基于SPDK 加速框架的高性能PMEM Bdev
基于SPDK 加速框架的高性能PMEM Bdev
随着数据中心搭载了大量的高速网络以及存储设备,对于主机CPU 资源的挑战也越来越大。为了解决这个问题,一般外部外设都附有(R)DMA(Direct Memory Access)[2]的功能。比如在主机上搭载多个PCIe SSD,对于读写SSD的I/O操作,可以依赖SSD设备的DMA功能来完成。但是在主机上搭载了持久内存相关的设备(本文提到的持久内存,主要是 Intel® Optane™ Persistent Memory),情况有所改变。
当我们把PMEM内存配置成为AD(APP Direct)模式的时候,虽然持久内存可以提供数据持久化的功能,但是PMEM并不像其他PCIe外部存储设备那样具有DMA的功能,可以在对PMEM 设备进行读写的时候,减少CPU的压力。于是在SPDK[1]项目中使用PMEM设备,会在CPU负载比较重的情况下,出现一些问题。在这篇文章中我们会介绍具体的问题,以及目前在SPDK中的相应解决方案。
目前SPDK 中直接使用持久内存的问题
SPDK的核心设计思想是利用较少的CPU资源,去尽可能的发挥出存储硬件(比如PCIe SSD)的性能。总的来讲,其核心竞争力是:单CPU core上的高性能I/O设计(高吞吐/高带宽/低延迟)。因为SPDK提供了用户态的高性能I/O 栈,以及提供了一套高效的application framework。当我们的应用开发遵循SPDK application framework的框架开发程序的要义是:希望尽量使用异步以及非阻塞的模式。但是当我们在SPDK框架中整合持久性内存的时候,这个原则几近被打破。主要是由于以下两个原因:
-
PMEM设备不具有DMA功能。即使把PMEM设备变成AD模式,在对PMEM的空间进行读写的时候,依然全程需要CPU 的参与。
-
PMDK[3]库目前的局限性。PMDK提供了一系列的软件库,诸如libpmem, libpmemobj, libpmemblk。目前从SPDK的编程角度来看,存在两个巨大的问题:
a. 目前所有的PMDK API不支持异步操作。虽然SPDK主分支的版本中有一个基于libpmemblk的PMEM bdev的实现,依然遵循了SPDK bdev的接口实现了异步的API,实际上对PMEM的读写是同步的完成。对于PMEM的读写,完全依赖CPU。
b. PMDK没有offloading engine的支持。正因为PMDK主要是用CPU进行PMEM设备的编程,所以目前PMDK中暂时无法有效整合其他的offloading设备。从而无法在应用高负载情况下,解决CPU高度参与的瓶颈问题。
总的来讲,在整个操作PMEM设备的I/O路径上,CPU成为了一个重要的劳动力,没有喘息的机会。
我们可以想象一下在HCI(Hyper Converged Infrastructure)环境中,使用SPDK vhost target来服务主机上各个VM I/O的场景。当SPDK vhost target接管的存储设备都是PCIe SSD的时候,即使主机上有很多个VM,SPDK vhost都可以很好的服务各个VM,因为当VM 要对相应虚拟磁盘进行读写的时候 (无论使用virtio SCSI/blk协议),一旦SPDK vhost接收到命令并且交给底层用户态NVMe驱动进行读写的时候,CPU使用的是异步的接口,从而CPU很快可以进行其他的工作。比如持续接收其他VM的I/O指令,然后继续下发。最后统一的通过轮询的方式,检查每个VM的I/O是否完成。这一列操作,都是异步的,也可以做到相对的公平,相对来讲每个VM的latency也是可控的。
当我们在SPDK vhost中引入目前PMEM bdev的时候,这个用法就被打破了。当一个VM 的虚拟磁盘映射到SPDK vhost中的一个PMEM bdev的时候。一旦SPDK vhost对这个PMEM bdev进行I/O 读写的时候,CPU要全程参与。这样的用法导致了两个问题:
-
I/O调度的公平性。其他VM的latency会有重大影响。多租客(multi-tenancy)的性能隔离被完全打破,除非有更细粒度的调度算法,限制使用PMEM bdev的QOS。这样调度算法就会变得非常复杂。
-
SPDK使用有限可控的CPU用法可能被打破。由于在操纵PMEM设备的时候,大量的CPU时间被用于完成PMEM相关的读写。那么意味着更少的CPU用于完成同样的事情。举个例子,如果原来用SPDK vhost使用4个CPU核,来驱动10个PCIe SSD,并且可以很好的支持16个VM的I/O的并发读写。那么把这个10个PCIe SSD如果换成持久内存,可能需要大于4个CPU核心,比如6个和8个。那就意味着主机上能分配给用户的CPU(依然在HCI 环境下)将会变少,从而提供HCI服务的(云)服务厂商不愿意看到这种情况。因为更换了更新了更快的存储设备以后,服务I/O的CPU反而成为了一个瓶颈。导致可以售卖的CPU资源变少,从而增加了成本。导致这样的事情发生,这些云服务商客户甚至会进一步质疑SPDK框架对于使用PMEM设备的有效性。
目前的PMDK库没有提供异步的接口,长期来讲一定会加入异步接口以及基于硬件的卸载,满足类似SPDK这类库异步编程的需求。不过目前来讲,无法满足现有SPDK 集成使用PMEM设备的情况。为此,我们引入了SPDK acceleration framework (spdk accel_fw[4]) 来解决这个问题。
SDPK PMEM_accel bdev module介绍
SPDK accel_fw主要实现memory offloading engine的接口,目前封装了CPU/IOAT/DSA这三种设备进行(持久)内存的读写。利用SPDK accel_fw,我们在实现新的bdev—PMEM_accel bdev。SPDK pmem_accel bdev模块属于SPDK的bdev模块,目前还在开发过程中[5]。依然需要根据SPDK bdev相关头文件定义的接口实现需要的功能,比如对于块设备READ/WRITE/等操作的支持。图1给出了pmem_accel 和旧的pmem blk dev的对比。和旧的pmem bdev模块相比,主要利用了spdk accel_fw,尤其是封装在accel_fw中的DSA 硬件。
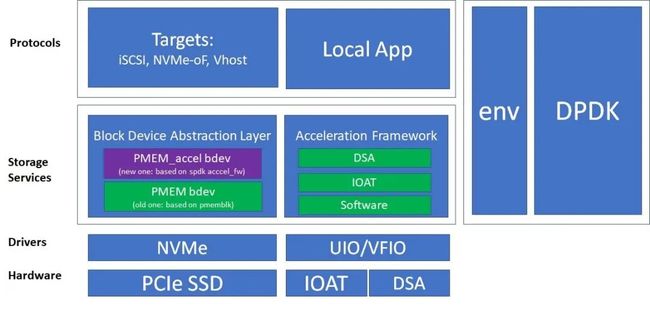
图 1 新的PMEM_acccel bdev 和旧的PMEM bdev
设计这个pmem_accel bdev的目标,主要是为了卸载CPU资源的消耗。我们的目标是利用SPDK accel_fw 中的memory offloading engine(IOAT 或者DSA),所以首先需要考量在哪些情况下我们可以用IOAT/DSA设备。我们知道Intel® Optane™ Persistent Memory 在格式化成AD模式的情况下,有两种模式。
-
FSDAX模式,在这种模式下面,在操作系统中看到的是一个块设备(诸如/dev/pmem0)。在这种模式下,用户可以直接对这个块设备进行操作,或者在上面建立文件系统,进行管理。然后如果SPDK application使用,可以在相应的文件系统中使用一个或者若干个文件,作为相应的pmem_accel bdev。
-
DAX模式。在这种模式下,系统中看到的是一个字符设备(诸如 /dev/dax0.0)这样的设备。用户可以通过字符设备的接口操纵pmem device。这个弊端是无法建立文件系统。SPDK application使用的时候,可以把PMEM的字符设备作为一个bdev。

图 2 CPU/IOAT/DSA 对于intel
傲腾内存访问的方式的可行性。
当我们用CPU在这两种模式下进行访问的时候,都是没有问题的。不过我们需要验证IOAT/DSA是不是可以在这两种模式下进行访问。笔者这边做了很多调研,暂时得出了图2中的结论。
-
首先在持久内存使用FSDAX的模式,然后在这个块设备上建立文件系统,其实有两种子情况。一种是使用“-o DAX”对已经建立好文件系统的PMEM块设备进行mount,这样可以bypass page cache,一种是不用“-o DAX”,也就是使用page cache。目前来看,FSDAX + “-o DAX”下, 使用IOAT/DSA 是有问题的,这个问题需要内核的解决(比如Linux 内核);使用FSDAX,IOAT/DSA设备可以直接访问文件系统中的每个文件。但是使用这种方法,并没有bypass page cache。也就是说实际上, IOAT/DSA设备访问的不是实际持久内存的空间,而是PAGE cache (CPU-> Page Cache-> 持久内存)。从而在掉电的时候,可能存在掉电的风险。
-
然后另外一种是DAX 模式,这种模式下IOAT/DSA都是可以直接访问进行读写。所以我们目前的PATCH[5]的开发中,我们选择了使用DAX模式来访问持久内存。虽然有一定的局限性,但是至少可以保证在使用IOAT/DSA设备的情况下,数据的持久化问题。
理想情况当然是把PMEM设备配置成FSDAX + “-o DAX”,但是这个短期来讲不容易解决IOAT/DSA访问PMEM的问题,可能需要内核中文件系统的支持。目前来讲,即使用CPU 访问FSDAX +“-o DAX” mount 情况下的文件,在linux内核也是一个experimental属性。所以我们选择把PMEM设格式化成字符设备,配合使用spdk accel_fw进行使用。
前面我们主要讨论是IOAT/DSA对于PMEM设备可访问的问题,但是对于数据持久化的问题。我们依然需要进行一些考量:由于我们使用了spdk accel_fw去操作PMEM。我们必须保证数据的一致性。也就是(1)在CPU cache,内存之间,持久内存中的一致性;(2)以及在机器掉电(power failure)时候,数据不丢失。当我们使用CPU对持久内存进行读写的场景,CPU一般可以使用clflush或者clwb把cache中的内存刷新到持久内存中。这些操作可以使用PMDK的库进行协助或者自己使用对应的汇编指令。那么如果我们使用了IOAT或者DSA library的时候,该怎么实现。笔者做了一些研究,发现IOAT似乎没有这样的功能,这就意味着掉电的时候,数据可能还在CPU cache或者内存中,那么显然在生产环境中使用IOAT 设备有一定的风险,尤其是进行写数据的时候,可能在机器掉电的时候丢失数据。然后检查了DSA 设备的spec,发现有这样的功能,那么就可以放心使用(还在开发过程中)。那么对于持久内存的操作,就可以直接绕过CPU cache/Memory,写到持久内存中,可以同时满足(1)&(2)的需求。
另外PMEM的访问,其数据写的原子性和PCIe SSD这样的块设备不一样。一般PCIe SSD块设备的原子写一般是512或者4096 bytes。对于PMEM的写原子性,可能还要小很多。为此如果PMEM_accel bdev在使用的时候,必须由上层来保证相应的原子性,包括需要实现必要的512或者4096之类的常见blocksize的原子性。
SPDK PMEM_accel bdev module的可能应用场景
SPDK PMEM_accel bdev可能有如下的使用场景,
-
Bdev独立使用的场景。也就是说PMEM_accel bdev不和其他bdev整合,直接整合在上层应用中。比如在SPDK NVMe-oF target程序中,对外提供块设备的服务。如果在SPDK NVMe-oF target中整合原有的pmem bdev,性能会比较差。但是使用了PMEM_accel bdev后,性能应该会有提高。
-
作为其他bdev的子模块。持久内存设备是比较昂贵的,直接作为SPDK的块设备存放数据,是比较浪费的,不一定满足所有应用的需求。一般来讲PMEM设备可以保存一些元数据,或者重要的log(比如WAL,write ahead log)。为此这个bdev可以和其他bdev一起使用,对于PMEM设备的读写,依然可以使用spdk accel_fw进行卸载。
总结和后续
这篇文章中主要介绍了SPDK 集成持久内存(主要是 Intel® Optane™ Persistent Memory)的时候,高负载情况下CPU 资源消耗过高,从而成为瓶颈的问题。为了解决这个问题,我们认为对于PMEM 设备的操作需要额外的memory offloading engine设备的协助。为此我们在SPDK框架中,利用SPDK accel_fw 设计和实现了一个新的bdev (pmem_accel) bdev。这个bdev可以使用SPDK accel_fw中的IOAT或者DSA引擎进行工作的负载(推荐使用DSA 引擎),从而降低CPU的使用率。
目前这个模块的代码虽然还在开发过程中,但是初始的patch已经公开,欢迎大家使用并且进行评估和反馈。可以在SPDK的mailing list,Slack或者SPDK github的相关页面联系我们,以进行相关的讨论。对于相应的性能数据,等待Intel的SPR 平台发布以及模块完善以后,不久的将来我们也会在SPDK 官网[1]进行分享。另外在阅读本文的同时,也可以参考笔者在今年China Infrastructure Day性能优化分论坛上的分享[6]。
原文链接:https://mp.weixin.qq.com/s/aEZy0IJEDAhs4J-M1keyog
学习更多dpdk视频
DPDK 学习资料、教学视频和学习路线图 :https://space.bilibili.com/1600631218
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 上课地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 君羊909332607备注(XMG) 获取