MySQL(一):B+ Tree,索引以及其优点, 索引实战, 聚簇索引和非聚簇索引, 最左匹配,索引失效
文章目录
- 一、B+ Tree
-
- B+ Tree相比于红黑树的优点
-
- 1. B+树有更低的树高
- 2. B+树更符合磁盘访问原理
- 二、MySQL索引
-
- 2.1 B+ Tree索引
- 2.2 哈希索引
- 2.3 全文索引
- 2.4 空间数据索引
- 三、索引的优点以及什么时候需要使用索引
-
- 什么时候需要使用索引
- 四、索引实战
-
- 建立普通索引
- 建立唯一索引
- 建立主键索引
- 建立联合索引
- 建立全文索引
- 哪些字段适合创建索引
- 五、聚簇索引和非聚簇索引
-
- 在Innodb中,聚簇索引默认就是主键索引。
- 如果表中没有定义主键,那么该表的第一个唯一非空索引被作为聚集索引。
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
- 六、最左匹配原则
- 七、索引失效
-
- 多条件字段中
- <>、NOT、in、not exists
- 查询条件中使用OR 或者 like
- 在索引列上做(计算 / 函数 / 类型转换)
- 索引列使用IS NOT NULL或者IS NULL可能会导致无法使用索引
- 索引列数据类型不匹配
一、B+ Tree
B Tree指的是Balance Tree(平衡树),其是一颗查找树,并且所有叶子结点位于同一层。
B+ Tree是改进版本的B Tree,他不但具有B Tree的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在B+ Tree中,一个节点的key从左到右非递减排列,如果某一个指针的左右相邻key分别是key i 和 key i + 1,且不为null,则该指针指向的节点的所有key大于等于key i且小于等于key i + 1;
如下图所示:
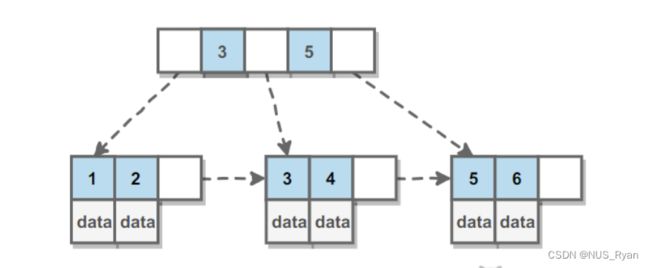
B+ Tree相比于红黑树的优点
红黑树等平衡树也可以用来实现索引,但是文件系统和数据库系统普遍采用B+ Tree作为索引结构,这是因为使用B+ Tree访问磁盘数据有更高的性能。原因如下
1. B+树有更低的树高
平衡树的树高 O(h)=O(logdN),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
2. B+树更符合磁盘访问原理
之前提到了B+树相比红黑树有着更低的树高。
由于B+ 树相对于红黑树有更低的树高,磁盘寻道的次数与树高成正比,在同一个磁盘块上进行访问只需要很短的磁盘旋转时间,所以 B+ 树更适合磁盘数据的读取。
二、MySQL索引
mysql索引就相当于是书的目录。索引的类型有以下几种:
2.1 B+ Tree索引
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
2.2 哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
无法用于排序与分组;
只支持精确查找,无法用于部分查找和范围查找。
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
2.3 全文索引
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
2.4 空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
三、索引的优点以及什么时候需要使用索引
索引的优点如下:
1.大大减少了服务器需要扫描的数据行数。
2.帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
3.将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)
什么时候需要使用索引
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
- 对于中到大型的表,索引就非常有效;
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术
四、索引实战
建立普通索引
ALTER TABLE 'table_name' ADD INDEX index_name ('column');
建立唯一索引
ALTER TABLE 'table_name' ADD UNIQUE INDEX index_name ('column');
建立主键索引
ALTER TABLE 'table_name' ADD PRIMARY INDEX index_name ('column');
建立联合索引
ALTER TABLE 'table_name' ADD INDEX index_name ('column1','COLUMN2','COLUMN3');
建立全文索引
全文索引主要用来匹配字符串文本中的关键字,当需要字符串中是否包含关键字的时候,我们一般用like,如果是以%开头的时候,则无法用到普通索引,这个时候我们就可以使用到全文索引了
ALTER TABLE 'table_name' ADD FULLTEXT ('column');
哪些字段适合创建索引
- 频繁查询的字段
- 在where和on条件中频繁出现的字段
- 区分度高的字段。区分度可以通过下列方式计算:
select
count(distinct birthday)/count(*),
count(distinct gender)/count(*)
from user;
- 有序的字段适合创建。这样有序的字段在插入数据库的过程中,仍然能够保持B+ Tree的索引结构,不需要频繁更新索引文件,性能更佳。
- 应该优先使用联合索引,如果只在age字段创建索引,会先匹配到age=18的三条数据再逐个遍历,效果会更差。同时在使用联合索引时,区分度高的字段应该放在前面。
五、聚簇索引和非聚簇索引
聚集索引(clustered index)和非聚集索引(secondary index,也称辅助索引或普通索引)。这两种索引是按存储方式进行区分的。聚集索引(clustered)也称聚簇索引,这种索引中,数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表的物理顺序只有一种情况,因此对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
详情可以参考下图:
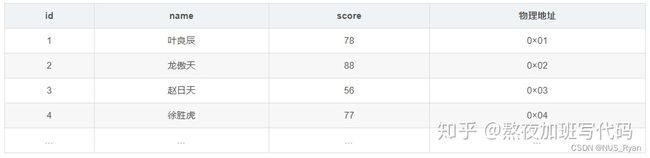
在Innodb中,聚簇索引默认就是主键索引。
如果表中没有定义主键,那么该表的第一个唯一非空索引被作为聚集索引。
如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
六、最左匹配原则
在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
由于构建一棵B+树只能根据一个值来确定索引关系,所以数据库依赖联合索引最左的字段来构建。举例:创建一个(a,b)的联合索引,那么它的索引树就是下图的样子。 可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。但是我们又可发现a在等值的情况下,b值又是按顺序排列的,但是这种顺序是相对的。
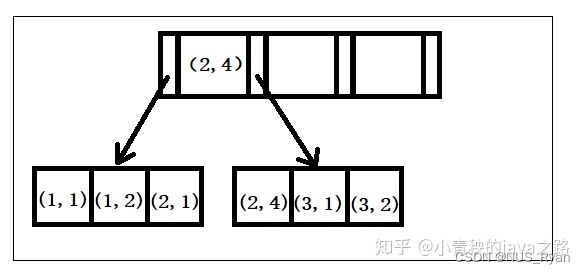
七、索引失效
多条件字段中
-
单字段有索引,WHERE条件使用多字段(含带索引的字段),例如 SELECT * FROM student WHERE name =‘张三’ AND addr = '北京市’语句,如果name有索引而addr没索引,那么SQL语句不会使用索引。
-
多字段索引,违反最佳左前缀原则。例如,student表如果建立了(name,addr,age)这样的索引,WHERE后的第一个查询条件一定要是name,索引才会生效。
<>、NOT、in、not exists
当查询条件为等值或范围查询时,索引可以根据查询条件去找对应的条目。否则,索引定位困难(结合我们查字典的例子去理解),执行计划此时可能更倾向于全表扫描,这类的查询条件有:<>、NOT、in、not exists
查询条件中使用OR 或者 like
- 如果条件中有or,即使其中有条件带索引也不会使用(因此SQL语句中要尽量避免使用OR)
- SQL语句中,使用后置通配符会走索引,例如查询姓张的学生(SELECT * FROM student WHERE name LIKE ‘张%’),而前置通配符(SELECT * FROM student WHERE name LIKE ‘%东’)会导致索引失效而进行全表扫描。
在索引列上做(计算 / 函数 / 类型转换)
以下几种例子会导致索引失效 :
- 在索引列上使用函数:例如select * from student where upper(name)=‘ZHANGFEI’
- 在索引列上计算:例如select * from student where age-1=17;
- 在索引列上使用mysql的内置函数, SELECT * FROM student WHERE create_time
索引列使用IS NOT NULL或者IS NULL可能会导致无法使用索引
索引列数据类型不匹配
如果age字段有索引且类型为字符串,并且在查询的时候让age等于一个整数值,则会索引失效,例如SELECT * FROM student WHERE age=18会导致索引失效