论文笔记:Template-free Prompt Tuning for Few-shot NER

论文来源:NAACL2022
论文链接:https://arxiv.org/pdf/2109.13532.pdf
代码地址: https://github.com/rtmaww/EntLM/
Abstract
基于提示学习的方法成功应用于句子级的小样本学习任务主要得益于模板和标签词的复杂设计,但是当应用于token级别的标签任务(如NER)时,在所有潜在的实体spans内枚举模板是非常耗时的。针对此问题,本文提出一种更优雅的方法,将NER任务重新表示为语言模型(LM)问题,而不需要任何模板。
具体而言,此方法摒弃模板构建过程,同时保留预训练模型的词预测范式,在实体位置预测一个类相关的中心词(或标签词)。同时,本文也探索了自动搜索标签词的原则性方法,使预训练模型易于适应。
本文所提方法在避免复杂模板的同时,还缩小了预训练和微调之间的差距,从而更好的提升小样本性能。
Introduction
基于提示学习的小样本分类任务取得成功的两个主要因素:① 重用mask,缩小了预训练和微调之间的差距,因此,即使只有少量训练样本,LM也能很好的适应下游任务;② 复杂的模板和标签词设计有助于LM更好地拟合特定任务的答案分布。
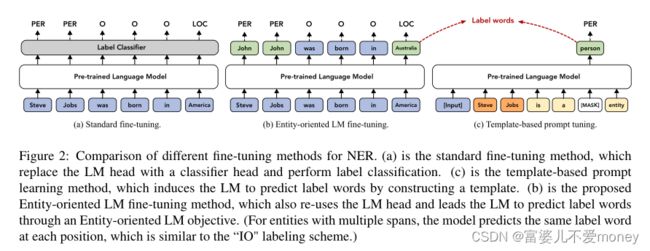
基于模板的提示方法很难适应token级分类(如NER)任务的原因:① span-level 查询时,随着搜索空间的增大,搜索合适模板困难,而且只有少量标注训练样本的情况下很容易导致过拟合。② 获取每个token的标签需要枚举所有可能的span,这是非常耗时,例如,获取下图输入的所有实体,总共需要21次查询;此外,这种方法的解码时间会随着句子长度的增加而急剧增加,不适合用于文档级NER任务。

Approach
Entity-Oriented LM Fine-tuning
本文提出一种无模板的提示调优方法,面向实体的LM微调以适应于少样本NER。传统的序列标注任务的输出是输入句子中每个字符所对应的实体类型标签,EntLM则是输出的非实体部分同输入字符,实体部分为预设的最能代表该实体类型的字符。如下图(b)所示,输入为“Obama was born in Australia”,“Obama”标签为PER,“Australia”标签为LOC,预设最能代表`PER`类型的字符是`John`,最能代表`LOC`类型的字符是`Australia`,则`was born in`所对应的输出为`was born in`,`Obama `所对应的输出为`John`,`America`所对应的输出为`Australia`。
也就是说,首先构建了一个label words集合把实体label映射到label words,然后根据输入的句子和对应的标签序列构建target sentence,方法是将实体位置的token替换为对应的标签词,并在非实体位置保持原来的单词,然后,softmax计算标签概率。
此时,出现一个新的问题,如何选定一个最能代表每个类中实体类型的字符,即label words。
Label Word Engineering
从少样本数据中生成label words具有很强的随机性,本文通过无标注的文本Wikidata和一个实体词典来选择label word,三种label word的搜索方法:
① Searching with data distribution:从语料库中选择给定类中使用频率最高的单词
② Searching with LM output distribution :使用预训练语言模型选择label word,获取模型在每个实体位置上的预测分布,选择每个实体位置预测TOP K的字符进行频率统计。例如,对`Obama was born in America`进行掩码预测,`America`位置对应的预测TOP3为`America`、`Australia`和`Beijing`,若选择TOP2进行频率统计,则`America`作为`LOC`类型出现的频率加1,`Australia`作为`LOC`类型出现的频率加1。
③ Searching with both data & LM output distribution :同时考虑上述两种方法,即两者频率相乘。
对于冲突的label words,即所选的高频标签词是所有类中潜在高频词,因此设置阈值来移除此类标签词。
Experiments
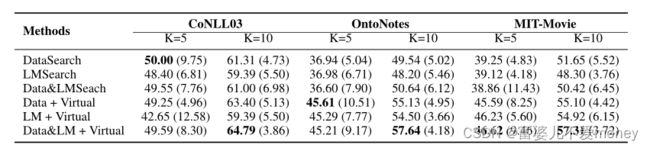
不同数据集上的综合实验:

不同label word搜索方式对实验结果的影响
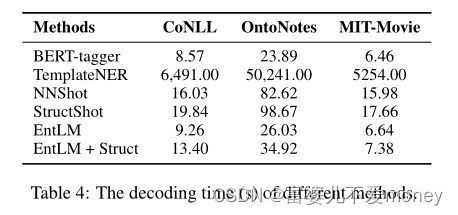
解码时间比较:
积累
① Although template-based methods are proved to be useful in sentence-level tasks, for NER task (Cui et al., 2021), such template-based method can be expensive for decoding. Therefore, in this work, we propose a new paradigm of prompt-tuning for NER without templates.
② In this work, we follow the more practical few-shot setting of Gao et al. (2021), which assumes only few samples each class for training. We also adapt previous methods to this setting as competitive baselines.