x)=g(yi-1,si,ci)
si=f(si-1,yi-1,ci)
ci=ΣT~x~j=1αijhj
yi-1是上一时刻预测的值
si是解码器在RNN网络当前时刻的状态
当前时刻,从编码器中获取的上下文ci,也叫通过注意力机制计算出的当前时刻编码器的表征
word embedding输入到双向RNN中,会得h到全局上下文相关的表征h,是编码器的状态
αij=exp(eij)/ΣTxk=1exp(eik)
eij=a(si-1,hj)
αij由softmax计算,当前第i时刻解码器要去做预测,解码器第j个位置。αij表示当前解码器对所有编码器的注意力权重,越大表示对第j个位置上的输出所需要的程度更大;也可以理解为解码器在第i时刻对整个编码器序列的关注程度。αij可以看作ij两者的相互作用,由上一时刻解码器的状态si-1和编码器第j时刻的输出hj,根据公式得到。每个位置上的α相加和为1。
eij可以称为score,表示解码器的状态和编码器每个位置上状态之间的匹配程度。
Encoder编码器
双向RNN:forward RNN和backward RNN。将两个的结果的特征拼接起来。
effective approaches to attention-based neural machine translation
全局与局部的区别:注意力是散落在编码器的所有位置上,还是一小部分上。类似于池化,平均池化可以理解为全局attention,最大池化可以理解为局部attention。
无论采用哪一类注意力机制,解码器解码时都需要上下文向量ct,即当前这一步所依赖的编码器的信息量。
global attention
非单调对应关系一般需要用global attention
变长对齐向量at(variable-length alignment),变长是指大小与编码器当前时间步骤有关。
权重向量基于当前解码器的隐藏状态ht跟编码器的每一个隐藏状态h-s之间的关联性。
at(s)=align(ht,h-s)=exp(score(ht,h-s))/Σs’exp(score(ht,h-s))
score是一个基于内容(content-based)的函数,基于内容即只考虑当前解码器的状态跟当前编码器每一个状态之间的对齐性不用考虑具体位置上的。三种计算方式:
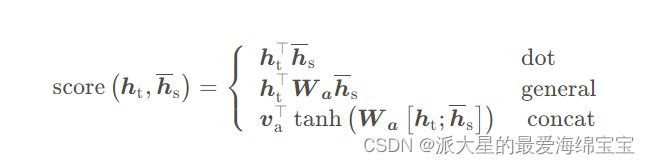
第二种叫乘法注意力机制,因为两个h通过W相乘的。第三种也叫加法注意力机制,计算时是Wht+Wh-s。
<基于位置/strong>(location-based)的不再考虑编码器的输出,对当前解码器的隐藏状态ht计算:
at=softmax(Waht)
缺点:计算量比较大,需要对原序列每个位置上计算权重,做一个加权求和。甚至一些任务,不要计算全局的。
local attention
单调的一般使用local attention,单调的类似于中文和拼音两个序列的关系。
本文中的local attention主要集中在一个很小的上下文窗口内。计算量小且容易训练。
首先在t时刻,生成一个对齐位置(aligned position)pt,即当前位置确定一个中心位置。
以pt为中心,左右拓宽D个单位的窗口[pt-D,pt+D],计算出文本向量ct。它的at是固定的,为2D+1。
Monotonic alignment(local-m):将pt=t,原句子和目标句子是单调对齐的。at可根据这个公式计算:
at(s)=at(s)=align(ht,h-s)=exp(score(ht,h-s))/Σs’exp(score(ht,h-s))
Predictive alignment(local-p):计算出pt:
pt=S·sigmod(vTptanh(Wpht))
S是原序列的长度,
at(s)=align(ht,h-s)exp(-(s-pt)2/2σ2)
通过使用中心为pt、方差为σ的高斯分布,对计算出的全局的权重进行筛选,at被约束在了以pt为中心的一小部分窗口内。
σ=D/2
s是一个整数,可以对编码器的位置做一个整数的索引
基于注意力机制的seq2seq模型原理实现实例
embedding_size是输入序列每个单词的embedding vector的长度
hidden_size是lstm的记忆单元和隐藏单元的大小
batch_size为Ture:batch_size在前
实例化的embedding_table是将原序列的token转化为一个一个token embedding即词向量表格,是可以训练的
input_ids得到每个单词的id
input_sequence的size是【batch_size,scr_len,embedding_dim】
上下文相关表征output_states的size是【batch_size,seauence_len,hidden_size】
encoder_states完整的编码器的输出序列
logits是整个解码器完整的每一时刻的分类的logits