ARM neon详解
NEON 学习参考文档:
ARM NEON优化(一)——NEON简介及基本架构 - Orchid Blog http://zyddora.github.io/2016/02/28/neon_1/
http://zyddora.github.io/2016/02/28/neon_1/
neon intrinsics函数
Intrinsics – Arm Developerhttps://developer.arm.com/architectures/instruction-sets/intrinsics/
三大主流芯片架构
1、ARM 2、MIPS 3、x86
编译器自动向量化,往往发挥不了neon的最佳性能,这时候可能需要你借组内联的Neon Intrinsics(arm_neon.h提供),甚至嵌套neon的汇编指令来进行优化
1、neon简述
NEON是指适用于Arm Cortex-A系列处理器的一种高级SIMD(单指令多数据)扩展指令集。NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成)。Single Instruction Multiple Data (SIMD)顾名思义就是“一条指令处理多个数据(一般是以2为底的指数数量)”的并行处理技术
NEON 指令可执行并行数据处理:
个人理解 neon就是通过对arm内部的一些特有寄存器做运算操作,以便能加速运算
2、Arm 高级SIMD发展历史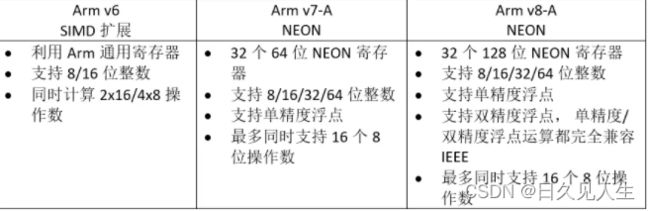
3、 为什么要用NEON
(1)支持整数和浮点操作,以确保适合从编解码器、高性能计算到 3D 图形等广泛应用领域。
(2)与 Arm处理器紧密结合,提供指令流和内存的统一视图,编程比外部硬件加速器更简单。
4、NEON指令格式
NEON寄存器:
- 16×128-bit寄存器(Q0-Q15);
- 或32×64-bit寄存器(D0-D31)
- 或上述寄存器的组合。
- ps每一个Q0-Q15寄存器映射到一对D寄存器
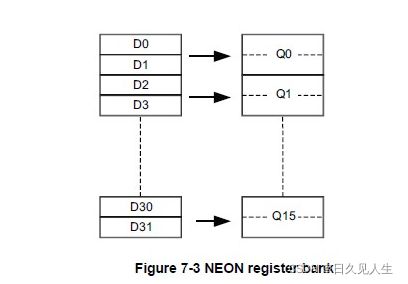
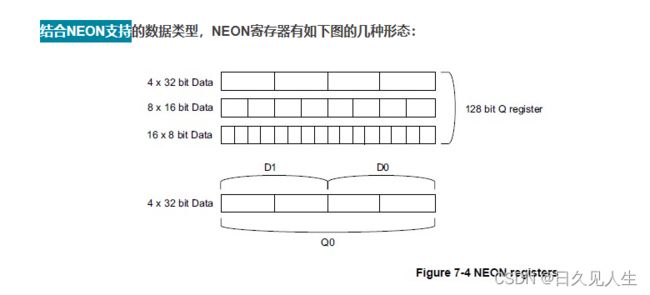
Q寄存器是虚的实际不在存在
数据处理指令类别:
(1)Long instructions
操作双字vectors,生成四倍长字vectors 结果的宽度一般比操作数加倍,同类型 在指令中加L
(2) Wide instructions
操作双字 + 四倍长字,生成四倍长字 结果和第一个操作数都是第二个操作数的两倍宽度 在指令中加W
(3)Narrow instructions
操作四倍长字,生成双字 结果宽度一般是操作数的一半 在指令中加N
数据类型表示:
(u)int8x8_t;
(u)int8x16_t;
(u)int16x4_t;
(u)int16x8_t;
(u)int32x2_t;
(u)int32x4_t;
(u)int64x1_t;
其中,第一个数字代表的是数据类型宽度为8/16/32/64位,第二个数字代表的是一个寄存器中该类型数据的数量。如int16x8_t代表16位有符号数,寄存器中共有8个数据 ,
为什么 数据类型为64 ,因为本来 寄存器大小 16个 128bit 寄存器, 映射处理后变为 32 * 64bit
参考示例
int16x8_t vqaddq_s16 (int16x8_t, int16x8_t)
int16x4_t vqadd_s16 (int16x4_t, int16x4_t)
第一个字母'v'指明是vector向量指令,也就是NEON指令;
第二个字母'q'指明是饱和指令,即后续的加法结果会自动饱和;
第三个字段'add'指明是加法指令;
第四个字段'q'指明操作寄存器宽度,为'q'时操作QWORD, 为128位;未指明时操作寄存器为DWORD,为64位;
第五个字段's16'指明操作的基本单元为有符号16位整数,其最大表示范围为-32768 ~ 32767;
形参和返回值类型约定与C语言一致。
其它可能用到的助记符包括:
l 长指令,数据扩展
w 宽指令,数据对齐
n 窄指令, 数据压缩
指令格式
V{
<.dt> - Data type, such as s8, u8, f32 etc.
注: {} 表示可选的参数。
VADD.I16 D0, D1, D2 @ 16位加法 VMLAL.S16 Q2, D8, D9 @ 有符号16位乘加
5、 NEON编程基础
现在我们可以开始使用NEON开始加速我们的应用了。使用NEON 技术通常有下列四种方式:
- 调用NEON优化过的库函数
- 使用编译器自动矢量化选项
- 使用NEON intrinsics指令
- 手写NEON汇编
(1)调用库函数
用户只需要在程序中直接调用NEON优化过的库函数就可以了,简单易用。目前你有下列库可以选择:
Arm Compute library
一系列经过Arm CPU和GPU优化过的底层函数库。用于图像处理、机器学习和计算机视觉。更多信息: https://developer.Arm.com/technologies/compute-library
Ne10开源库
由Arm主导开发的,目前提供了比较通用的数学函数,部分图像处理函数,以及FFT函数。Project Ne10: An Open Optimized Software Library Project for the Arm Architecture @ GitHubhttp://projectne10.github.io/Ne10/
PS arm 平台 系列处理器说明 其中 ARM CORTEX-A系列对应 ARMV7 参考如下
ARM平台处理器简介-ARMv7_WangMark的专栏-CSDN博客_armv7https://blog.csdn.net/petib_wangwei/article/details/40187207
(2)使用编译器自动矢量化选项
如 gcc 编译加上 参数 -mfpu=neon -mcpu
(3)使用NEON intrinsics指令
见下面实际应用参考中描述
(4) 手写NEON汇编
实际除非对汇编很了解,否则一般开发比较少用,实际intrinsics函数底层也是调用neon汇编的
6、neon 实际应用参考
(1)C语言__attribute__的使用
__attribute__ 语法格式为:__attribute__ ((attribute-list))
attribute-list 参数为可以设置函数属性(Function Attribute )、变量属性(Variable Attribute )和类型属性(Type Attribute )
其位置约束为:放于声明的尾部“ ;” 之前
关键字__attribute__ 也可以对结构体(struct )或共用体(union )进行属性设置。大致有六个参数值可以被设定,即:aligned, packed, transparent_union, unused, deprecated 和 may_alias 。
在使用__attribute__ 参数时,你也可以在参数的前后都加上“__” (两个下划线),例如,使用__aligned__而不是aligned ,这样,你就可以在相应的头文件里使用它而不用关心头文件里是否有重名的宏定义。
如调用neon作用函数 表示以下函数调用 arm_neon.h Intrinsics函数
__attribute__((target("fpu=neon")))
static void neon_accelator_vector_2_bias(short *input, float *output, float *bias)
{
/*
c code logic
for(int i=0;i<2;i++)
{
float temp = (float)(*(input+i));
*(output+i) = temp*(*bias);
}
*/
int16x4_t input_s16vec0 ;
memset(&input_s16vec0, 0, sizeof(input_s16vec0));
vld1_lane_s16(input,input_s16vec0,0);
input++;
vld1_lane_s16(input,input_s16vec0,1);
int32x4_t input_s32vec0 = vmovl_s16(input_s16vec0);
float32x4_t bias_f32vec = vld1q_f32 (bias);
float32x4_t input_f32vec0 = vcvtq_f32_s32(input_s32vec0);
float32x4_t output_f32vec0= vmulq_f32 (input_f32vec0, bias_f32vec);
vst1q_lane_f32(output,output_f32vec0,0);
output++;
vst1q_lane_f32(output,output_f32vec0,1);
}
(2)使用 arm_neon.h Intrinsics函数 需要加入-mfloat-abi=softfp -mfpu=neon指令
(3)指令函数使用
正常指令:生成大小同样且类型通常与操作数向量同样的结果向量;
Vector add(正常指令): vadd -> ri = ai + bi; r, a, b have equal lane sizes--*/
int8x8_t vadd_s8 (int8x8_t __a, int8x8_t __b);//_mm_add_epi8
int16x4_t vadd_s16 (int16x4_t __a, int16x4_t __b);//_mm_add_epi16
int32x2_t vadd_s32 (int32x2_t __a, int32x2_t __b);//_mm_add_epi32
int64x1_t vadd_s64 (int64x1_t __a, int64x1_t __b);//_mm_add_epi64
长指令:对双字向量操作数运行运算,生成四字向量的结果。所生成的元素通常是操作数元素宽度的两倍
Vector long add(长指令): vaddl -> ri = ai + bi; a, b have equal lane sizes,
result is a 128 bit vector of lanes that are twice the width--*/
int16x8_t vaddl_s8 (int8x8_t __a, int8x8_t __b);
int32x4_t vaddl_s16 (int16x4_t __a, int16x4_t __b);
int64x2_t vaddl_s32 (int32x2_t __a, int32x2_t __b);
uint16x8_t vaddl_u8 (uint8x8_t __a, uint8x8_t __b);
uint32x4_t vaddl_u16 (uint16x4_t __a, uint16x4_t __b);
uint64x2_t vaddl_u32 (uint32x2_t __a, uint32x2_t __b);
并属于同一类型。
宽指令:一个双字向量操作数和一个四字向量操作数运行运算,生成四字向量结果。
vaddw -> ri = ai + bi--*/
int16x8_t vaddw_s8 (int16x8_t __a, int8x8_t __b);
int32x4_t vaddw_s16 (int32x4_t __a, int16x4_t __b);
int64x2_t vaddw_s32 (int64x2_t __a, int32x2_t __b);
uint16x8_t vaddw_u8 (uint16x8_t __a, uint8x8_t __b);
uint32x4_t vaddw_u16 (uint32x4_t __a, uint16x4_t __b);
uint64x2_t vaddw_u32 (uint64x2_t __a, uint32x2_t __b);
窄指令:四字向量Vector rounding halving add: vrhadd -> ri = (ai + bi + 1) >> 1;
shifts each result right one bit, Results are rounded(四舍五入)--*/
int8x8_t vrhadd_s8 (int8x8_t __a, int8x8_t __b);
int16x4_t vrhadd_s16 (int16x4_t __a, int16x4_t __b);
int32x2_t vrhadd_s32 (int32x2_t __a, int32x2_t __b);操作数运行运算,并生成双字向量结果,所生成的元素通常是操作数元素宽度的一半。
饱和指令:当超过数据类型指定的范围则自己主动限制在该范围内。*/
vqadd -> ri = sat(ai + bi);
the results are saturated if they overflow--*/
int8x8_t vqadd_s8 (int8x8_t __a, int8x8_t __b);//_mm_adds_epi8
int16x4_t vqadd_s16 (int16x4_t __a, int16x4_t __b);//_mm_adds_epi16
int32x2_t vqadd_s32 (int32x2_t __a, int32x2_t __b);
int64x1_t vqadd_s64 (int64x1_t __a, int64x1_t __b)
vrhadd -> ri = (ai + bi + 1) >> 1;
vmul -> ri = ai * bi
vmla -> ri = ai + bi * ci
vmlsl -> ri = ai - bi * ci