Linux内存管理第三章 -- 页表管理(Page Table Management)
文章目录
- Linux内存管理第三章 -- 页表管理(Page Table Management)
-
- 页目录描述(Describing the Page Directory)
- 页表项描述(Describing a Page Table Entry)
- 如何使用页表项(Using Page Table Entries)
- 转换和设置页表项(Translating and Setting Page Table Entries)
- 分配释放页表(Allocating and Freeing Page Tables)
- 内核页表(Kernel Page Tables)
-
- Bootstrapping阶段
- Finalising阶段
- Mapping addresses to a struct page
-
- Mapping Physical to Virtual Kernel Addresses
- Mapping struct pages to Physical Addresses
- Translation Lookaside Buffer (TLB)
- Level 1 CPU Cache Management
Linux内存管理第三章 – 页表管理(Page Table Management)
页目录描述(Describing the Page Directory)
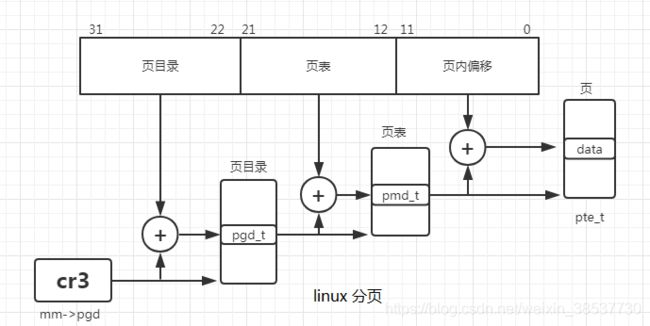
每一个进程都有一个指针指向它自己的PGD(Page Global Directory),PGD是一个物理页框。该页框包含有一组类型为pgd_t的结构。该类型有具体的架构代码中指定。例如在x86下,其定义如下:
typedef struct { unsigned long long pgd; } pgd_t;
typedef struct { unsigned long pte_low, pte_high; } pte_t;
typedef struct { unsigned long long pmd; } pmd_t;
每种架构加载page tables的方式有所不同。例如x86架构下,每个进程的page tables是通过复制mm_struct->pgd到cr3寄存器进行加载的。
- PGD中的每一个active项都对应着一个物理页框,该页框包含一组PMD(Page Middle Directory)其类型为pmd_t。
- PMD对应的又是一个物理页框,PMD页框中时一组PTE(Page Table Entries)其类型为pte_t,
- PTE对应一个物理页框用于存放最终的数据。
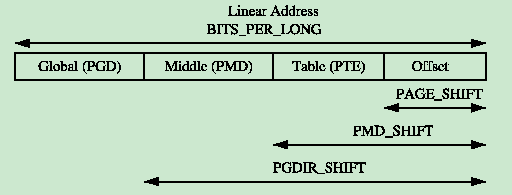
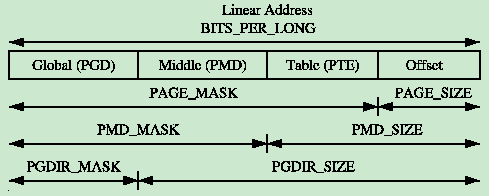
一条线性地址可能被切割为多个部分形成多级页表和页内偏移。为了帮助线性地址的切割,为每一级也表定义了一个宏:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
页表项描述(Describing a Page Table Entry)
如上面所描述,struct pte_t,pmd_t,pgd_t分别描述PTE,PMD,PGD。尽管它们通常是一个非负整数,但是它们仍然被定义成结构体有以下两种原因:
- 为了类型保护,因此避免它们被人不合时宜的误用
- 为了支持x86的PAE功能,因为PAE有多处4个bit来描述大于4GB的memory
从下面的定义来看,分别有两种定义:
#ifdef CONFIG_X86_PAE
extern unsigned long long __supported_pte_mask;
extern int nx_enabled;
typedef struct { unsigned long pte_low, pte_high; } pte_t;
typedef struct { unsigned long long pmd; } pmd_t;
typedef struct { unsigned long long pgd; } pgd_t;
typedef struct { unsigned long long pgprot; } pgprot_t;
#define pte_val(x) ((x).pte_low | ((unsigned long long)(x).pte_high << 32))
#define HPAGE_SHIFT 21
#else
#define nx_enabled 0
typedef struct { unsigned long pte_low; } pte_t;
typedef struct { unsigned long pmd; } pmd_t;
typedef struct { unsigned long pgd; } pgd_t;
typedef struct { unsigned long pgprot; } pgprot_t;
#define boot_pte_t pte_t /* or would you rather have a typedef */
#define pte_val(x) ((x).pte_low)
#define HPAGE_SHIFT 22
#endif
为了类型转换,分别定义了4对宏方便转换:
struct -> uint:pte_val(), pmd_val(), pgd_val() ,pgprot_val()
uint -> struct:__pte(), __pmd(), __pgd() , __pgprot()
宏pgprot_t 是用来存储pte的保护位,一般用来与pte低12位进行比较和设置其值。
pte在x86没有开PAE的case下,其低12位是用来存储保护位标志的:

- Field:
由于一个页框的容量是4KB,所以该物理地址的低12位总是0‘
若此页表结构指向的一个页目录项,则该字段的物理地址对应的物理页框里面的内容是一个页表。
若此页表结构指向的一个页表项,则该字段的物理地址对应的物理页框是一页数据 - Present (P):
-若Present = 1,所指的页在内存中
若Present = 0,所指的页不在内存中.此时该结构中的其他位置可以由操作系统来支配,如果运行的的线性地址对用的页表项的Present = 0,则分页单元会将该线性地址存入寄存器cr2,并产生一个缺页异常:14号异常 - Accessed (A):
分页单元堆相应的页框进行寻址时就设置这个标志.当选中页被交换出去时,该标志位就可以有操作系统来支配.分页单元从不重置这个标志 - Dirty (D):
此标志只用于页表项中,用于标记页框有进行写操作 - Read/Write (R/W):
页或者页表的存取权限 - User/Supervisor (U/S):
页或者页表所需的特权级 - Page Size:
只应用于目录项,若设置为1,则页目录项指的是4MB或者2MB的页框.
如何使用页表项(Using Page Table Entries)
为了遍历页目录,下面三个宏被定义用来将一个线性地址快速分理出其内部组成部分。
- pgd_offset():输入线性地址和mm_struct,返回线性地址中对应的PGD项。
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))
pmd_offset():输入一个PGD项(找到页框地址)和一个线性地址(找到pmd的偏移),返回一个对应的PMD
#define pmd_offset(dir, address) ((pmd_t *) pgd_page(*(dir)) + pmd_index(address))
#define pgd_page(pgd) ((unsigned long) __va(pgd_val(pgd) & PAGE_MASK))
pte_offset_kernel():输入一个PMD(找到页框地址)和一个线性地址(找到页内偏移)
#define pte_offset_kernel(pmd, address) ((pte_t *) pmd_page_kernel(*(pmd)) + pte_index(address))
#define pmd_page_kernel(pmd) ((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))
#define pte_index(address) (((address) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
第二轮的宏函数是用来检查页表项是否存在或者是否有人在使用:
- pte_none(), pmd_none() and pgd_none():如果对应的项不存在,返回1
- pte_present(), pmd_present() and pgd_present():如果对应项的PRESENT为被置位,返回1
- pte_clear(), pmd_clear() and pgd_clear():将会清除对应的项
- pmd_bad() and pgd_bad() :用来检查页表项是否符合要求
上述的几组宏的使用例程:
pgd_t *pgd;
pmd_t *pmd;
pte_t *ptep, pte;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || pgd_bad(*pgd))
goto out;
pmd = pmd_offset(pgd, address);
if (pmd_none(*pmd) || pmd_bad(*pmd))
goto out;
ptep = pte_offset(pmd, address);
if (!ptep)
goto out;
pte = *ptep;
第三轮的宏是用来检查页表项的权限和设置页表项的权限。这些权限决定了一个用户空间的进程在一个page上能干什么不能干什么。举例:内核页表项永远不能被用户进程读取。
- pte_read():用来测试pte的读权限,pte_mkread() 设置读权限,pte_rdprotect()取消读权限
- pte_write():用来测试pte的写权限,pte_mkwrite() 设置读权限,pte_wrprotect()取消读权限
- pte_dirty():用来测试是否有被写过,pte_mkdirty()设置dirty位,pte_mkclean()清除dirty位
- pte_young():用来测试是否是新页,pte_mkyoung()设置新页,pte_old()设置位旧页(检查access位)
转换和设置页表项(Translating and Setting Page Table Entries)
- mk_pte():输入一个struct page和保护位组合形成pte_t。
#define page_to_pfn(page) ((unsigned long)((page) - mem_map)) //mem_map中的偏移就是PFN
#define pfn_pte(pfn, prot) __pte(((pfn) << PAGE_SHIFT) | pgprot_val(prot)) //将PFN与权限bit为合并形成pte_t
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
- set_pte():输入一个PDM页框内的地址,然后将pte_t赋值在这个地址中。
#define set_pte(pteptr, pteval) (*(pteptr) = pteval)
- pte_page():将pte_t转换为struct page
分配释放页表(Allocating and Freeing Page Tables)
- 分配函数: pgd_alloc(), pmd_alloc() and pte_alloc()
- 释放函数:pgd_free(), pmd_free() and pte_free()
内核页表(Kernel Page Tables)
当系统启动时,分页功能还没有启用因为页表不会自己初始化自己。因为每种架构中的具体实现各不相同本文只讨论x86的case。page table的初始化被分为两个阶段:
- bootstrap阶段创建前8MB的页表来开启分页单元。
- Finalising阶段初始化剩余的页表。
Bootstrapping阶段
在文件arch/i386/kernel/head.S中的startup_32()汇编函数负责开启分页单元。一般内核的所有常规代码编译后的内核镜像vmlinuz的起始地址被设置位PAGE_OFFSET + 1MB。而内核实际加载地址是物理内存1MB的位置开始的。从0~1MB这段物理地址通常被某些设备用来个BIOS通信,所以被内核弃之不用。Bootstrapping阶段的代码从虚拟地址转换为物理地址的方法是vaddr - _PAGE_OFFSET,就是直接映射。Bootstrapping阶段要用此方法映射从1MB开始的前8MB物理地址(1MB ~ 9MB)到虚拟地址,直到分页单元被启用。
内核页表初始化从内核编译时静态定义的swapper_pg_dir数组开始,swapper_pg_dir的地址为0x00101000,再建立两页的页表项:pg0,pg1。将swapper_pg_dir中的第0项和第768项设置为pg0的物理地址,第1项和第769项设定为pg1页框的物理地址,swapper_pg_dir中的其他项都填0.这也就是说当分页功能开启的时候,内核无论是用物理地址还是虚拟地址都可以将这两页表映射到正确的page中。其余的页表由paging_init()函数来进行初始化。
一旦临时内核页表映射完成,就会通过设置cr0寄存器的一个bit位来开启分页单元。
Finalising阶段
在此阶段会执行paging_init()函数来执行,其调用流程如下:
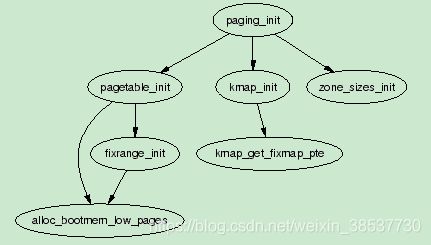
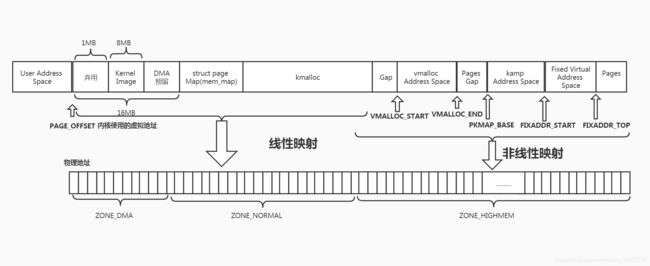
- pagetable_init() 会初始化内核线性映射区间的虚拟地址到物理地址转换所需的页表。此时只创建pmd和pte,并未将每个页框创建相应的struct page,其具体初始化的虚拟地址段如下图所示:

让后再调用page_table_range_init()初始化固定映射区域的内核页表:

一旦pagetable_init()返回,内核空间的所有页表都初始化完成,因此swapper_pg_dir会被加载到cr3寄存器,以此这些页表就可被分页单元使用了。 - kmap_init():将rang_init对应的PTEs加上保护位PAGE_KERNEL
- zone_sizes_init():初始化各个zone,其中最重要的是为每个页框分配struct page,形成mem_map数组。
Mapping addresses to a struct page
Mapping Physical to Virtual Kernel Addresses
从Linux的线性映射我们可以知道物理地址0对应虚拟地址PAGE_OFFSET(3GB),因此任何线性映射区的虚拟地址转换成物理地址的方法就非常简单了,直接将虚拟地址减去PAGE_OFFSET即可。下面来看看内核的实现:
- 虚拟地址 --> 物理地址
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET) //将虚拟地址转换为物理地址 static inline unsigned long virt_to_phys(volatile void * address) { return __pa(address); } - 物理地址 --> 为虚拟地址
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET)) //将物理地址转换为虚拟地址 static inline void * phys_to_virt(unsigned long address) { return __va(address); }
Mapping struct pages to Physical Addresses
从上面的章节我们可以知道kernel image的起始地址是物理地址1MB的地方,然后改物理地址转换成虚拟地址之后就是PAGE_OFFSET + 0x0010000,其后续的一个8MB的地址空间是留给内核的静态代码使用的区域。所以这是不是就预示着第一个可用的虚拟地址就是0xC0800000呢?其实不是如此,Linux尽量将前16MB的虚拟地址留给ZONE_DMA,因此第一个可供内核动态分配可用的虚拟地址是0xC1000000。这也就是全局变量mem_map的地址。ZONE_DMA只有在很必要的情况下使用。
物理地址转换为struct page是通过将物理地址视为mem_map数组的index。将物理地址向右平移PAGE_SHIFT个bit将得到PFN,PFN也是mem_map的index。即 struct *page = mem_map[paddr >> PAGE_SHIFT]
- vaddr -> struct page:
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT)) - struct page -> paddr:
显而易见,通过page的地址就可以知道该page在mem_map中的index,其index就是PFN,然后将其后12位补0,就是物理地址。
至此来总结下Linux的地址模型:
Translation Lookaside Buffer (TLB)
在早期,当处理器需要将虚拟地址映射成物理地址时,它必须扫描所有页目录来搜索需要的PTE。为了避免这种可以想象的消耗,各种不同的硬件架构都给出了一小块内部缓存空间,即提供TLB来缓存虚拟地址到物理地址的转换表。
尽管不是所有架构都有提供TLB,但是Linux内核还是假设所有架构够提供,不能提供的在编译的时候关掉响应的config即可。Linux提供了一些刷新TLB的hook函数:
| void flush_tlb_all(void) |
|---|
| 刷新系统中每一个处理器的整个TLB,这时最昂贵的TLB刷新操作。当该操作完成之后,所有对page tables的修改都变得全局可见。例如当调用vfree()之后就需要刷新整个TLB |
| void flush_tlb_mm(struct mm_struct *mm) |
|---|
| 刷新userspace中和mm_struct相关的整个TLB。在某些架构下,如MIPS,该操作需要对应所有的处理器,但通常是局部的处理器。该操作仅仅是在当整个address space都有影响的case下才执行如:fork的时候复制了整个地址空间或者是删除了所有地址映射 |
| void flush_tlb_range(struct mm_struct *mm, unsigned long start, unsigned long end) |
|---|
| 刷新mm上下文中指定范围内的用户空间的页表。当一个新的region被移动或者被改变时如调用mremap()时调用 |
| void flush_tlb_page(struct vm_area_struct *vma, unsigned long addr) |
|---|
| 该API是用来刷新TLB中的单个page,当一个page产生page fault之后或者是page out之后调用 |
| void flush_tlb_pgtables(struct mm_struct *mm, unsigned long start, unsigned long end) |
|---|
| 当page tables被释放或者被分裂时调用。有些平台只缓存最低level的page table,PTE,当pages被删除或者是被重新映射后,就需要刷新TLB |
| void update_mmu_cache(struct vm_area_struct *vma, unsigned long addr, pte_t pte) |
|---|
| 该API仅仅在page fault完成之后被调用 |
Level 1 CPU Cache Management
CPU caches,例如,TLB caches,主要是利用程序优先使用局部的数据。为了避免在使用数据时都要从主内存中取数据,CPU从而开始缓存一小部分数据在CPU cache中。通常来讲,有两种层级的cache,Level 1 和Level 2 CPU cache,L2 cache比L1 cache要慢很多。Linux通常只关心L1 cache。
CPU cache通常被组织成lines(行)。每个Line通常非常小,一般是32个字节,每个Line都需要与自己的边界对齐。换句话说,就是一个32字节的cache line将要求32字节对齐。在Linux中line大小有变量L1_CACHE_BYTES来描述,由各种架构自己定义具体的值。
地址如何被映射到cache line因架构而异。但是主要有三种方式:
- direct mapping:每个内存块只能映射到一个可能的cache line
- associative mapping:任意的内存块能映射到任何一个cache line
- set associative mapping:一种组合方法,任何内存狂只能映射到某个缓存行子集中的任意行。
不管是什么映射方案,它们有一个共同点:地址相近并且和cache size对齐的地址尽量使用不同的缓存行。因此Linux使用最简单的策略来最大利用cache:
- 结构中经常被访问的字段通常在结构开始的位置,从而增加仅用一个缓存行来处理普通字段的机会。
- 一个结构中不相关的项应该至少有缓存大小的字节数的隔离从而避免在CPU之间的错误共享。
- 通用缓存中的对象,如mm_struct 缓存,应该要与L1 CPU cache对齐从而避免错误共享。
如果CPU要引用的一个地址不再CPU cache中,CPU就需要从主内存中取数据。然后CPU cache匹配失败的代价是非常昂贵的,因为从L1 cache中访问一个地址只需要10ns,而从主内存中访问一个地址要100 ~ 200ns。因此最基本的原则是尽可能多的命中缓存尽可能少的命失缓存。