【图像分类—VGG】 Very deep convolutional networks for large-scale image recognition

一、论文翻译
论文:Very deep convolutional networks for large-scale image recognition
VGG对于Alexnet来说,改进并不是很大,主要改进就在于使用了小卷积核,网络是分段卷积网络,通过max pooling过度,同时网络更深更宽。分别在定位和分类问题中获得了第一和第二名。我们还表明,我们的方法很好地推广到了其他数据集上,在那里他们实现了最好的结果。
摘要
在这项工作中,我们研究了卷积网络的深度对大规模图像识别任务精度的影响。我们的主要贡献是使用非常小(3×3)卷积滤波器架构来对加深的网络进行全面评估,这也表明通过将卷积层加深到16-19层可以让结果得到显著的提高。这些发现是基于我们在2014年ImageNet挑战赛中所提交结果的基础之上的,我们的团队分别获得了定位赛和分类赛的第一名和第二名。我们还发现,我们的网络可以很好地适用于其他数据集,并可以取得最先进的(state-of-the-art)结果。我们已经公开了两个性能最佳的ConvNet模型,以便进一步研究在计算机视觉中的深度视觉表示。
1 介绍
卷积神经网络(ConvNets)最近在大规模图像和视频识别领域取得了巨大成功(Krizhevsky et al., 2012; Zeiler & Fergus, 2013; Sermanet et al., 2014; Simonyan & Zisserman, 2014),很大的功劳来自于大规模图像数据集如ImageNet(Deng et al., 2009),以及高性能计算系统(如GPU或者大规模分布式集群)。特别是,ImageNet打过视觉识别挑战赛(ILSVRC)(Russakovsky et al., 2014)在深度视觉识别框架的发展中发挥了重要的作用,它已经成为了几代大规模图像分类系统的试验台,从高维度浅层特征编码(Perronnin et al., 2010) (the winner of ILSVRC-2011)到深度卷积神经网络(Krizhevsky et al., 2012) (the winner of ILSVRC-2012)。
随着ConvNets在计算机视觉领域变得越来越常见,许多人尝试着去改进Krizhevsky et al.(2012)提出的原始网络框架,以取得更好的准确率。例如,ILSVRC-2013 (Zeiler & Fergus, 2013; Sermanet et al., 2014)的最佳结果使用了更小的接收窗口以及在第一层的更小的步长。另一种改进方案是在整个图像和多尺度的图像上作训练和测试(Sermanet et al., 2014; Howard, 2014)。在本文中,我们处理的是ConvNet架构设计中的另一个重要因素——网络深度。为此,我们修改了框架的其他参数,并通过添加更多的卷积层来稳定地增加网络的深度,由于在所有的层里面都使用了较小的卷积核(3×3),所以这也是可行的。
因此,我们提出了更精确的ConvNet架构,它不仅实现了ILSVRC分类和定位任务的最优结果,而且还适用于其他的图像识别数据集,甚至在用作相对简单的流水线时(比如,使用一个不需要微调的线性SVM进行分类的深度特征)可以实现卓越的性能。我们已经开源了两个性能最好的模型,以便于进一步研究。
本文的剩余部分安排如下。在第二节,我们会描述我们的卷积神经网络框架结构。图像分类的训练和评估细节会在第三节中介绍。在第四节中会将在ILSVRC分类任务的实验结果进行比较。
2 卷积神经网络配置
为了度量在近似条件下卷积神经网络深度增加带来的改进,我们所有的卷积层配置都采用了同样的准则(受Ciresan et al. (2011) ; Krizhevsky et al. (2012) 启发)。在这一节中,我们首先会描述卷积神经网络配置的一般布局(2.1节),然后会详细介绍评估时采用的特定配置(2.2节)。再接着讨论我们的设计选择,并将其与第2.3节中的现有算法进行比较。
2.1 结构
在训练过程中,我们的ConvNets的输入是固定尺寸的 224 × 224 224\times224 224×224的RGB图像。我们所做的唯一预处理操作是从每个像素中减去训练集中所有图像的RGB均值。图像经过了一层层的接受视野非常小且卷积核大小为 3 × 3 3\times3 3×3的卷积层(这是捕获左/右、上/下、中心信息的最小尺寸)。在其中一种配置中,我们也使用了 1 × 1 1\times1 1×1的卷积核,也可以看做是对输入通道的一个线性变换(随后是非线性变换)。卷积步长(stride)被固定为1个像素;对卷积层输入的空间填充(padding)会在卷积操作后仍然保留之前的空间分辨率,比如:对于卷积核为 3 × 3 3\times3 3×3的卷积层padding为1个像素。空间池化(pooling)是由5个最大池化层完成,通常会放在一些卷积层之后(不是所有的卷积层之后都会接上最大池化层)。最大池化(Max-pooling)是在一个 2 × 2 2\times2 2×2的像素窗口中执行,步长为2。
一堆卷积层(在不同的架构中有不同的深度)之后是三个全连接层(FC):前两个各有4096个通道,第三个会进行1000种ILSVRC分类,因此有1000个通道(每个对应一个类)。最后一层是soft-max层。全连接层的配置在所有网络中都是相同的。
所有的隐含层都配套放置了一个非线性校正单元(ReLU (Krizhevsky et al., 2012))。我们注意到我们的网络(除了一个之外)都没有包含局部响应归一化(LRN)(Krizhevsky et al., 2012)。在第四节中会说明,这种归一化并不会提高网络在ILSRVC数据集上的性能,却会导致内存的消耗以及计算时间的增加。在适用的情况下,LRN层的参数都是(Krizhevsky et al., 2012)的参数。
2.2 配置
本文中评估的卷积神经网络(ConvNet)的配置在表1中列出了,每列一个。下面我们将用他们的名2.字(A-E)来代指网络。所有的配置都遵循2.1节中所提到的方法设计,仅仅在网络的深度上有所不同:从网络A的11个权重层(8个卷积层和3个全连接层)到网络E的19个权重层(16个卷积层和3个全连接层)。卷积层的宽度(通道数)相对较小,从第一层的64开始,随后在每个最大池化层(max-pooling)后都会增加2倍,知道最后达到512。
在表2中,我们报告了没种配置的参数数量。尽管深度很大,我们的网络的权重参数数量并不多于网络更浅卷积层和感受视野更大的网络(144M weights in (Sermanet et al., 2014))的参数。
2.3 讨论
我们的ConvNet配置与ILSVRC-2012 (Krizhevsky et al., 2012)和ILSVRC-2013比赛(Zeiler & Fergus, 2013; Sermanet et al., 2014)的最佳参赛作品中所使用的配置截然不同。我们在整个网络中使用了非常小的 3 × 3 3\times3 3×3感受野,并会对输入的每个像素都做卷积操作(步长stride为1),而不是在第一个卷积层中使用相对更大的感受野(比如,在(Krizhevsky et al., 2012)中采用 11 × 11 11\times11 11×11的卷积核,步长为4;在(Zeiler & Fergus, 2013; Sermanet et al., 2014)中采用7*7的卷积核,步长为2)。很容易看出堆叠两个 3 × 3 3\times3 3×3的卷积层(之间没有空间池化)的有效感受野为 5 × 5 5\times5 5×5;三个这种层堆叠在一起的有效感受野为 7 × 7 7\times7 7×7.那么,我们通过将三个 3 × 3 3\times3 3×3的而不是 7 × 7 7\times7 7×7的卷积层堆在一起能得到什么?首先,我们合并了三个非线性校正层而不是单独一个,这样可以使得决策函数更有区别性。其次,我们减少了参数的数量:假设一个三层 3 × 3 3\times3 3×3卷积层组成的卷积块的输入和输出都有C个通道,那么这个块有 3 ( 3 2 C 2 ) = 27 C 2 3(3^2 C^2 )=27C^2 3(32C2)=27C2个权重参数;同时,一个单独的 7 × 7 7\times7 7×7卷积层,有 7 2 C 2 = 49 C 2 7^2 C^2=49C^2 72C2=49C2个参数,多出了81%的参数。这一步可以看做对 7 × 7 7\times7 7×7卷积核实行正则化,强迫他们通过 3 × 3 3\times3 3×3的滤波器进行分解(且在各层之间还额外加入了非线性)。
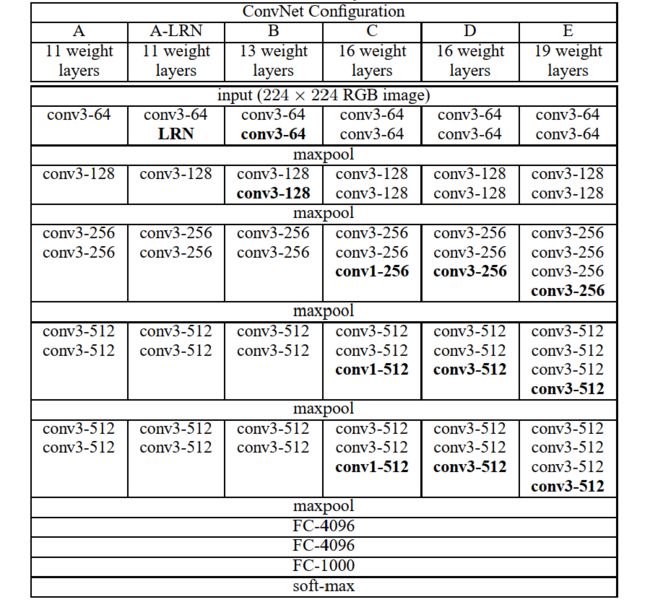

1 × 1 1\times1 1×1卷积层的加入(表1中的网络C)是增加决策函数的非线性程度并且不影响卷积层的感受野的一种不错的方法。尽管在我们这个情况下, 1 × 1 1\times1 1×1卷积本质上是对相同维度空间的一个线性映射(输入和输出的通道数相同),但是非线性校正函数又引入了额外的非线性。应该注意的是, 1 × 1 1\times1 1×1卷积最近被用于Lin (2014) 等人提出的“网络的网络”架构中。
Ciresan等人 (2011)曾使用了较小的卷积核,但是他们的网络明显不如我们的深,并且他们没有在大规模ILSVRC数据集行作评估。Goodfellow (2014)等人将深度卷积神经网络(11层)用于街道号识别任务,其结果表明增加网络深度有助于提高性能。GoogLeNet (Szegedy et al., 2014),是ILSVRC-2014分类任务中表现最好的一个入门框架,它的开发与我们的工作无关,但是有一点很类似:他们的网络也有很深的卷积神经网络(22层)和较小的卷积核(除了 3 × 3 3\times3 3×3卷积核之外,他们还是用了 1 × 1 1\times1 1×1和 5 × 5 5\times5 5×5卷积核)。他们的网络拓扑结构比我们的要复杂得多,并且特征谱(feature map)的空间分别率在第一层就减少了很多,以减少总体的计算开销。如4.5节中的结果表明,我们的模型在但网络分类准确性上超过了Szegedy等人(2014)的结果。
3. 分类结构
在之前的章节中,我们介绍了所提出的网络的配置细节。在本节中,我们将介绍ConvNet的训练和评估细节。
3.1 训练
ConvNet的训练过程基本上参考自Krizhevsky et al. (2012)(除了从多尺度的训练图像中抽取样本作为输入,后面会详细介绍)。也就是说,训练是通过使用带动量的小批量梯度下降法(基于反向传播算法(LeCun et al., 1989))来优化多项式逻辑回归目标。匹配大小设置为256,动量设置为0.9。训练时,通过权重衰减(L2惩罚乘数设置为 5 × 1 0 − 4 5\times10^{−4} 5×10−4)和给前两个全连接层添加dropout(dropout丢失率设置为0.5)来实现正则化。学习率最初设置为 1 0 − 2 10^{−2} 10−2,随后如果验证集的准确率停止提升就减少10倍。总体来说,学习率减少了3次,并且训练会在370k次迭代之后(74个epoch)停止。我们猜想,尽管与(Krizhevsky et al., 2012)相比,我们的网络的参数量更多也更深,但是我们的网络达到收敛所需的迭代次数更少,因为(a)由跟深和更小的卷积层会带来隐式的正则化;(b)某些特定层的与初始化。
网络权重的初始化很重要,因为如果初始化的参数不好,由于深度网络中的梯度稳定性下降,可能会导致训练停滞。为了避免这个问题,我们首先从训练配置A(如表1所示)开始,这个网络配置足够浅,可以随机初始化参数进行训练。然后,当训练更深的网络结构时,我们使用网络A的参数来初始化前4个卷积层和最后三个全连接层(多出的中间层随机初始化)。我们没有减少预初始化层的学习率,允许他们在训练过程中改变。对于随机初始化(如适用),我们从具有0均值和 1 0 − 2 10^{−2} 10−2方差的正太分布中随机采样权重。偏差初始化为0。值得注意的是,在提交论文后,我们发现可以通过使用Glorot & Bengio (2010)的随机初始化方法在没有预训练的情况下初始化权重。
为了获得固定尺寸的224*224的输入图像,他们从重新缩放的训练图像中随机裁剪得到(每次SGD迭代每个图像进行一次裁剪)。为了进一步增强训练集,裁剪时,还引入了随机水平翻转与随机的RGB颜色偏移(Krizhevsky et al., 2012)。下面将介绍训练图像的缩放。
训练图像尺寸。设S是各向同性重新调整的训练图像的最小一侧,从中ConvNet的输入图像会被裁剪(我们也称S为训练尺度)。虽然裁剪尺寸被固定为 224 × 224 224\times224 224×224,但原则上S可以取任何不小于224的值:对于S=224,裁剪时会获取整幅图像作为统计数据,完全跨越训练图像的最小侧;对于S≥224,裁剪后将对应与图像的一小部分,包含一个小物体或物体的一部分。
我们考虑了两种设置训练尺度S的方法。第一个是固定S,其对应于单一尺度训练(注意,从样本裁剪区域的图像内容仍然可以表示多尺度图像数据)。在我们的实验中,我们评估了两个固定尺度的模型:S=256(已被广泛用于现有技术中(Krizhevsky et al., 2012; Zeiler & Fergus, 2013; Sermanet et al., 2014)))和S=384。给定一个ConvNe的配置,我们首先使用S=256来进行训练。为了加速S=384时的网络的训练速度,它的参数使用S=256预训练得到的参数来进行初始化,并且我们也采用较小的初始学习率 1 0 − 3 10^{−3} 10−3。
设置S的第二种方法就是多尺度训练,其中每个训练图像都是通过从一个特定范围 [ S m i n , S m a x ] [S_{min},S_{max}] [Smin,Smax](我们令 S m i n = 256 S_{min}=256 Smin=256, S m a x = 512 S_{max}=512 Smax=512)随机采样S来单独调整。由于图像中的物体可能具有不同的大小,因此在训练时把这一点也考虑进去是有好处的。这也可以看做是缩放比例波动来增强训练集,这样单个模型就可以被训练为可以识别多个尺寸下的物体。出于考虑到速度的原因,我们通过对具有相同配置的单尺度模型的所有层进行微调来训练多尺度模型,并使用固定的S=384作预训练。
3.2 测试
在测试的时候,给定一个训练好的ConvNet和一个输入图像,它会以以下方式进行分类。首先,将其各向同性地重新缩放为预定义的最小图像尺寸,表示为Q(我们也将其称为测试尺度)。我们可以注意到,Q不一定等于训练尺寸S(如我们在第四节所示,对每个S使用几个不同的Q值可以提升性能)。然后,使用类似于(Sermanet et al., 2014)的方法,将重新缩放的测试图像密集地送入网络。也就是说,全连接层首先被转换为卷积层(第一个全连接层转为 7 × 7 7\times7 7×7的卷积层,后面两个转换为 1 × 1 1\times1 1×1卷积层)。然后将所得的全卷积网络应用于整个未裁剪的图像。其结果是一个类别评分谱,其通道数等于类别数,并且一个可变的空间分辨率取决于输入输入图像的大小。最后,为了获得图像的类别评分的固定大小的矢量,类别评分谱要是空间上平均的(sum-pooled)。我们还通过水平翻转图像来增加测试集;对原始和翻转的图像的soft-max输出进行平均以得到图像的最终分数。
由于全连接网络被应用于整个图像,因此不需要再测试时对其进行多次裁剪采样(Krizhevsky et al., 2012),如果在每次分割都需要网络重新计算这无疑是很低效的。与此同时,使用大量的裁剪图像数据集,如Szegedy等人(2014)所做,可以提升准确率,因为与全卷积网络相比它可以更精细地对图像进行采样。此外,由于卷积的边界条件不同,多尺度切割评估与密集评估是互补的:当应用ConvNet于切割图像时,卷积特征谱使用0来填充,然而在密集评估的情况下,同一个切割图像的填充(padding)自然会出现很多来自图像相邻区域的部分(由于卷积和空间池化),这也大大增加了整个网络的感受野,因此可以捕获到更多的图像信息。尽管我们认为在实际应用中这种会增加计算时间的多尺度图像切割操作不见得能带来准确率的提升,但我们也对 每个尺度做了50次图像切割( 5 × 5 5\times5 5×5的常规栅格和2种翻转)来评估我们的网络,总共在3个不同尺度下做了150次图像切割,这与Szegedy等人(2014)的4个不同尺度下的144次图像切割相当。
3.3 实现细节
我们的实现是基于开源的C++ Caffe工具箱(Jia, 2013)(2013年12月推出),但是包含有很多重要的改动,允许我们使用安装在单个系统的多块GPU对多尺度下的全尺寸图像(未分割)进行训练和评估(如上所述)。多GPU训练利用数据并行性,并且通过将每批训练图像分成几个GPU批次并在各个GPU上并行处理。在GPU计算完批梯度之后,对他们求平均来获得整个批次的梯度。梯度计算在GPU中是同步的,因此结果与在单个GPU上进行训练时完全相同。
尽管最近又有人提出了更加复杂的加速ConvNet的训练的方法(Krizhevsky, 2014),它们针对网络的不用层采用并行的模型与数据,但是我们发现我们的概念更简单的方案(在有4块的GPU系统上),相比于使用单个GPU已经有了3.75倍的加速。在配备了四个NVIDIA Titan Black GPU的系统上,根据架构的不同,训练单个网络需要花费2-3周。
4 分类实验
数据集。在这节中,我们将会给出前面所描述的ConvNet架构的在ILSVRC-2012数据集上的图像分类结果(用于ILSVRC 2012-2014挑战赛)。该数据集包含了1000个类别的图像,并且被分为三组:训练集(1.3M张图像)、验证集(50K张图像)和测试集(不带类标签的100K张图像)。我们使用两种方法来评估分类性能:top-1误差和top-5误差。前者是多分类误差,即错误分类图像的比例;后者是ILSVRC中使用的主要评估标准,并且按照图像的比例计算,以使gound-truth类别超出top-5预测的类别。
对于大多数汇演,我们将验证集作为测试集。当然也在测试集上进行了一些实验,并将其作为ILSVRC-2014竞赛(Russakovsky et al., 2014)的一个“VGG”参赛队伍的作品提交给了ILSVRC官方服务器。
4.1 单尺度评估
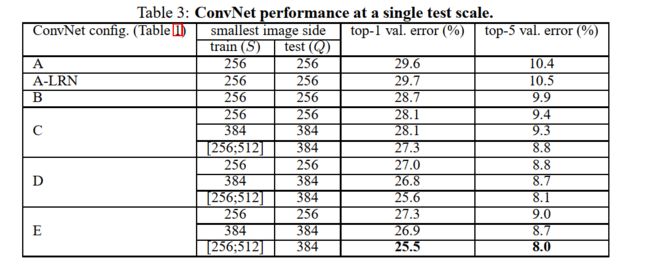
我们首先使用2.2节中所描述的网络架构在单一尺度上对独立的ConvNet模型进行评估。测试图像的尺寸如下:对于固定的S,Q=S;对于 S ∈ [ S m i n , S m a x ] , Q = 0.5 ( S m i n + S m a x ) S\in [S_{min},S_{max}],Q=0.5(S_{min}+S_{max}) S∈[Smin,Smax],Q=0.5(Smin+Smax)。结果在表3中给出。
首先,我们注意到使用局部响应归一化(A-LRN网络)相比于不带归一化层的模型A没有带来性能上的提升。因此我们没有在更深的架构(B-E)中采用归一化。
第二,我们观察到,随着ConvNet深度的增加分类误差也在减小:从模型A的11层到模型E的19层。很明显,尽管模型C(包含了3个 1 × 1 1\times1 1×1卷积层)有跟模型D相同的深度,模型C的性能不如模型D(在整个网络中都是用 3 × 3 3\times3 3×3卷积层)。这也说明,尽管额外的非线性层可以起到作用(模型C比模型B好),使用卷积滤波器来捕获有用的感受野也是很重要的(模型D比模型C好)。当网络的深度达到了19层,网络的错误率开始饱和,但是可能使用更深的模型也许更适合更大的数据集。我们还较浅的网络B与5个 5 × 5 5\times5 5×5卷积层的网络(由模型B衍生而来,将其中的一对 3 × 3 3\times3 3×3卷积层替换为了单独的 5 × 5 5\times5 5×5卷积层,这样可以保证有如2.3节中所述的相同的感受野)。浅层网络的top-1误差测出来,比B网络的高出了7%,这也说明一个更深滤波器更小的网络比一个浅层滤波器较大的网络更好。
最后,在训练时尺度波动( S ∈ [ 256 ; 512 ] S\in [256;512] S∈[256;512]),相比于使用固定尺度时(S=256或者S=512)可以带来相当显著的性功能提升,尽管在测试时仅仅使用单一尺度进行评估。这也证实通过尺度波动进行图像分割的确对获取多尺度图像数据很有用。
4.2 多尺度评估
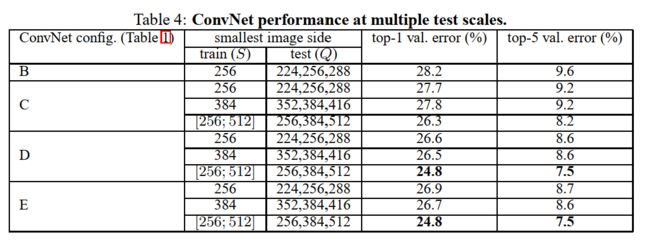
前面已经在单尺度下对ConvNet模型进行了评估,我们现在对测试时的尺度波动的影响作评估。先将几个不同的尺寸缩放的测试图像送入模型(对应于不同的Q值),随后再多输出的类别结果进行平均。考虑到训练和测试的尺度差距过大会导致准确率的下降,使用固定的尺度S进行训练的模型,在评估时使用较接近训练时图像尺寸的三个尺寸的测试图像进行测试: Q = { S − 32 , S , S + 32 } Q=\{S−32,S,S+32\} Q={S−32,S,S+32}。与此同时,训练时的尺度波动也让网络能在测试时应用于更宽范围的尺度,因此在训练模型时 S ∈ [ S m i n , S m a x ] S\in [S_{min},S_{max}] S∈[Smin,Smax],评估时使用更大范围的尺寸 Q = { S m i n , 0.5 ( S m i n + S m a x ) , S m a x } Q=\{S_{min},0.5(S_{min}+S_{max}),S_{max}\} Q={Smin,0.5(Smin+Smax),Smax}。
实验结果如表4所示,说明在测试时的尺度波动可以带来更好的效果(相比于表3中的使用单一尺度评估相同模型的结果)。跟前面一样,最深的网络(网络D和网络E)表现最出色,并且使用尺度波动也比使用一个固定的尺度S效果更好。我们的最好的单网络表现在验证集上达到了24.8%/7.5%的top-1/top-5错误率(在表4中加粗表示)。在测试集上,网络E实现了7.3%的top-5错误率。
4.3 多重裁剪评估
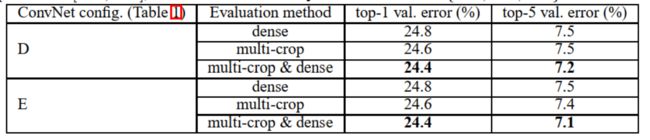
在表5中,我们密集卷积神经网络和多重裁剪评估进行了比较(详细见3.2节)。我们还通过对他们的soft-max输出做平均评估了两种评估技术的互补性。可以看出来,使用多重裁剪比密集平复稍微好一点,并且两种方法实际上是互补的,因为他们两者结合后比他们自身的结果要好。根据以上结果,我们猜想这可能是卷积边界条件的不同处理方法造成的。
4.4 卷积神经网络融合
至此,我们已经评估了独立ConvNet模型的结果。在实验的这一部分中,我们通过求取其soft-max输出的均值来结合几个不同模型的输出。由于模型之间的互补性,这能进一步提升模型的性能,这也分别在2012年(Krizhevsky et al., 2012)和2013年(Zeiler & Fergus, 2013; Sermanet et al., 2014)被用于ILSVRC的最好结果之中。
结果在表6中。在提交ILSVRC参赛模型时,我们只是训练了单尺度网络,还有一个多尺度模型D(只对全连接层进行微调而不是所有层)。7个网络的组合结果在ILSVRC上最终达到了7.3%的测试错误率。在提交模型之后,我们又考虑了仅使用两个表现最好的多尺度模型(网络D和网络E),使用密集评估时将测试错误率降低到了7.0%,而使用密集和多重裁剪评估融合时测试错误率降到了6.8%。作为参考,我们的性能最好的单网络模型错误率为7.1%(模型E,见表5)。
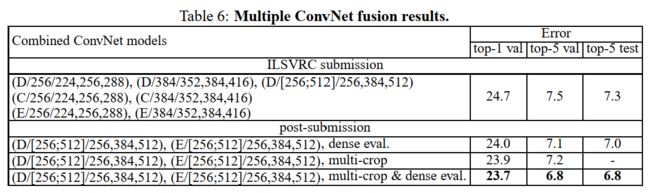
最后,我们还会将我们的结果与当前最好的技术相比较,见表7。在ILSVRC-2014挑战赛(Russakovsky et al., 2014)的分类任务中,我们“VGG”队融合7个模型的结果得到7.3%的测试错误率取得了第2名的成绩。在提交之后,我们又使用两个模型融合的结果将错误率降低到6.8%。
从表7中可以看出,我们的很深的ConvNet明显超过了此前的其他模型,它们分别在ILSVRC-2012和ILSVRC-2013比赛中取得了最佳结果。我们的结果与分类任务的冠军(GoogLeNet,错误率为6.7%)相比还是很有竞争性的,并且大体上都消耗过了ILVRC-2013的优胜团队提交的模型Clarifai,在使用了外部数据的情况下达到了11.2%,没有使用外部数据的情况下达到了11.7%。值得注意的是,我们的最佳结果是通过融合两个模型实现的,很明显比大多数在ILSVRC提交的模型少得多。在单网络性能上,我们的架构实现了最好的结果(7.0%的测试错误率),超过了单独的GoogLeNet模型0.9%。还要注意到,我们没有偏离ConvNet的经典结构(LeCun et al. (1989)),而是大大增加了网络的深度。

5 结论
在这次工作中我们评估了非常深的卷积神经网络(达到19层)用于大规模的图像分类。证明了深度有益于分类准确度,在ImageNet挑战数据集上的最先进的表现可以使用一个ConvNet架构(LeCun et al., 1989; Krizhevsky et al., 2012)加上深度的增加来实现。在附录中,我们还显示我们的模型适用于各种各样的任务的数据集,匹配或超过了构建在较深图像表示上的更复杂的管道。我们的结果再次证实了在视觉表示中深度的重要性。
References
二、论文解读
部分内容转载自VGGNet 阅读理解 - Very Deep Convolutional Networks for Large-Scale Image Recognition
这篇文章是以比赛为目的——解决ImageNet中的1000类图像分类和 localization(这里需要注意 localization 和 detection 的区别. localization是找到某个物体的检测框,而detection是找到所有物体的检测框)
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果.
需要注意的是,在VGGNet的6组实验中,后面的几个网络使用了pre-trained model A的某些层来做参数初始化。这点上虽然作者没有提该方法带来的性能增益,但其实是很大的(我会在下文中优秀的特征提取器和泛化能力具体说明.)
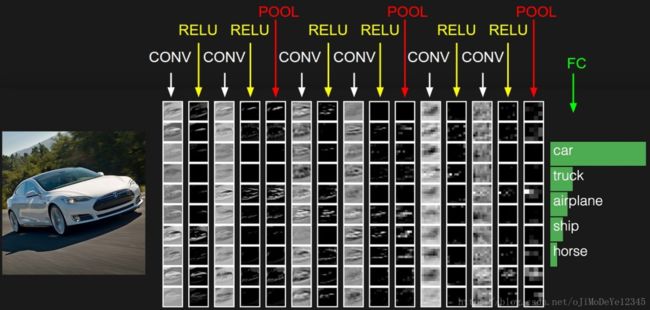
上图来自CS231n课程blog的tiny-vggnet模型架构,可以看到有三组卷积后接一个全连接层,每组卷积(blog里称为pattern)的形式都是一样的(conv-relu-conv-relu-pool),实际的VGG16(只算卷积和全连接层的个数是16)与上图略有不同(前两组conv-relu-conv-relu-pool,中间三组conv-relu-conv-relu-conv-relu-pool,最后三个fc,前两个fc是fc-relu-dropout,最后一个fc仅有fc。后文ConvNet
Configurations部分我会具体说明),不过整体来说作者也承认是继承了AlexNet和OverFeat:
- 继承了AlexNet不少网络结构(基于它加深层数和修改所有卷积核为3×3的小卷积),最后三个fc层基本算是平移AlexNet的到VGGNet上;
- 继承了OverFeat在Localization任务中的做法(we adopt the approach of Sermanet et al. (2014),没记错的话OverFeat拿了2013年Localization任务的第一名.)
VGGNet的两个特点:层数更深更宽、卷积核更小. 因为卷积核变小全部改用3×3大小(性能最好的两个网络:实验D(VGG16)和实验E(VGG19)),小卷积核的使用带来参数量减少,可以更加steadily地增加层数得同时不会太过于担心计算量的暴增.因为这篇文章正文写的是分类,附录介绍了VGGNet在localization上的工作,我也会对localization任务的解决进行分析.
这篇文章的主要特别的地方是前两点(换句话说,抄的不是很明显):
- 卷积核变小。作者做的6组实验中,卷积核全部替换为3×3(极少用了1×1),选用更小卷积核的motivation是作者受到这两篇文章(Zeiler & Fergus, 2013; Sermanet et al., 2014)启发,使用更小的卷积核尺寸和stride得到性能提升;
- 层数更深更宽(11层、13层、16层、19层)。我认为作者是觉得:既然小卷积核带来性能提升,那么不妨试试深度对性能的影响,反正参数量我的gpu可以cover住。作者的实验也发现层数越深,带来的分类结果也越好,但并没有提到channel变宽这一个因素:6组实验中channel数都是逐层加宽的,如果单说深度对性能的影响而忽略宽度(这里宽度不是feature map的width而是depth),我觉得并不够convincing,应该再加入一下对宽度(channel)数分析对比的实验;
- 池化核变小且为偶数。AlexNet中的max-pool全是3×3的,但VGGNet中都是2×2的。作者没有说明选择这种size的考量(现在stride=2、以及2×2和3×3的pooling
kernel选择的主流),我认为主要是2×2带来的信息损失相比3×3的比较小,相比3×3更容易捕获细小的特征变化起伏,此外或许是发现2×2的实验效果确实比3×3的好吧(毕竟这也是直接原因); - 网络测试阶段将训练阶段的三个全连接替换为三个卷积。对于训练和测试一样的输入维度下,网络参数量没有变化,计算量也没有变化,思想来自OverFeat,1×1的卷积思想则来自NIN。优点在于全卷积网络可以接收任意尺度的输入(这个任意也是有前提的,长和宽都要满足:a×2n,n是卷积与池化做stride=2的下采样的次数);
- 刷比赛的小技巧。其实没什么意思,比方输入图片的尺寸对于训练和测试阶段的处理方式不同,single和multi-scale的问题(具体见后文)。
1 任务背景

因为VGGNet在AlexNet之后,有必要先说一下问题的背景:自从AlexNet将深度学习的方法应用到图像分类取得state of the art的惊人结果后,大家都竞相效仿并在此基础上做了大量尝试和改进,先从两个性能提升的例子说起:
- 小卷积核。在第一个卷积层用了更小的卷积核和卷积stride(Zeiler & Fergus, 2013; Sermanet et
al., 2014); - 多尺度。训练和测试使用整张图的不同尺度(Sermanet et al., 2014; Howard, 2014)。
1.1 优秀的特征提取器和泛化能力
1.1.1 特征提取器
另外,作者发现训练出的卷积网络是一个天然的且十分优秀的特征提取器(在不对卷积网络进行fine-tuning而直接在其后接一个SVM分类器并训练该SVM,最终结果也很好),而且特征提取器在其他数据集上具有通用性。说到这点不得不提到RCNN这篇文章,因为该作者将CNN作为一个特征提取器,主要流程是前三个步骤(第四个检测框回归也只是在附录写到,下图是基于作者修改的图,略有不同):
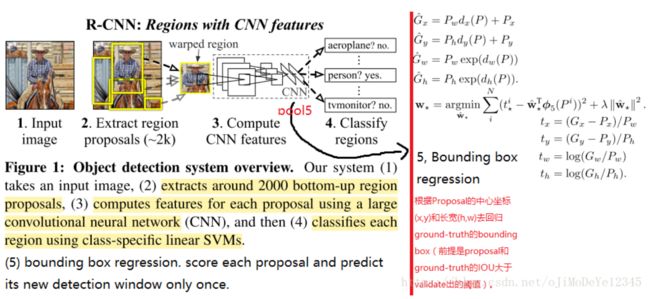
- (Supervised pre-training)用12年的分类数据去pre-train模型,CNN后接1k-way softmax
- (Domain-specific fine-tuning)用当年20类检测数据集生成分类数据(根据检测数据通过selective search生成小图,然后计算IOU大于0.5视为该类图像),去fine-tune模型,CNN后接20-way softmax;
- (Object category classifier)CNN参数固定,训练SVM。输入SVM的数据是CNN处理后的feature map,如果是20类那么对应20个,即分类20类的二分类SVM。其中对于某一类的SVM来说,正样本是proposal和ground-truth的框IOU大于0.3的(交叉验证得到的),其余视为负样本;
- (Bounding-box regression)这里原图没有画出,其实在检测这里既有对proposal进行分类,再有对proposal的中心点和宽和高这四个值进行回归的过程,当然这个regressor的参数是训练拿到的。
什么是 IoU?
IoU (intersection-over-union)是用于评价目标检测(Object Detection)的评价函数,模型简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。即检测结果(DetectionResult)与 Ground Truth 的交集比上它们的并集,即为检测的准确率 IoU :
I o U = D R ∩ G T D R ∪ G T IoU = \frac{DR\cap GT}{DR \cup GT} IoU=DR∪GTDR∩GT
其中DR=Detection Result ,GT = Ground Truth。
或者写成如下的公式:可以看到 IoU 的值越大,表明模型的准确度越好,IoU = 1 的时候 DR 与 GT 重合。
在此过程中,RCNN作者预训练CNN,之后又用任务数据去fine-tune网络,最后把CNN作为特征提取器给SVM。同样展示了CNN的强大特征提取能力。说到这里不得不提pre-train和fine-tune。
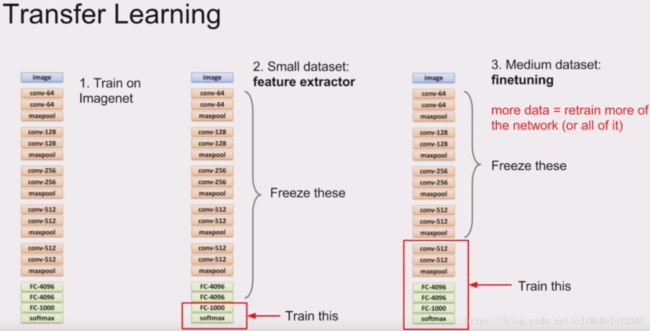
VGGNet 6组实验中的后面几组中用到了pre-train后的A模型的部分层作为网络初始化的参数。上图是AlexNet作者在16年的深度学习暑期学校时候课上的一页PPT。可以看出三种针对不同数据量级而选择的训练策略。之前做过的几次Kaggle比赛中,使用pre-trained model 和 train-from-scratch 拿到的性能结果差距不小. Alex讲到,对于在ImageNet上训练过的pre-trained model,其参数可以用来初始化别的任务:
- 数据量小的新任务。可以把前面的大部分层参数freeze,保留前面的卷积层和部分卷积层,以获取在ImageNet上得到的提取特征的能力,作为特征提取器,而只训练最后一层的全连接层。
- 数据量中等的新任务。则需要更多的可变的层来拟合新任务的数据,freeze前面的层,留出更多的层去拟合新数据。
但实际来说,什么是小和大往往没有定量的描述,我觉得还是需要根据pretrain模型时的数据和新问题的数据之间的多样性复杂程度来评估,只是说,可finetune的层数越多,可以拟合新数据的分布的参数越多,这一个观点。但若是认真去解决问题且时间充裕,需要把所有可能都尝试到。
“浅层学到的是纹理特征,而深层学到的是语义特征”,这句话是从某篇博文看到的,我认为网络层数在特征提取这里,单从可视化的角度来讲,如果是线性模型对学出的权重矩阵进行可视化,那么得到的是对应各类别图像的轮廓,这是CS231n课程有讲到的。然而上图是对GoogLeNet这一网络的特征图可视化的结果,可以看到浅层学到的是边缘(Edges)、纹理(Texture)等,深层学到的是更偏向语义的信息,相当于把原本线性模型的feature map拉长了。本质还是那么多信息,只是中间的过程更加清晰可见,看上图中最后一组6张图中第一列放大的图,有建筑物的特征,而且颜色偏蓝,应该是训练数据中该类的图像大多有云朵和天空作为建筑物的背景。
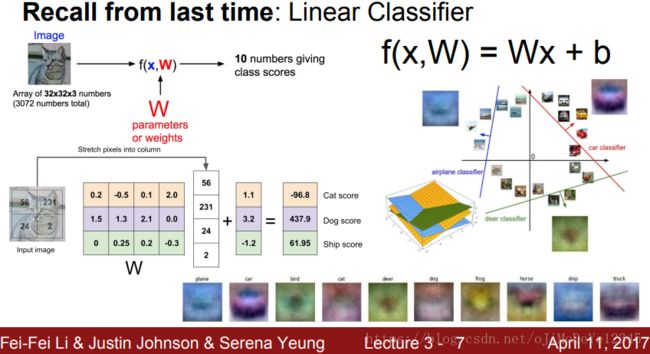
不过可以发现,无论网络深浅,最后一层(或几层)总是对应类别的轮廓,即语义信息。

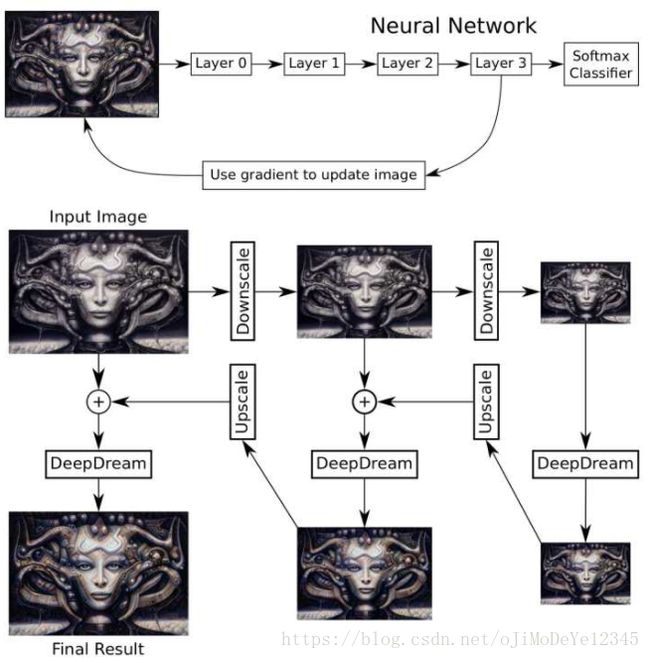
根据优化的目标不同,得到的可视化结果不同,如DeepDream就是对feature
map的结果backprop回去更新输入图像进行可视化(该过程的流程如下图,该图来自zhihu的一篇博客见参考部分。关于可视化这里我没有仔细看,需要结合Feature
Visualization这篇文章、Google Blog上关于DeepDream的两篇文章以及风格迁移学习那篇文章再深入分析)。
1.1.2 在其它数据集上的泛化性
作者通过在ImageNet预训练得到的模型,在其他小数据(VOC-2007、VOC-2012、Caltech-101、Caltech-256等图像分类任务)上发现优秀的泛化性能(这部分来自本篇文章附录 Localization 的 Generation of Very Deep Features),作者说到使用pre-trained模型,再在自己的小数据上训练不容易过拟合,关于这点我的理解是:
-
一开始在量级大且多样性广的数据集(如ImageNet)上pre-train,不严谨地说,新问题的小数据只是当初pre-train时所用数据集的一个子集,换句话说,pre-trained模型的参数已经避开了用小数据train-from-scratch的一些局部最优;
-
一开始在足够大的数据上pre-train,模型已经见识过了广阔的样本空间,这会带来了更广阔和丰富的特征空间,因而模型在小数据上学习时不会太过纠结于比较片面或者偏斜的样本带来的影响(还是类似第一点,初始化足够好)。
总而言之:事半功倍,pre-trained模型用于fine-tune前已经趟(略,或者说exploit)过了很多坑(局部最优),因而效果好。另外,作者还使用不同尺度跑网络的方式提取到多组特征,对它们做平均的方法来表示最终给分类器的特征,这样相比将特征直接concate,不会导致最终特征太多(inflating,或者说是膨胀)。另外,作者发现使用multi-scale训练模型时,如果尺度范围比较小(256,384,512,640,768和256,384,512 两种 multi-scale相比)提升的性能比较有限(0.3%)。
x i , j ′ = x i , j ∑ i = 0 h e i g h t − 1 ∑ j = 0 w i d t h − 1 x i , j 2 x^{\prime}_{i,j}=\frac{x_{i,j}}{\sqrt{\sum^{height−1}_{i=0}\sum ^{width−1}_{j=0}x^2_{i,j}}} xi,j′=∑i=0height−1∑j=0width−1xi,j2xi,j
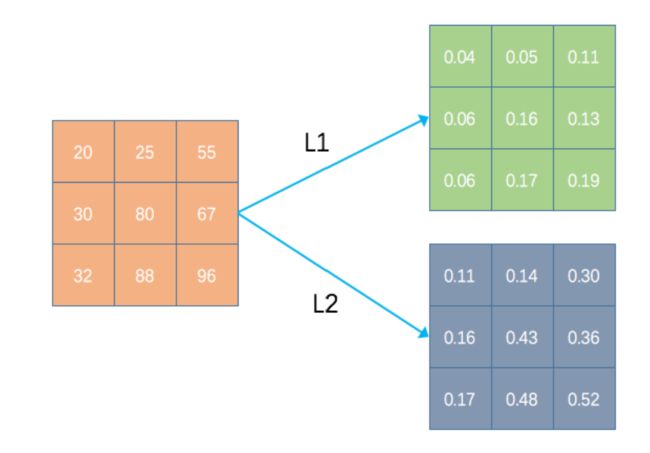
图像中的 L1-normalize 与 L2-normalize
论文的附录部分也提到了图像的 L2-normalize,此 L2 并不是 CNN 中提到的用于解决过拟合的正则化方法,那么图像中的L2-normalize 有指呢?
L1及其 L2的计算公式如下:
L 1 → x i , j ′ = x i , j ∑ i = 0 h e i g h t − 1 ∑ j = 0 w i d t h − 1 x i , j 2 L 2 → x i , j ′ = x i , j ∑ i = 0 h e i g h t − 1 ∑ j = 0 w i d t h − 1 x i , j 2 L1 \rightarrow x^{\prime}_{i,j}=\frac{x_{i,j}}{\sum^{height−1}_{i=0}\sum ^{width−1}_{j=0}x^2_{i,j}}\\ L2 \rightarrow x^{\prime}_{i,j}=\frac{x_{i,j}}{\sqrt{\sum^{height−1}_{i=0}\sum ^{width−1}_{j=0}x^2_{i,j}}} L1→xi,j′=∑i=0height−1∑j=0width−1xi,j2xi,jL2→xi,j′=∑i=0height−1∑j=0width−1xi,j2xi,j
其中 x i , j ′ x^{\prime}_{i,j} xi,j′表示经过 L1或者 L2的值,H 表示图片的高(Height),W 表示宽(Width), x i , j x_{i,j} xi,j表示图像第 i行 j 列的像素值。如一个 3×3 的图像,使用 L1与 L2的结果如下图:
作者在使用pre-trained模型的时候,是把用于喂给softmax前、产生1000维的最后一层全连接层去掉,使用倒数第二个全连接层产生聚合了位置和尺度的4096维图像特征,将这个特征做L2-normalization(上面公式便是图像上位于第 i 行 j 列的像素点 x i , j ′ x^{\prime}_{i,j} xi,j′经过L2-norm后的像素值 x i , j ′ x^{\prime}_{i,j} xi,j′,需要注意的是这里是图像处理中 L2-normalize)后给SVM分类器训练 1VsALL 模型,提取特征的CNN没有做fine-tune操作。作者用倒数第二层的4096维的特征的考量是这个维度一定程度聚合了multiple location 和 scale 的信息,我觉得这个说法还是有些道理,一是网络有三个全连接层,经过1个或者2个全连接,原本的带有位置的局部信息被聚合起来了,但是 4096 维度的数目这个超参数还可以进一步使用交叉验证来优化,此外作者使用的是第二个fc后的特征,也不妨试试第一个fc后的特征、或者最后一个卷积的特征、甚至是将这些拼起来,说不定效果会更好。

此外,作者在对CNN提取到的特征做了聚合和一些变换,作者对4096维的resulting feature map(也就是刚做过l2-normalize过程的)再做global average pooling 产生一样维度的输出,并将与之镜像的图片也做同样的过程,最后将二者的特征加和求平均。当然全局平均池化(global average pooling,Network In Network有介绍该方法和dropout在作用上都起到正则作用,但有两个特点:1. 让feature map与类别通过softmax时的计算更自然,feature map也即对应类别的置信度分数;2. 无参数的策略,避免了过拟合问题。更多的参考上图NIN的截图)是一种聚合方法,作者也说到还可以使用stacking到一起,我想应该类似concate。
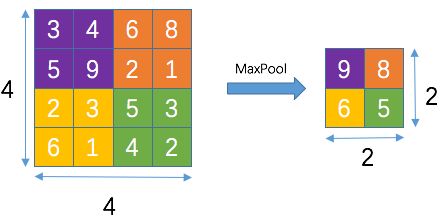
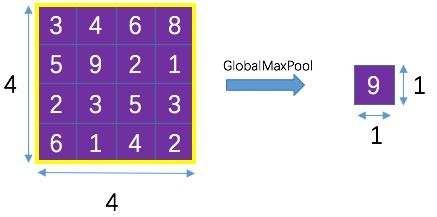
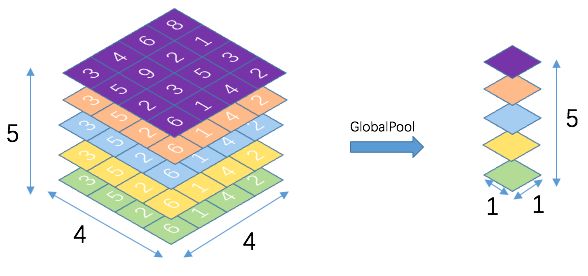
什么是 全局池化(Global Average Pooling)
此概念首先在 NIN(Network In Network) 中提出。
首先,需要知道什么是全局池化(global pooling),它其实指的滑动窗口的大小与整个 feature map 的大小一样,这样一整张feature map 只产生一个值。比如一个 4×4 的 feature map 使用传统的池化方法(2×2 + 2s),那么最终产生的 feature map 大小为 2×2 ,如下图:
而如果使用全局池化的话(4×4 + 1s,大小与 feature map 相同),一个feature map 只产生一个值,即输出为 1×1,如下图:
如果前一层有多个feature map 的话,只需要把经过全局池化的结果堆叠起来即可,如下图:
上图,如果使用 Average 池化方法,那么就成为 Global Average Pooling,即 GAP。
从而可以总结出,如果输入 feature map 为 W×H×C,那么经过全局池化之后的输出就为 1×1×C。
2 卷积网络配置
2.1 VGG结构
VGG的网络结构图
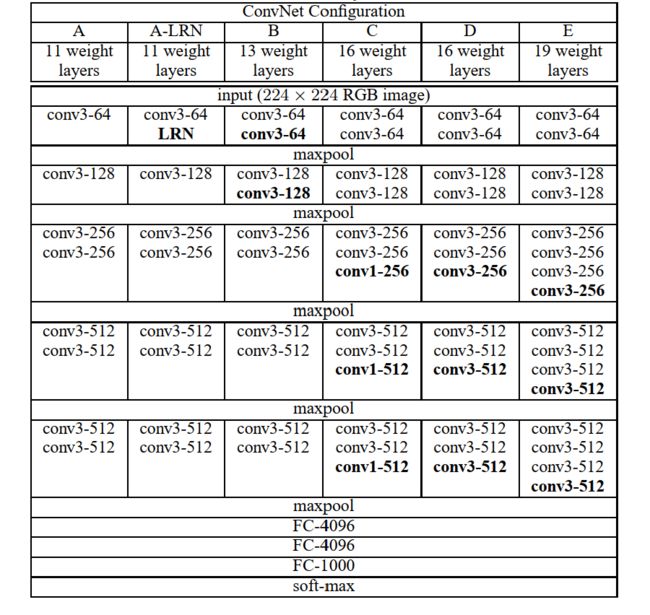
由上图所知,VGG一共有五段卷积,每段卷积之后紧接着最大池化层,作者一共实验了6种网络结构。分别是VGG-11,VGG-13,VGG-16,VGG-19,网络的输入是 224 × 224 224\times 224 224×224大小的图像,输出是图像分类结果(本文只针对网络在图像分类任务上,图像定位任务上暂不做分析)
A-LRN 增加了 LRN 层,但在评估的时候可以看到 LRN (Local Response Normalisation)层并没有起到多大的作用,文章认为 LRN 并没有提升模型在 ILSVRC 数据集上的表现,反而增加了内存消耗和计算时间。
模型 C 和 D 的层数一样,但 C 层使用了 1×1 的卷积核,用于对输入的线性转换,增加非线性决策函数,而不影响卷积层的接受视野。后面的评估阶段也有证明,使用增加的 1×1 卷积核不如添加 3×3 的卷积核。
池化层的核数变小且为偶数,AlexNet 使用的是3×3 stride 为 2,VGG 为2×2 stride 也是 2 。CS231n 课程也提到现在使用 pooling 越来越少了,而是使用 stride 不等于 1 的卷积层来替代。
全连接层形式上完全平移AlexNet的最后三层,超参数上只有最后一层fc有变化:bias的初始值,由AlexNet的0变为0.1,该层初始化高斯分布的标准差,由AlexNet的0.01变为0.005。
超参数的变化,我的理解是,作者自己的感性理解指导认为,我以贡献bias来降低标准差,相当于标准差和bias间trade-off,或许作者实验validate发现这个值比之前AlexNet设置的(std=0.01,bias=0)要更好
输入大小为 224×224 RGB 三通道,输入只做了减去 RGB 均值的操作。
VGG16网络结构
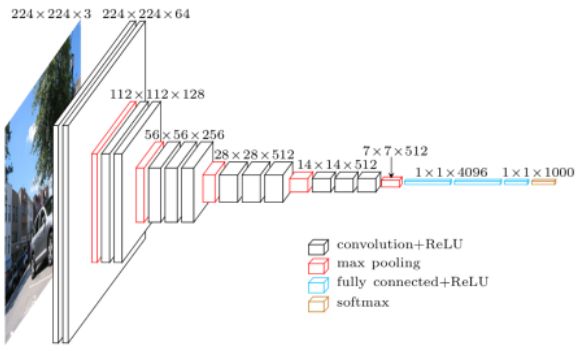
- VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5),ZFNet中的较大卷积核(7x7)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层ReLU可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
- AlexNet虽然也有用3×3的卷积核,而且是大规模用,但基本上都是在网络的中后期。一开始却用了11×11这样的大卷积核,需要注意该卷积核对应的stride为4。我的理解是,一开始原图的尺寸虽然很大很冗余,但最为原始的纹理细节的特征变化一开始就用大卷积核尽早捕捉到比较好,后面的更深的层数害怕会丢失掉较大局部范围内的特征相关性,因为后面更多是3×3这样的小卷积核(和一个5×5卷积)
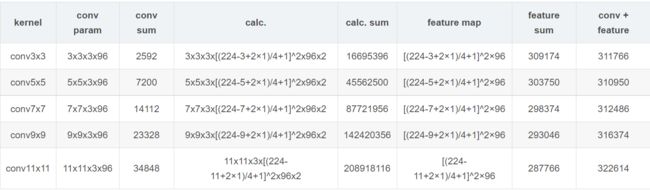
- 对于11×11的kernel size而言,中间有很大的重叠,计算出的3×3区域每个值很过于受到周边像素的影响,每个位置卷积的结果会更多考虑周边局部的像素点,原始的特征多少有被平滑掉的感觉。换句话说,局部信息因为过大的重叠,会造成更多细节信息的丢失。那大卷积核,是否带来更大的参数和feature map大小呢?我计算了同样conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB图上(设置pad=1,stride=4,output_channel=96)做卷积,卷积层的参数规模和得到的feature map的大小:
- 看来大卷积核带来的参数量并不大(卷积核参数+卷积后的feature map参数,不同kernel大小这二者加和都是30万的参数量),即使考虑AlexNet中有两种形式的卷机组([conv-relu]-lrn-pool和[conv-relu]-[conv-relu]-[conv-relu]-pool)。实际增大的是计算量(上面我列出了计算量的公式,最后要乘以2,代表乘加操作)。为了尽可能证一致,我这里所有卷积核使用的stride均为4,可以看到,conv3x3、conv5x5、conv7x7、conv9x9、conv11x11的计算规模依次为:1600万,4500万,1.4亿、2亿,这种规模下的卷积,虽然参数量增长不大,但是计算量是恐怖的。
- 简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
使得网络容量更大(关于model capacity,AlexNet的作者认为可以用模型的深度和宽度来控制capacity),对于不同类别的区分能力更强(此外,从模型压缩角度也是要摒弃7×7,用更少的参数获得更深更宽的网络,也一定程度代表着模型容量,后人也认为更深更宽比矮胖的网络好)
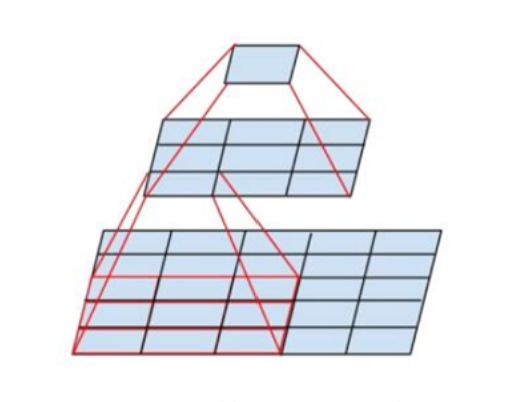
- conv filter的参数减少。比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3 × 9 × C 2 3\times 9\times C^2 3×9×C2,如果直接使用7x7卷积核,其参数总量为 49 × C 2 49\times C^2 49×C2 ,这里 C指的是输入和输出的通道数。很明显, 27 × C 2 27\times C^2 27×C2小于 49 × C 2 49\times C^2 49×C2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
2.2 网络参数

INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
3 分类框架
3.1 训练阶段
VGG采用了带动量的最小批梯度下降算法(min-batch gradient descent with momentum)去优化优化多项式逻辑回归(multinomial logistic regression objective),参数如下:
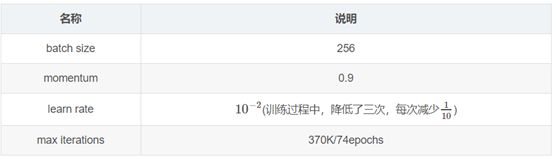
VGG 训练之所以可以收敛的比 AlexNet 快,是因为:
a)正则化+小卷积核,
b)特定层的预初始化
- 正则化方法:
-
增加了对权重的正则化 5 × 1 0 − 4 ∣ ∣ w ∣ ∣ L 2 5\times 10^{-4}||w||_{L^2} 5×10−4∣∣w∣∣L2
-
对FC层进行Dropout正则化,dropout ratio=0.5
说明:虽然模型的参数和深度相比AlexNet有了很大的增加,但是模型的训练迭代次数却要求更少。
- 初始化策略:
- 首先,随机初始化网络结构A(A的深度较浅),利用A的网络参数,给其他的模型进行初始化(初始化前4层卷积+全连接层,其他的层采用正态分布随机初始化, m e a n = 0 , v a r = 1 0 − 2 , b i a s e s = 0 mean=0,var=10^{−2}, biases = 0 mean=0,var=10−2,biases=0)
- 最后证明,即使随机初始化所有的层,模型也能训练的很好
训练输入:
-
采用随机裁剪的方式,获取固定大小224x224的输入图像。并且采用了随机水平镜像和随机平移图像通道来丰富数据。
-
Training image size: 令S是各向同性重新缩放的训练图像的最小侧,从中截取ConvNet的输入(我们也将S称为训练尺度)。当裁剪尺寸固定为224x224时,原则上S可以取不小于224的任何值:对于S=224来说,裁剪将会捕获整个的图像统计数据,将会完整横跨训练图像的最小边。对于S ≫ 224,裁剪将会对应于图像的一小部分,包括一个小对象,或者对象的一部分。
训练尺寸S
我们考虑两种方法来设置训练尺寸S。
- 第一种就是固定S,这对应于单一尺寸的训练。固定:S = 256(Krizhevsky et al., 2012; Zeiler & Fergus, 2013; Sermanet et al., 2014)和S = 384。给定ConvNet配置,我们首先使用S = 256训练网络。为了加速S=384网络的训练,使用S=256预训练的权重初始化训练,并且我们使用了较小的初始学习率 1 0 − 3 10^{-3} 10−3。
- 第二种是多尺度训练,其中通过从某个范围[Smin, Smax](设置Smin=256,Smax=512)随机采样S来单独地重新缩放每个训练图像。出于速度上的考虑,我们通过微调具有相同配置的单尺度模型的所有层来训练多尺度模型,用固定的S = 384来预训练。
3.2 测试阶段
首先将图片同质化的缩放( isotropically rescaled)为预定义的最小图片边长,记做 Q。Q 不一定要和训练时的尺寸 S 相等。
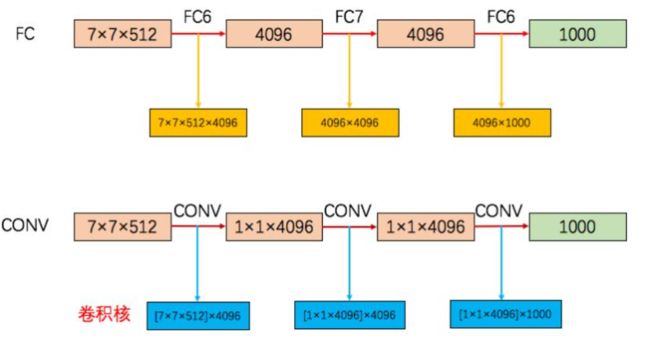
作者将三个全连接层在此阶段,转成了1个7×7,和 2 个 1×1 的卷积层。从图2 VGG16结构图中就可以看到,以第一个全连接层为例,要转卷积层,FC6的输入是 7×7×512,输出是4096(也可以看做 1×1×4096),那么就要对输入在尺寸上(宽高)降维(从7×7 讲到 1×1)和深度(channel 或者 depth)升维(从512 升到4096)。把7×7降到1×1,使用大小为 7×7的卷积核就好了,卷积核个数设置为4096,即卷积核为7×7×4096(下图中的[7×7×512]×4096 表示有 4096 个 [7×7×512] 这样的卷积核,7×7×4096 是简写形式忽略了输入的深度),经过对输入卷积就得到了最终的 1×1×4096 大小的 feature map。经过转换的网络就没有了全连接层,这样网络就可以接受任意尺寸的输入,而不是像之前之能输入固定大小的输入。转化如下图:
4 分类实验
单一尺度评估
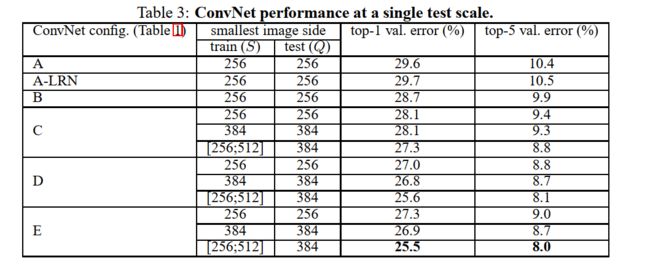
结论:
- 使用局部响应归一化(A-LRN网络)在没有任何归一化层的模型A上没有提升;
- 分类误差随着ConvNet的深度的增加而减小:从A中的11层到E中的19层;
- 训练时候的尺度抖动(S∈[256,512])比在具有固定最小边(S=256或S=384)的图像上训练产生明显的更好的结果;
多尺度评估
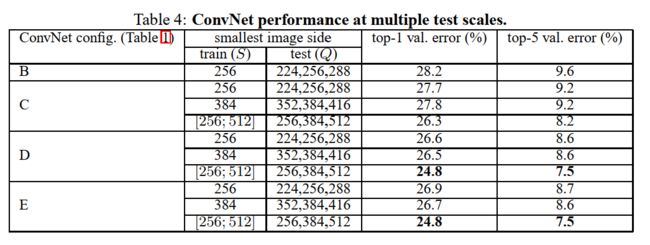
结论:
- 结果表明测试时候的尺度抖动会导致更好的性能
- 尺度抖动的训练比用固定最小边S训练效果要好
多尺度裁剪
结论:
- 使用多种剪裁表现要略好于密集评估;
- 并且这两种方法确实是互补的,因为它们的结合优于他们中的每一种;
在VGG网络中dense evaluation 与multi-crop evaluation
两种预测方法的区别以及效果
方法1: multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均;
方法2: densely, 利用FCN的思想,将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积,这样最后可以得出一个预测的score map,再对结果求平均;
上述两种方法分析
Szegedy et al.在2014年得出multi-crops相对于FCN效果要好;
multi-crops相当于对于dense evaluatio的补充,原因在于,两者在边界的处理方式不同:multi-crop相当于padding补充0值,而dense evaluation相当于padding补充了相邻的像素值,并且增大了感受野;
multi-crop存在重复计算带来的效率的问题;
ConvNet融合
结论:多种模型进行融合,效果更好
与现有技术的比较
结论:与其它模型相比,VGG效果也很好
5 Pytorch实现
import torch
import torch.nn as nn
import torchvision
def Conv3x3BNReLU(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
class VGGNet(nn.Module):
def __init__(self, block_nums,num_classes=1000):
super(VGGNet, self).__init__()
self.stage1 = self._make_layers(in_channels=3, out_channels=64, block_num=block_nums[0])
self.stage2 = self._make_layers(in_channels=64, out_channels=128, block_num=block_nums[1])
self.stage3 = self._make_layers(in_channels=128, out_channels=256, block_num=block_nums[2])
self.stage4 = self._make_layers(in_channels=256, out_channels=512, block_num=block_nums[3])
self.stage5 = self._make_layers(in_channels=512, out_channels=512, block_num=block_nums[4])
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7,out_features=4096),
nn.Dropout(p=0.2),
nn.Linear(in_features=4096, out_features=4096),
nn.Dropout(p=0.2),
nn.Linear(in_features=4096, out_features=num_classes)
)
self._init_params()
def _make_layers(self, in_channels, out_channels, block_num):
layers = []
layers.append(Conv3x3BNReLU(in_channels,out_channels))
for i in range(1,block_num):
layers.append(Conv3x3BNReLU(out_channels,out_channels))
layers.append(nn.MaxPool2d(kernel_size=2,stride=2, ceil_mode=False))
return nn.Sequential(*layers)
def _init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = x.view(x.size(0),-1)
out = self.classifier(x)
return out
def VGG16():
block_nums = [2, 2, 3, 3, 3]
model = VGGNet(block_nums)
return model
def VGG19():
block_nums = [2, 2, 4, 4, 4]
model = VGGNet(block_nums)
return model
if __name__ == '__main__':
model = VGG16()
print(model)
input = torch.randn(1,3,224,224)
out = model(input)
print(out.shape)
参考:
- 2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
- 《Very Deep Convolutional Networks for Large-Scale Image Recognition》
- VGG网络结构分析
- 一文读懂VGG网络
- CS231n Convolutional Neural Networks for Visual Recognition
- VGG 论文阅读记录
- ILSVRC-2014 presentation
- Convolutional neural networks on the iPhone with VGGNet
- Lecture 9:CNN Architectures
- VGG网络中测试时为什么全链接改成卷积? – 知乎
- Convolutional Neural Networks - Basics
- 在VGG网络中dense evaluation 与multi-crop evaluation两种预测方法的区别以及效果
- StackOverflow - What does global pooling do?
- Feature Visualization
- VGG ILSVRC 16 layers