编程语言测试综述
文章目录
- 0 引言
- 1 编程语言基础设施概述
- 2 编程语言测试的难点
- 3 编程语言测试的技术
-
- 3.1 编译器测试技术
-
- 3.1.1 学术界对编译器的测试
- 3.1.2 工业界对编译器的测试
- 3.2 标准库测试技术
- 3.3 其他部分的测试
- 4 编程语言测试的挑战
- 5 总结
- 参考文献
0 引言
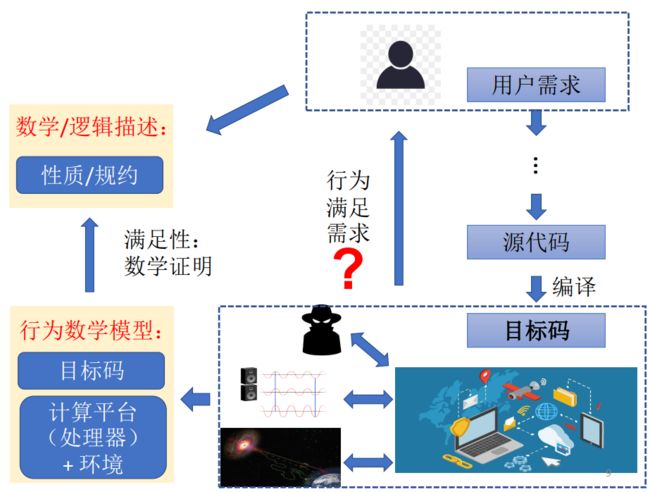
编程语言作为构建一切软件的基础,被誉为系统软件“皇冠上的明珠”,而作为保障编程语言基础设施质量的测试技术则是让这颗明珠持续闪亮的“聚光灯”。随着现代编程语言的兴起,编程语言基础设施测试涵盖的组件也越来越多,不仅包含传统的编译器测试,同时还包含语言标准库、运行时、调试器、程序分析工具、构建工具、部署工具、IDE 等一系列语言组件的测试,如何保证质量,甚至是 10 倍质量,成为构建一套语言基础设施的难点,更成为一款商用编程语言的核心竞争力。
本文从编程语言及其基础设施的概念出发,结合工程化过程中遇到的测试难点,分别从学术界和工业界的角度,对编译器、标准库及其它工具链组件的测试技术做了重点介绍,最后总结了编程语言测试技术面临的机会和挑战。
如果您想要了解更多编程语言相关的测试技术,请记得持续关注我们哟!也非常欢迎您加入我们的编程语言技术社区SIG-编程语言测试小组,和我们一起深入探索编程语言测试技术。
加入方式:文末有小助手微信,添加并备注加入SIG-编程语言测试。
1 编程语言基础设施概述
如果说语言是人类进行沟通和交流的表达方式,凝聚了人类文明的千年历史。那么编程语言作为人机对话所必须的具有共同处理规则的沟通指令,则代表了一代又一代计算机科学家智慧的结晶。1946 年 2 月 14 日,世界上第一台通用计算机“ENIAC”在美国宾夕法尼亚大学诞生。迄今在通用计算机上,至少诞生了超过上千种的编程语言。这些编程语言因其设计的初衷和需要解决的问题不同,而具备了不同的语言特性及编程方式 [1]。
在旧约故事里,上帝将巴别塔建造者们的语言打乱,让他们再也不能明白对方的意思,并把他们分散到了世界各地。同物种间的跨语言沟通尚且需要翻译,更何况是跨物种的人机交互。

若要避免人机对话陷入 “鸡同鸭讲” 的尴尬,就必须依赖 “编译器” 或“解释器”将程序员编写的 “命题作文” 翻译成计算机所能识别并执行的二进制指令。而翻译时所遵守的规则即是语言规范。语言规范定义了标准化符号的组合规则、约束以及它们所需要执行的操作指令。每种编程语言都有自己的语言规范,且会随着语言特性的演进而持续演进。例如 C 语言规范包括有 C89、C99 标准等。
语言规范通常都是对语言的完整描述,但语言规范有时候并不会规定所有的内容。在《The Java® Language Specification》中并没有规定 GC(garbage collector)采用的具体算法。因此在实现的时候就可以采用 Mark-Sweep 或者其他的算法。对于同一种编程语言,可以有不同的实现。例如,对于 C 语言,有开源的 GCC 编译器,还有基于 LLVM 的 clang 编译器。
Java、C/C++、Python、Swift 等用户层面的编程语言被作为高级语言为大众所了解。每种高级语言都有其对应的编译器或者解释器。程序员使用高级语言进行编码大致需要经过 4 个步骤:编辑-编译-调试-执行,才能最终得到一段预期的可执行程序。为了支撑完成上述步骤,多数厂家都会提供相应的集成开发环境,即 IDE(Integrated Development Environment),例如微软的 Visual Studio,苹果的 Xcode 等,还有支持 Java 开发的 IDE 包括 IntelliJ IDEA 和 Eclipse 等。
IDE 通常包括编辑器、编译器、调试器在内的完整的开发环境。其中编辑器是程序员会交互最多的模块,它会提供包括工程管理、文件管理、字符编辑、字体设置、自动联想、智能化代码推荐、查找、替换、重构等功能,帮助程序员完成程序的编辑。IDE 通常还会提供对应的调试器,调试器的功能会包含有单步调试、查看变量、修改变量等,从而帮助程序员减少 bug。为了便于程序的开发,尤其是在嵌入式领域,部分 IDE 还会提供仿真器,这样即使在没有真实硬件的条件下,也可以进行程序的开发。
为了进行程序开发,每种编程语言都会提供丰富的库函数。例如:网络服务与通信、数据的压缩与解压、多媒体的音视频处理、数学库、并发库、密码服务、通用的操作系统服务、GUI 库等等。这些库通常会满足各个领域不同的开发要求。
除了库函数以外,一般的 IDE 还会提供一些辅助性的编程工具。部署工具、代码格式化工具、静态检查工具、包管理工具、性能调优工具。
编程语言的开发者为了推广语言,一般都会为程序员提供语言参考(Language Reference)、编程指南 (Programming Guide) 或者 tutorial,针对不同的国家,可能还会有不同语言, 来加快程序员对语言的学习。也会通过 IDE 提供在线的升级的功能,来加快新版本的推广。为了扩大语言的使用范围,编程语言一般都会发布多个操作系统的版本,支持 Windows/Linux 等多个操作系统。
综上所述,编程语言的基础设施不仅仅包括语言规范,还包括编译器、调试器、仿真器在内的 IDE,以及标准库和一些辅助性工具的完整工具链。
2 编程语言测试的难点
通常编程语言规范都比较复杂,拿 C 语言举例,其规范文档当前已超过 700 页,语言规范的复杂性给程序员的阅读和理解都带来了很大的困难。语言规范的语法部分通常会采用 BNF(Backus–Naur form)[2] 来描述。作为一种描述编程语言语法的体系,BNF 保证了语法部分通过了形式化的论证,但编程语言的语义部分并无保证。因此通常来说,编程语言的规范更多的是采用自然语言描述,规范的写作人员和阅读人员,对于规范的理解可能存在个体性偏差,从而给编程语言的测试带来困难。
编程语言的测试从实现角度来说也非常困难。仅从编译器的架构来看,一个编译器的实现可能会包含多个前端和多个后端。截止 2019 年,GCC 编译器的代码行数就已经达到了 1500 万行 [3],支持的后端多达 50 多种 [4],这对编程语言的测试也带来了很大的挑战。
编程语言的生存周期也都很长,例如,C 语言诞生于 1972 年,至今已经有接近 40 年的历史。发展至今,C 语言的实现都会保证向后兼容。想要验证 1500 万行代码是否正确的实现了 700 页的文档描述的内容,其实是非常困难的。虽然在语言规范中通常不会包含很多对编译优化的描述,但在实际的编程语言测试中,通常会把对编译器的功能验证看做对语言规范一致性的验证。
编程语言的标准库涉及的内容非常广泛,例如:网络通信会涉及协议,密码服务会涉及安全,数学库会涉及精度,通用的操作系统服务会涉及跨平台的实现,数据的压缩和解压会涉及算法。因此,对于语言标准库的测试会涵盖计算机领域各个方面的大量知识,造成测试的难度与广度,以及对多个领域的掌握要求会非常高。
由于大多数编程语言的实现会支持多个操作系统,因此会涉及到多个平台的安装、升级、一致性等的测试,以及多个版本的兼容性测试、IDE 集成及用户体验测试、用户手册的资料测试等,还会包含性能测试、交互测试、集成测试等等。
这里笔者尽量全面地罗列了编程语言测试相关的内容,但对语言的测试来说,重点仍然是编译器和标准库相关的测试。
3 编程语言测试的技术
3.1 编译器测试技术
3.1.1 学术界对编译器的测试
近十年来,来自不同国家的专家、学者在编译器测试领域开展了广泛的研究。从大连理工江贺教授 [5] 团队的研究数据 [6] 可见,编译器测试相关的论文数量比例按照国家、地区排序,中国处于第四位,远落后于排名第一的美国,但其中论文作者中,华人占比较高, 详情见图 1。

各个专家的研究成果在编译器社区得到了充分实践。2016 年 LLVM 3.9 的 release notes [7] 中,还专门对 Zhendong Su [8] 老师表达了谢意,对其通过使用 Fuzz 工具发现多个普通工具难以测到的 LLVM 编译器 bug 表示感谢。
学术界发表了比较多编译器测试的论文,根据陈俊洁 [9] 团队的研究 [10],编译器测试的研究可以分为如下图展示的几个方面。
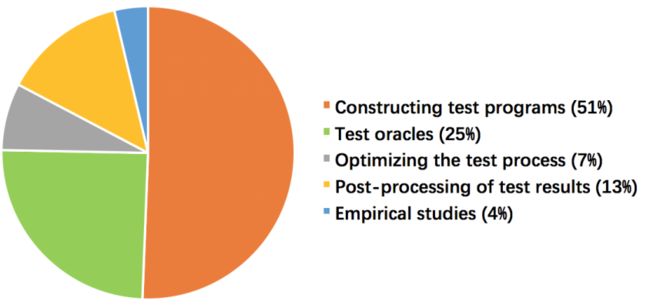
下面将简要介绍几种常见的编译器测试技术。
- 测试用例生成技术
对于编译器测试,比较知名的测试用例生成技术有 Csmith [11] 和 YARPGen [12] 等。下面简单介绍一下 Csmith 的实现原理。
Csmith 基于随机组合的方式生成 C 程序。
Csmith 生成的 C 程序能够支持绝大多数的 C 语法,并对生成的程序有些安全保障机制,能够保证生成的程序根据 C 语言标准有单一明确的含义,避免生成的程序有未定义行为和未指定的行为。
Csmith 基于差异测试 (differential testing) 来判断用例是否发现 BUG。
差异测试如下图所示。差异测试最终对比的是程序的运行结果,那如何获取程序的运行结果呢?Csmith 的方法是将程序中所有的全局变量放入一个缓冲区,获取该缓冲区中数据的 CRC 校验码作为程序的运行结果。比较 CRC 校验码就相当于比较两个程序的运行结果。

Csmith 生成的 C 程序的随机性体现在以下几个方面: - 数据结构的随机性
- 数据结构初始值的随机性
- 程序结构的随机性
每一个由 Csmith 生成的程序都可以被分割为三个部分:
- 包含对全局变量的 CRC 校验及首函数调用的 main 函数
- 内容随机的首函数
- 内容随机的被首函数调用的函数
这种以函数为粒度的程序块在生成时其实是作为 “BLOCK” 来划分的。而每一个函数的 “BLOCK” 中包含了若干条 Statement,即语句。Statement 的分解如下图所示:
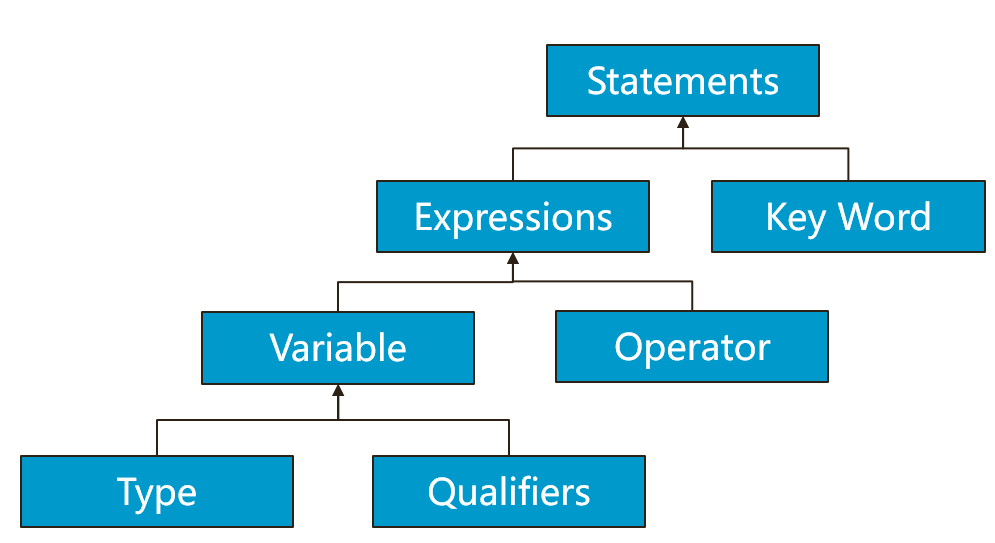
Statement 类型多样,但大致上可以被分为控制流相关的 Statement 和数据流相关的 Statement。前者主要包括了 if-else、for、break、continue 等控制流语句,后者主要为赋值语句,当然也包括函数调用等。
通过差异测试(differential testing),Csmith 解决了判断用例 PASS 或者 FAIL 的问题。但如果没有其他的编译器做参考对比,Csmith 发现 bug 的效果可能就会有一定的损失。实际情况中,如果真的没有其他的编译器作参考,可以通过对比打开优化和关闭优化的运行结果,但如果两者同时存在错误,这种 bug 利用上述方法就很难发现了。
Csmith 是基于语法的测试用例生成技术,除了这种技术外,还有基于 IR(Intermediate Representation)的用例生成技术。举个例子,SRCIROR [13] 是基于 LLVM IR 变异生成测试用例的技术。
当前还出现了基于人工智能生成测试用例的技术,例如 DeepFuzz [14] 基于 LTSM(Long Short-Term Memory)神经网络生成测试用例。其生成用例的流程如下图所示。
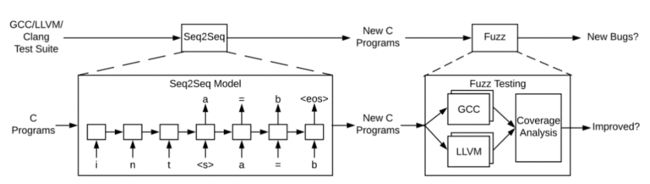
总之测试用例的生成技术和方法还是很多的,也是业界研究的重点领域。
- 编译器测试的 Test oracle
Test Oracle [15] 是指判断测试用例 PASS 或者 FAIL 的准则。可以使用 EMI (Equivalence Modulo Inputs)[16] 解决 Csmith 在 Test Oracle 方面的缺陷。
EMI 是一种可以利用已经存在的测试用例来生成新测试用例的技术。举例来说:
对于程序 P,如果存在程序 Q,当 P 和 Q 的功能相同时,经过同一个编译器编译后,P 和 Q 的运行结果应该一致,如果不一致,就说明编译器存在 bug。通过 P 找到 Q 的过程就是一个构造测试输入的过程。
对于已经存在的程序 P,通过代码覆盖率工具(例如 Gcov [17])可以得到程序 P 的运行轨迹。其中有些代码针对当前特定的输入是不执行的(但这不是真正的死代码)。针对这部分不执行的代码可以进行删除、修改甚至可以添加部分 “无用” 的代码,这样的做法对程序的运行结果是没有影响的,但可以得到一个新程序。通过这个办法就可以得到与程序 P 的功能相同的程序 Q。程序 Q 就是我们要构造的程序。具体的构造过程可以参考下图。

针对不执行的代码,可以有很多的策略生成新的程序 Q。例如,不执行的代码有很多的基本块(即 Basic Block),可以随机删除不同的基本块,按照不同的组合策略进行删除,这样就可以生成很多的新程序。
根据先前的描述,由于 P 和 Q 的功能相同,因此编译后的运行结果可以直接作对比,如果结果不一致,则意味着存在 bug。这样也不需要一个额外的编译器作为参考对象,解决了差异测试需要多个编译器做参考的缺点。 - 测试用例裁剪技术
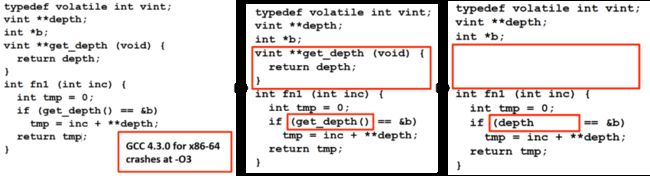
用例裁剪技术,其目的就是通过剪裁使发现 bug 的用例尽量简短,从而提高问题的定位效率。常见的工具有 C-Reduce [18] 和 Perses [19]。C-Reduce 的实现原理如下图所示:

C-Reduce 定义了一些 plugin,相当于是用例裁剪的一些规则。对于当前失败的用例应用 plugin 进行用例裁剪,如果没有触发 bug,则丢弃该 plugin,重新对用例应用另一个 plugin。如果触发了 bug,则把裁剪后的用例作为新的用例,重新应用 plugin。如此往复,直至用例不能裁剪。
下面列举一些 plugin 的裁剪规则:- C-specific peephole passes
- –x^=y -> x=y
- -while(…) -> if (…)
- –x ? y : z -> y
- …
- Remove chunks of text,like Delta
- Some non-local transformations
- C/C++ -specific plugins including
- Inline a function call
- Un-nest nested function calls
- Make function return void
- Reduce array dimension or pointer level
- …
- C-specific peephole passes
下图是 C-Reduce 用例裁剪的一个基本过程,持续应用 plugin 规则,就可能达到一个比较小规模的测试用例。经过裁剪后的代码明显代码行数变少而且变得简单。
- 编译器的形式化验证
软件测试无法证明系统不存在缺陷,也不能证明它一定正确。对于要求高可靠的编译器,通过测试并不能保证其可靠性。因此需要通过形式化验证 [20],使用数学建模的方法,从理论上证明代码是符合需求的。业界比较知名的形式化验证的编译器是 CompCert 编译器。形式化验证的流程如下图 9 所示 [21]。
除了形式化验证的编译器,还有对编译器的窥孔优化(Peephole Optimization)进行证明的工具 - Alive [22]。
Alive 项目信息请参考:https://github.com/nunoplopes/alive
学术界的很多工具和方法因其有效性,而被工业界认可,进而被购买和收购。典型案例:GraphicsFuzz [23] 工具是由英国帝国理工的 ALASTAIR F. DONALDSON 教授 [24] 的团队开发,用于 GPU 编译器测试的用例生成工具.由于发现 bug 的效果非常好,后来被 Google GPU 编译器团队收购。
工业界与学术界在编译器测试领域也展开广泛的合作。例如 Intel 公司与 Utah 大学开展合作开发了 YARPGen 工具 [12],这个工具在 GCC、LLVM 和 Intel C++ Compiler 测试中发现超过 220 个 bug,也取得了很好的效果。
学术界的技术成果在工业界得到了广泛的应用,但事实上工业界关注的重点与学术界也略有不同。
3.1.2 工业界对编译器的测试
商业公司一般都会编译器进行标准测试,例如某个 C 语言编译器是否满足 C99 标准。也会有相应的公司提供相应的测试用例,例如针对是否满足 C89/C99 标准, ACE 公司有 SuperTest 测试套 [25],PlumHall 公司有 C & C++ Validation Test Suites 测试套 [26]。针对是否满足 Java 语言规范和 Java 虚拟机规范,Oracle 公司有 JCK(Java Compatibility Kit)测试套 [27]。
商业公司更注重工程实践,一般都会建立自己的 CodeDB(Code Database),针对特定客户,会建立符合用户特征的代码库。在得到用户同意的情况下,也可以直接使用用户的代码,同时也会将大量的开源代码引入到 CodeDB,用以保证编译器的质量。商业公司也会引入大量的通用 benchmark 用于编译器的性能测试,例如 SPEC-Int [28]、EEMBC [29] 等,针对特定用户建立定制的 benchmark,进行性能测试。
商业公司需要做端到端的系统级验证,需要对编辑器、编译器、调试器做交互测试和集成测试。同时还需要做资料测试、易用性测试和可服务性测试等等。商业公司针对产品发布的各个操作系统平台,需要做兼容性测试和安装测试。不同的商业公司,都会制定自己的商业发布标准,只有在满足该要求后才能发布相应的产品。
商业公司通过一系列的标准测试、性能测试、兼容性测试等一系列的测试才能构建起完整的测试体系,使最终发布的产品质量可控。因此工业界的测试更加关注测试体系的完整性。
虽然近十年来,学术界和工业界都对编译器测试贡献了许多的工具和方法,使相关测试技术有了长足的进步。但编译器测试仍然存在着巨大的挑战。
3.2 标准库测试技术
关于库的测试,学术界主要的关注点是安全问题、系统漏洞以及覆盖率的提高,常见的测试有符号执行、模糊测试技术。
符号执行与模糊测试在业界已经广泛应用,这两种技术都具有一定的优缺点 [30]:
符号执行可以生成复杂条件分支的测试用例,但在符号化执行过程中往往会出现路径爆炸问题;
模糊测试随机变异生成测试用例,可以覆盖到较深的分支,但很难通过变异的方法生成复杂条件分支的测试用例。
符号执行 [31] 通过符号化执行程序来收集约束条件, 并借助约束求解器为每条路径生成测试用例,大致原理如下图所示。
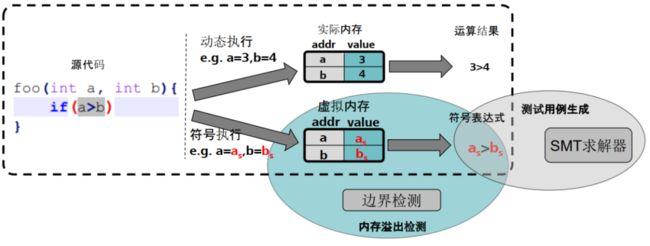
符号执行技术包括了利用符号值进行模拟执行的全套环境,核心部分为指令处理和虚拟内存模型,附加组件是考虑实际应用而添加的功能,例如路径管理,约束求解,缺陷检测机制等等。
例如,对如下的程序 [32] 通过约束求解器可以得到所有的 x,y 的值,详情见下图。
printf(int twice(int v) {
return 2*v;
}
void testme(int x, int y) {
z = twice(y);
if (z==x) {
if (x > y+10) {
ERROR;
}
}
}
/* simple driver exercising testme() with sym inputs */
int main() {
x = sym_input();
y = sym_input();
testme(x, y);
return 0;
}"hello world!");

常见的符号执行工具有 KLEE [33] 和 S2E [34]。
符号执行的优势是能够较少的测试用例达到高测试覆盖率,但当代码非常复杂时,由于存在路径爆炸问题,因此很难覆盖到较深的分支。
是一种通过向目标系统提供非预期的输入并监视异常结果来发现软件漏洞的方法。模糊测试的工具有很多,例如对图像,多媒体,压缩数据进行模糊测试的 AFL(American Fuzzy Lop)。
AFL [35] 是由 Google 的安全工程师 Michał Zalewski 开发的一款基于覆盖率引导(Coverage-guided) 的模糊测试工具。AFL 通过编译时插桩和遗传算法自动生成新的测试用例。AFL 通过插桩记录代码覆盖率,不断对输入进行变异,当代码的覆盖率提高时,再保留用例。具体的执行过程如下:
- 选择一个种子输入,加入到输入队列
- 选择输入队列中的一个元素作为输入,按照某种策略进行变异
- 将变异后的测试用例传递给被测对象,通过插桩工具记录覆盖
- 判断覆盖率是否增加,如果增加,将该用例加入到输入队列。否则从输入队列取下一个输入
- 重复 2-4
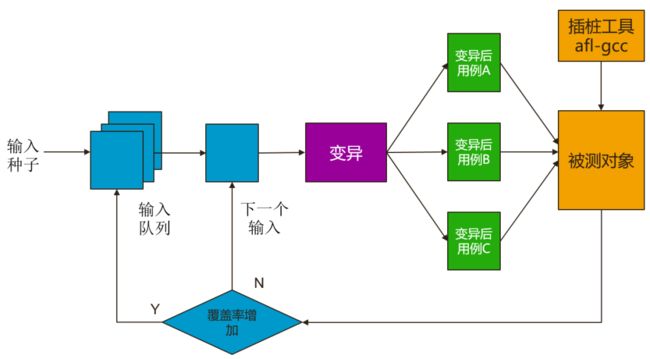
无论是符号执行还是模糊测试,最终判断测试用例是否 PASS 的标准都是程序是否 crash。如果 crash 就说明用例 Fail,否则就是 PASS。这导致符号执行和 Fuzz 测试更多的用于安全测试,或者发掘系统漏洞,相对功能测试的能力比较弱。
对于标准库的功能测试,更多的仍然是人工手写用例的方式完成测试。因为标准库非常多,而且更多的是通过手写用例完成测试,因此非常的耗费人力。
3.3 其他部分的测试
当前的编辑器除了传统的编辑功能如文件管理和字体设置外,一般还会引入人工智能相关的功能,例如智能化的代码推荐(比如基于 Transformer-XL 模型 [36] 完成代码推荐),因此需要对这些用到的人工智能模型完成测试。
除了前面的内容,一般还会调试器的测试。对于发布的用户指南等文档需要进行资料测试,针对 IDE 进行用户体验测试。对于多个操作系统的版本进行兼容性测试和安装测试,以及前后版本的兼容性测试。
总之对于编程语言的测试是一个复杂系统的测试,虽然学术界,工业界虽然都做出了很多努力,但仍然充满很多的挑战。
4 编程语言测试的挑战
如何综合评价编程语言?
当前针对编程语言的综合评估比较少。当前的工具更多的是针对编译器,尤其是优化测试的比较多,而针对编程语言综合评估其实比较少。例如从性能、可读性、代码的书写效率、安全性以及商业因素等等多个方面去评估编程语言。导致一个编程语言能够被广泛使用的因素有哪些,各个因素起了什么作用。
库函数的功能测试?
库函数涉及的内容非常广泛,而当前常用的工具和方法更多的是针对安全测试和漏洞挖掘。因此功能测试更多的是通过人工写用例的方式完成。而人工写用例的方式需要耗费大量的人力。
如何 “更方便” 地生成 “更好” 的测试用例?
针对测试用例的生成,具体的挑战表现为如下 3 个问题。
针对不同的语言,如何快速开发一个用例生成工具?
由于 Csmith 发现的 bug 的效率很高,因此其他的编程语言也希望开发类似的工具,但开发这样的工具是也需要一定的工作量,Csmith 有 30K 的代码量。当前除了类似 Csmith 直接在代码中描述语法语义外,还有一些其他的用例生成技术。DeepFuzz 基于神经网络生成测试用例,但这需要有训练的过程。Xsmith [37] 是一个能够支撑多个编程语言开发用例生成工具的框架。但 Xsmith 是基于 Racket 语言开发的,学习 Racket 语言又引入了一定的学习成本。因此如何能够快速开发一个高质量的用例生成工具对于企业来说还是很重要的。
如何生成指定优化或者满足用户代码特征的用例?
当前的用例生成工具,更多的是一个 Fuzz 工具,往往没有什么具体的指向性。但实际的测试人员往往都是针对某一个具体的优化进行测试,导致在实际的工作中,迭代内的测试并不能直接使用用例生成工具。
如何从大量失败用例中,快速地对 bug 进行定位和分类?
Bug 的快速定位,具体的挑战是 Fail 用例的去重与优先级排序。由于 Csmith 类似的工具是随机生成的测试用例,一旦 bug 很多时,可能会有一部分用例是重复的,多人分析用例的时候往往会重复,造成人力的浪费。在修复 bug 的时候,有些 bug 对用户可能影响大,有些影响小,希望能够对 Fail 的用例进行排序,优先解决影响大的 Fail 用例。
5 总结
对编程语言的测试会用到很多的测试用例生成技术,还涉及符号执行技术、Fuzz 测试技术以及人工智能技术(应用 LSTM 神经网络生成测试用例,即 Test By AI;也有针对 Transformer-XL 模型的测试,即 Test for AI)、同时也会涉及到用例裁剪等编译器技术、IDE 的用户体验测试等。因此编程语言测试是一个综合的、系统的测试技术,需要学术界和工业界共同努力,才能保证编程语言的质量。
参考文献
-
Programming language - Wikipedia: https://en.wikipedia.org/wiki/Programming_language
-
Backus–Naur form - Wikipedia: https://en.wikipedia.org/wiki/Backus–Naur_form
-
GNU Compiler Collection - Wikipedia: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
-
Status of Supported Architectures from Maintainers’ Point of View - GNU Project - Free Software Foundation (FSF): https://gcc.gnu.org/backends.html
-
江贺: http://oscar-lab.org/people/~hjiang/index_chn.htm
-
Compiler testing: a systematic literature analysis. Y Tang, Z Ren, W Kong, H Jiang, 2019
-
LLVM 3.9 Release: https://lists.llvm.org/pipermail/llvm-announce/2016-September/000070.html
-
Professor Zhendong Su’s Homepage: https://people.inf.ethz.ch/suz/
-
JunjieChen: https://sites.google.com/site/junjiechen08/
-
A Survey of Compiler Testing. J Chen, J Patra, M Pradel, Y Xiong, H Zhang, D Hao, L Zhang, 2020
-
Finding and understanding bugs in C compilers. X Yang, Y Chen, E Eide, J Regehr, 2012. In Proceedings of the 2011 ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2011.
-
Random testing for C and C++ compilers with YARPGen. V Livinskii, D Babokin, J Regehr, 2020
-
SRCIROR: A Toolset for Mutation Testing of C Source Code and LLVM Intermediate Representation. Farah Hariri, August Shi, 2018
-
DeepFuzz: Automatic Generation of Syntax Valid C Programs for Fuzz Testing. Xiao Liu, Xiaoting Li, Rupesh Prajapati, Dinghao Wu
-
Test oracle - Wikipedia: https://en.wikipedia.org/wiki/Test_oracle
-
Compiler validation via equivalence modulo inputs. V. Le, M. Afshari, and Z. Su. In Proceedings of the 2014 ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2014
-
Gcov Intro (Using the GNU Compiler Collection (GCC))
https://gcc.gnu.org/onlinedocs/gcc/Gcov-Intro.html#Gcov-Intro -
Test-Case Reduction for C Compiler Bugs. John Regehr, Yang Chen, Pascal Cuoq,Eric Eide, Chucky Ellison, Xuejun Yang.
-
Perses:Syntax-Guided Program Reduction. Chengnian Sun, Yuanbo Li, Qirun Zhang, Tianxiao Gu, Zhendong Su.
-
Formal verification - Wikipedia: https://en.wikipedia.org/wiki/Formal_verification
-
形式化程序验证和可信软件. 冯新宇
-
Provably Correct Peephole Optimizations with Alive. Nuno P. Lopes, David Menendez, Santosh Nagarakatte, John Regehr
-
Automated Testing of Graphics Shader Compilers. ALASTAIR F. DONALDSON,HUGUES EVRARD, ANDREI LASCU, PAUL THOMSON.
-
Professor Alastair Donaldson: https://www.imperial.ac.uk/people/alastair.donaldson
-
SuperTest http://www.ace.nl/compiler/supertest-compiler-test-and-validation-suite
-
Plum Hall, Inc. - C and C++ Validation Test Suites
http://www.plumhall.com/suites.html -
Gaining Access to the JCK https://openjdk.java.net/groups/conformance/JckAccess/
-
SPEC Benchmarks https://www.spec.org/benchmarks.html
-
EMBC https://www.eembc.org/
-
基于符号执行与模糊测试的混合测试方法. 谢肖飞, 李晓红.
-
符号执行测试自动生成技术原理及应用. 丁国富.
-
Symbolic Execution for Software Testing: Three Decades Later. Cristian Cadar, Koushik Sen
-
KLEE https://klee.github.io/
-
S2E http://s2e.systems/docs/#
-
APL https://github.com/google/AFL
-
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
-
Xsmith https://www.flux.utah.edu/project/xsmith
