论文笔记: Monocular Depth Estimation: a Review of the 2022 State of the Art
中文标题:单目深度估计:回顾2022年最先进技术
本文对比了物种最近的基于深度学习的单目深度估计方法:
- GPLDepth(2022)[15]: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth
- Adabins(2021)[1]: Adabins: Depth estimation using adaptive bins
- 3Dshape(2021)[34]: Learning to recover 3D scene shape from a single image
- MiDaS(2020)[22]: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer
- DPT(2021)[21]: Vision transformers for dense prediction
算法简述
GLPDepth

- GLPDepth使用一个Transformer作为编解码模块。
- 对比以往的方法主要提升是一个数据增强方法-Vertical Cutdepth。由于单目深度估计主要使用垂直信息进行预测,因此最好替代图像的垂直波段。

- 左下是[14]中的数据增强方法,右下是[15]中的数据增强方法。
Adabins
- Adabins 认为深度估计问题是一个分类问题,像[9]一样。和[9]不同的是每一个bin有一个自适应的宽度。
- Adabins的编解码器是EfficientNet B5。然后基于transformer的Adabin模块同时预测bin宽度以及每个像素属于bin的概率。
MiDaS
- 没有提出一个新的架构或一个新的损失,而是表明结合多个训练数据集可以使更好的性能和更好的泛化。
- 作者观察到,使用一个在分类任务上表现更好的基础网络可以获得更好的单眼深度估计性能。
DPT
- DPT通过将基础架构转换为基于Transfromer的编译码器架构来扩展MiDaS。
- 具体算法介绍可见博客:论文笔记:DPT
3DShape
- 3DShape还研究了从估计的深度图中创建一个三维模型的问题。
- 三种不同的损失函数:
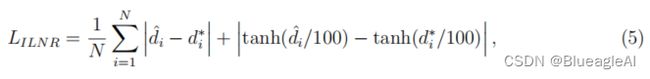
- 一个图片级的归一化损失函数, d ^ \hat d d^是预测的深度, d ∗ d^* d∗是真实标签的均值方差。
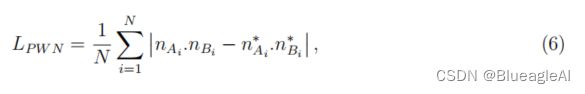
- 一个成对的表面法向量损失。对于A和B两组在三维结构的边缘和平面上采样的成对点,n(n∗)是对预测的三维点云(分别为地面真点云)的法态估计。
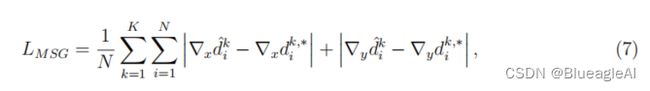
- 一个多层梯度损失
实验对比
- 参考原文,从不同种类的图像对比了不同方法的效果。个人感觉MiDaS以及DPT效果最好。
参考文献
[0] Ehret T. Monocular Depth Estimation: a Review of the 2022 State of the Art[J]. Image Processing On Line, 2023, 13: 38-56.
[1] S. F. Bhat, I. Alhashim, and P. Wonka, Adabins: Depth estimation using adaptive bins, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 4009–4018. https://doi.org/10.1109/CVPR46437.2021.00400.
[9] H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, Deep ordinal regression network for monocular depth estimation, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2002–2011. https://doi.org/10.1109/CVPR.2018.00214.
[14] Y. Ishii and T. Yamashita, CutDepth: Edge-aware Data Augmentation in Depth Estimation, arXiv preprint arXiv:2107.07684, (2021). https://doi.org/10.48550/arXiv.2107.07684.
[15] D. Kim, W. Ga, P. Ahn, D. Joo, S. Chun, and J. Kim, Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth, arXiv preprint arXiv:2201.07436, (2022). https://doi.org/10.48550/arXiv.2201.07436.
[21] R. Ranftl, A. Bochkovskiy, and V. Koltun, Vision transformers for dense prediction, in IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 12179–12188. https://doi.org/10.1109/ICCV48922.2021.01196.
[22] R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V. Koltun, Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer, IEEE Transactions on Pattern Analysis and Machine Intelligence, (2020). https://doi.org/10.1109/TPAMI.2020.3019967.
[34] W. Yin, J. Zhang, O. Wang, S. Niklaus, L. Mai, S. Chen, and C. Shen, Learning to recover 3D scene shape from a single image, in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 204–213. https://doi.org/10.1109/CVPR46437. 2021.00027.