MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis笔记
文章目录
- 简介
- 网络细节
-
- 生成器
-
- 总体结构
- 源码分析
- 设计思路
- 判别器
-
- 总体结构
- 源码分析
- 损失函数
- 实验结果
论文地址:《 MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis》
官方源码:github地址
简介
常见的TTS系统不是直接生成音频,而是中间先生成一种声学特征(多数为Mel频谱图),再由声学特征生成音频。MelGAN解决的就是声学特征(Mel谱图)->音频问题,也就是常说的声码器部分。

目前Mel频谱–>音频的方法主要可以分为三类:
①信号处理方式:
常见有:Tacotron中使用的Griffin-Lim算法;Char2Wav中使用的WORLD声码器
缺点:需要引入明显的伪像(准确度不够)
②自回归网络
常见有:WaveNet(Tacotron2中作为声码器);SimpleRNN;WaveRNN
缺点:必须自下而上产生音频,效率低(速度不够)
③非自回归网络
常见有:Parallel WaveNet;ClariNet;WaveGlow
缺点:训练成本较大
MelGAN的优点:
- MelGAN是一种非自回归前馈卷积架构,是第一个由GAN去实现原始音频的生成,在没有额外的蒸馏和感知损失的引入下仍能产生高质量的语音合成模型。
- MelGAN解码器可替代自回归模型,以生成原始音频。
- MelGAN的速度明显快于其他Mel谱图转换到音频的方法,在保证音频质量没有明显下降的情况下比迄今为止最快的可用模型快10倍。
网络细节
生成器
输入:Mel谱图 输出:音频
总体结构
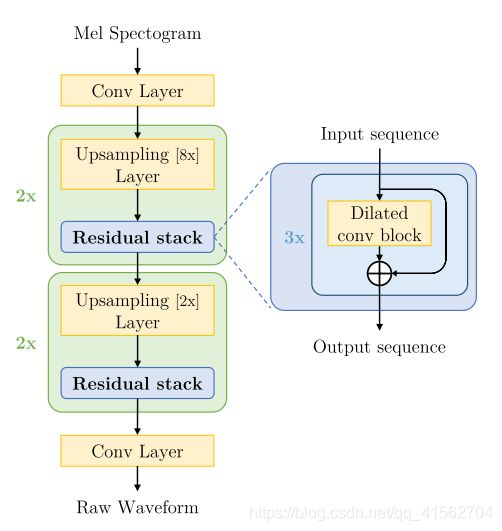
其中残差块结构:
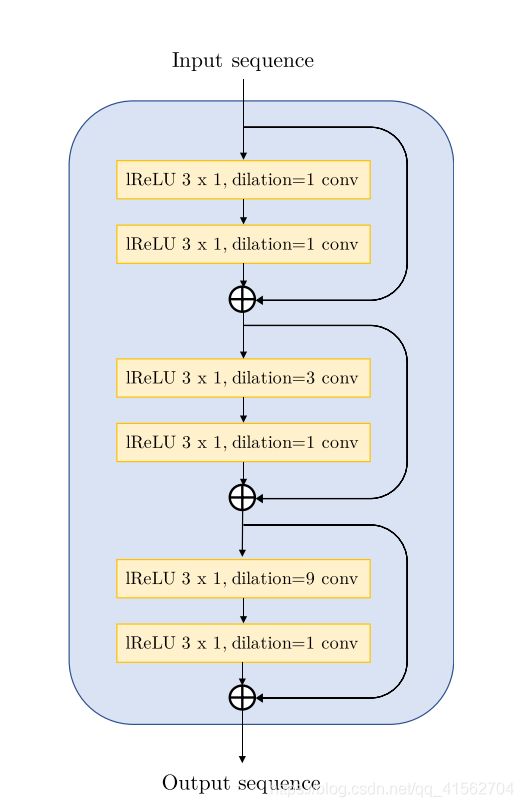
经过一层Conv层后送到上采样网络块,上采样网络块一共有4个,依次为8x,8x,2x,2x,每个上采样网络块中嵌套残差块,每个残差块有三层,依次dilation为1,3,9,最后经过一层conv层得到音频输出,由于音频的channel表示为1,所以最后一层的channel设为1。
源码分析
#对一维卷积层进行Weight Norm
def WNConv1d(*args, **kwargs):
return weight_norm(nn.Conv1d(*args, **kwargs))
#对一维反卷积层进行Weight Norm
def WNConvTranspose1d(*args, **kwargs):
return weight_norm(nn.ConvTranspose1d(*args, **kwargs))
#残差块中一层的结构
class ResnetBlock(nn.Module):
def __init__(self, dim, dilation=1):
super().__init__()
#依次为两层卷积层
self.block = nn.Sequential(
nn.LeakyReLU(0.2),
nn.ReflectionPad1d(dilation),
WNConv1d(dim, dim, kernel_size=3, dilation=dilation),
nn.LeakyReLU(0.2),
WNConv1d(dim, dim, kernel_size=1),
)
self.shortcut = WNConv1d(dim, dim, kernel_size=1)
def forward(self, x):
return self.shortcut(x) + self.block(x) #残差连接
#生成器
class Generator(nn.Module):
def __init__(self, input_size, ngf, n_residual_layers):
super().__init__()
ratios = [8, 8, 2, 2]
self.hop_length = np.prod(ratios)
mult = int(2 ** len(ratios))
#第一层卷积
model = [
nn.ReflectionPad1d(3),
WNConv1d(input_size, mult * ngf, kernel_size=7, padding=0),
]
# 上采样阶段,共4个,依次为8x,8x,2x,2x的UpSampling layer
for i, r in enumerate(ratios):
model += [
nn.LeakyReLU(0.2),
WNConvTranspose1d(
mult * ngf,
mult * ngf // 2,
kernel_size=r * 2,
stride=r,
padding=r // 2 + r % 2,
output_padding=r % 2,
),
]
#加入残差块,每个残差块中有3层,dilation分别为1,3,9
for j in range(n_residual_layers):
model += [ResnetBlock(mult * ngf // 2, dilation=3 ** j)]
mult //= 2
#最后一层卷积层
model += [
nn.LeakyReLU(0.2),
nn.ReflectionPad1d(3),
WNConv1d(ngf, 1, kernel_size=7, padding=0),
nn.Tanh(),
]
self.model = nn.Sequential(*model)
self.apply(weights_init)
def forward(self, x):
return self.model(x)
设计思路
1.Mel频谱图的时间分辨率比原始音频低256倍,所以使用了堆叠的反卷积层进行unsample。
2.条件信息足够的情况下,在输入处增加噪声是不必要的。所以与传统GAN不同,笨笨并没有增加noise input
3.使用残差块解决梯度消散的问题,空洞卷积层的感受野随层数的增加而指数增加,能够有效地增加每个输出时间步长的感应野。
4.反卷积层的k-size和stride仔细选择决定的,可以减少artifacts的出现。
5.归一化选择Weight Norm,因为不会限制判别器的空间,也不会对激活进行归一化
判别器
输入:音频 输出:feature Map
总体结构
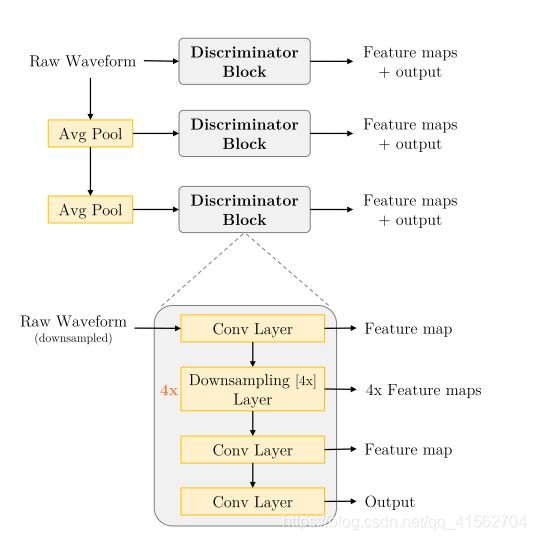
判别器,采用多尺度架构,除了对原始音频做判别,还对原始音频做降频处理(采用Avg pooling方式)后再馈送到判别器下进行判别,共有3个Discriminator Block。Discriminator Block是有卷积层和下采样层组成。
基于多尺度架构的判别器,是为了保证捕获音频中的高频结构,而且具有较少的参数,运行速度更快还可以应用于可变长度的音频序列。
源码分析
#对一维卷积层进行Weight Norm
def WNConv1d(*args, **kwargs):
return weight_norm(nn.Conv1d(*args, **kwargs))
#对一维反卷积层进行Weight Norm
def WNConvTranspose1d(*args, **kwargs):
return weight_norm(nn.ConvTranspose1d(*args, **kwargs))
#Discriminator Block结构
class NLayerDiscriminator(nn.Module):
def __init__(self, ndf, n_layers, downsampling_factor):
super().__init__()
model = nn.ModuleDict()
#第一层卷积
model["layer_0"] = nn.Sequential(
nn.ReflectionPad1d(7),
WNConv1d(1, ndf, kernel_size=15),
nn.LeakyReLU(0.2, True),
)
nf = ndf
stride = downsampling_factor
#4层4x Downsampling Layer
for n in range(1, n_layers + 1):
nf_prev = nf
nf = min(nf * stride, 1024)
model["layer_%d" % n] = nn.Sequential(
WNConv1d(
nf_prev,
nf,
kernel_size=stride * 10 + 1,
stride=stride,
padding=stride * 5,
groups=nf_prev // 4,
),
nn.LeakyReLU(0.2, True),
)
nf = min(nf * 2, 1024)
#第2层卷积层
model["layer_%d" % (n_layers + 1)] = nn.Sequential(
WNConv1d(nf_prev, nf, kernel_size=5, stride=1, padding=2),
nn.LeakyReLU(0.2, True),
)
#第3层卷积层
model["layer_%d" % (n_layers + 2)] = WNConv1d(
nf, 1, kernel_size=3, stride=1, padding=1
)
self.model = model
def forward(self, x):
results = [] #存放每层输出的feature map
for key, layer in self.model.items():
x = layer(x)
results.append(x)
return results
#完整的判别器
class Discriminator(nn.Module):
def __init__(self, num_D, ndf, n_layers, downsampling_factor):
super().__init__()
self.model = nn.ModuleDict()
#3个Discriminator Block
for i in range(num_D):
self.model[f"disc_{i}"] = NLayerDiscriminator(
ndf, n_layers, downsampling_factor
)
#downsample函数
self.downsample = nn.AvgPool1d(4, stride=2, padding=1, count_include_pad=False)
self.apply(weights_init)
def forward(self, x):
results = []
for key, disc in self.model.items():
results.append(disc(x)) #每次降频处理得到的结果依次存放到result
x = self.downsample(x) #对输入x进行降频处理
return results
损失函数
min D k E x [ ( D k ( x ) − 1 ) 2 ] + E s , z [ D k ( G ( s , z ) ) 2 ] , ∀ k = 1 , 2 , 3 \min _{D_{k}} \mathbb{E}_{x}\left[\left(D_{k}(x)-1\right)^{2}\right]+\mathbb{E}_{s, z}\left[D_{k}(G(s, z))^{2}\right], \forall k=1,2,3 \\ DkminEx[(Dk(x)−1)2]+Es,z[Dk(G(s,z))2],∀k=1,2,3
化简为
min G E s , z [ ∑ k = 1 , 2 , 3 ( D k ( G ( s , z ) ) − 1 ) 2 ] \min _{G} \mathbb{E}_{s, z}\left[\sum_{k=1,2,3}\left(D_{k}(G(s, z))-1\right)^{2}\right] GminEs,z⎣⎡k=1,2,3∑(Dk(G(s,z))−1)2⎦⎤
x x x表示音频, s s s表示mel谱图, z z z表示高斯噪声
加入Feature Matching损失 L F M L_{FM} LFM,这一损失除了优化判别器,也优化了生成器,使真实和合成音频的判别器特征图之间的 L 1 L1 L1距离最小。
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲\mathcal{L}_{\m…
最终损失函数为
min G ( E s , z [ ∑ k = 1 , 2 , 3 ( D k ( G ( s , z ) ) − 1 ) 2 ] + λ ∑ k = 1 3 L F M ( G , D k ) ) \min _{G}\left(\mathbb{E}_{s,z}\left[\sum_{k=1,2,3}\left(D_{k}(G(s, z))-1\right)^{2}\right]+\lambda \sum_{k=1}^{3} \mathcal{L}_{\mathrm{FM}}\left(G, D_{k}\right)\right) Gmin⎝⎛Es,z⎣⎡k=1,2,3∑(Dk(G(s,z))−1)2⎦⎤+λk=1∑3LFM(G,Dk)⎠⎞
实验结果
1.TTS

将MelGAN作为TTS系统的声码器部分,法案现MelGAN的效果跟WaveGlow差不多,但是MelGAN的速度会快很多。
2.音频重构
MelGAN VQ-VAE:将VQ-VAE中的声码器替换为MelGAN,在无条件下实现了VQ-VAE这种无条件的音频重构。网络框架图如下。
