100天精通Python(数据分析篇)——第75天:Pandas数据预处理之数据标准化
文章目录
- 专栏导读
- 1. 数据标准化是什么?
- 2. 数据标准化的作用
- 3. 数据标准化的方法
- 4. 离差标准化
- 5. 标准差标准化
- 6. 小数定标标准化
专栏导读
作者介绍:Python领域优质创作者、CSDN/华为云/阿里云/掘金/知乎等平台专家博主
- 本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进千人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!


1. 数据标准化是什么?
数据标准化是 企业或组织对数据的定义、组织、监督和保护进行标准化的过程。数据标准化分为开发(D)、候选(C)、批准(A)驳回(R)、归档(X)几个过程。
评价是现代社会各领域的一项经常性的工作,是科学做出管理决策的重要依据。随着人们研究领域的不断扩大,所面临的评价对象日趋复杂,如果仅依据单一指标对事物进行评价往往不尽合理,必须全面地从整体的角度考虑问题,多指标综合评价方法应运而生。所谓多指标综合评价方法,就是把描述评价对象不同方面的多个指标的信息综合起来,并得到一个综合指标,由此对评价对象做一个整体上的评判,并进行横向或纵向比较。
而在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
2. 数据标准化的作用
数据归一化可以提升模型收敛速度,加快梯度下降求解速度,提升模型精度,消除量纲得影响,简化计算。
- 提升模型精度:标准化 / 归一化使不同维度的特征在数值上更具比较性,提高分类器的准确性。
- 提升收敛速度:对于线性模型,数据归一化使梯度下降过程更加平缓,更易正确的收敛到最优解。
1、数据的量纲不同;数量级差别很大。
经过标准化处理后,原始数据转化为无量纲化指标测评值,各指标值处于同一数量级别,可进行综合测评分析。
如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。
2、避免数值问题:太大的数会引发数值问题。
3、平衡各特征的贡献。
3. 数据标准化的方法
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
常用计算公式如下:
- 离差标准化

- 标准差标准化
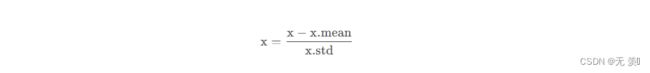
- 小数定标标准化

4. 离差标准化
min-max标准化(别名:离差标准化),离差标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间 [0,1] 中的值x’,其公式为:
中文解读:
新数据 =(原数据-最小值)/(最大值-最小值)
实战代码:
```cpp
import numpy as np
import pandas as pd
def minmaxscale(data):
"""自定义离差标准化函数"""
data = (data - data.min()) / (data.max() - data.min())
return data
df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list('ABCD'))
print("标准化前:")
print(df)
print()
print("标准化后:")
new_df = minmaxscale(df)
print(new_df)
运行结果:

结果分析:通过离差标准化前后的对比,可以发现原先数值与映射的值相对应。第0行所有列都变成了0.0,第1行都变成了0.5,第2行都变成了1.0。
优点分析:可以把指标按比例缩放成0和1之间的数
缺点分析:
- 当数据的极差过大时,离差标准化趋于0;
- 当数据发生更改后要重新确定[min,max]范围,以免引起系统报错。
适用范围:0-1标准化适用于需要将数据简单地变换映射到某一区间中进行比较,观测数据的分布情况.
注意事项:
- 当 max= min 没有意义
- min / max 是否为异常值
5. 标准差标准化
z-score 标准化(别名:标准差标准化),这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。通过该方法处理的数据均值为0,标准差为1。其公式为:
中文解读:
新数据=(原数据-均值)/标准差
实战代码:
import numpy as np
import pandas as pd
def StandardScaler(data):
"""自定义标准差标准化函数"""
data = (data - data.mean()) / data.std()
return data
df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list('ABCD'))
print("标准化前:")
print(df)
print()
print("标准化后:")
new_df = StandardScaler(df)
print(new_df)
运行结果:

结果分析:通过对比可以发现,标准差标准化后的数值区间不限于[0,1],还会存在负值,同时保留了数据的分布情况。
优点分析:经过处理的数据符合正态分布,均值为0,标准差为1;对于样本多的数据比较稳定;不改变原始数据的分布,各个指标对目标函数的影响权重不变。
缺点分析:需要计算数据整体的平均值和方差,而且结果没有实际意义,只是用于比较。
适用范围:适用于数据系列中最大值和最小值未知,有超出取值范围的离群数据的情况。或者是数据分布非常离散的情况。
6. 小数定标标准化
小数定标标准化是通过移动数据的小数位数,将数据映射到[-1,1]区间上,移动的小数位数取决于数据绝对值的最大值。其公式为:
中文解读:
新数据 = 原数据 / 最大绝对值的位数
实战代码:
import numpy as np
import pandas as pd
def DecimalScaler(data):
"""自定义小数定标标准化函数"""
data = data / 10 ** (np.ceil(np.log10(data.abs().max())))
return data
df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=list('ABCD'))
print("标准化前:")
print(df)
print()
print("标准化后:")
new_df = DecimalScaler(df)
print(new_df)
运行结果:

优点分析:
- 操作简单,同时使得归一化之后的数据都落在一个很小的区间内,量级统一,便于数据的分析比较
- 小数定标标准化方法适用范围广,受到数据分布影响小,更加实用
缺点分析:
- 最大值与最小值非常容易受异常点影响
- 鲁棒性较差,只适合传统精确小数据场景.
适用范围:适用于数据系列分布比较离散,尤其是数据系列遍布多个数量级的情况