根据《利用python进行数据分析》第五章及原博文https://www.jianshu.com/p/161364dd0acf的个人使用学习笔记
pandas数据结构
Series
Series是一种类似于一维数组的对象,由一组数组(NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
In [11]: obj = pd.Series([4, 7, -5, 3])
In [12]: obj
Out[12]:
0 4
1 7
2 -5
3 3
dtype: int64
- 属性:values, index
In [15]: obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
In [16]: obj2
Out[16]:
d 4
b 7
a -5
c 3
dtype: int64
In [17]: obj2.index
Out[17]: Index(['d', 'b', 'a', 'c'], dtype='object')
In [42]: obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
In [43]: obj
Out[43]:
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int64
对于Series,可以使用NumPy函数或类似NumPy的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等),同时会保留索引值的链接
可以看成定长的有序字典,也可以直接通过这个字典来创建Series
pandas的isnull和notnull函数可用于检测缺失数据
Series对象本身及其索引都有一个name属性
In [38]: obj4.name = 'population'
In [39]: obj4.index.name = 'state'
In [40]: obj4
Out[40]:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
DataFrame
DataFrame是一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame构造方法
- 直接传入一个由等长列表或NumPy数组组成的字典
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
- 传入嵌套字典,外层字典的键作为列,内层键则作为行索引
In [65]: pop = {'Nevada': {2001: 2.4, 2002: 2.9},
....: 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
In [66]: frame3 = pd.DataFrame(pop)
In [67]: frame3
Out[67]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
- 传入Series组成的字典

访问与赋值
-
访问:frame[column]适用于任何列的名,frame.column只有在列名是一个合理的Python变量名时适用,返回一个Series
通过索引方式返回的列只是相应数据的视图而已,并不是副本。对返回的Series所做的任何就地修改全都会反映到源DataFrame上。通过Series的copy方法即可指定复制列。
head方法
赋值:列可以通过赋值修改,赋上标量或者数组或Series(必须含index),为不存在的列赋值会创建出一个新列
In [58]: val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
In [59]: frame2['debt'] = val
In [60]: frame2
Out[60]:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
six 2003 Nevada 3.2 NaN`
其他属性与方法
- del方法
In [63]: del frame2['eastern']
In [64]: frame2.columns
Out[64]: Index(['year', 'state', 'pop', 'debt'], dtype='object')
index, columns都有name等属性
values属性以二维ndarray的形式返回DataFrame中的数据,如果DataFrame各列的数据类型不同,则值数组的dtype就会选用能兼容所有列的数据类型
In [75]: frame2.values
Out[75]:
array([[2000, 'Ohio', 1.5, nan],
[2001, 'Ohio', 1.7, -1.2],
[2002, 'Ohio', 3.6, nan],
[2001, 'Nevada', 2.4, -1.5],
[2002, 'Nevada', 2.9, -1.7],
[2003, 'Nevada', 3.2, nan]], dtype=object)
索引对象index
- 特点:不可修改,可以重复

基本功能
重新索引reindex
创建一个新对象,它的数据符合新的索引
不是重新对index赋值,而是重排顺序
如果某个索引值当前不存在,就引入缺失值
In [91]: obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
In [92]: obj
Out[92]:
d 4.5
b 7.2
a -5.3
c 3.6
dtype: float64
In [93]: obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
In [94]: obj2
Out[94]:
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64
- 对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充
In [95]: obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
In [96]: obj3
Out[96]:
0 blue
2 purple
4 yellow
dtype: object
In [97]: obj3.reindex(range(6), method='ffill')
Out[97]:
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
- 列可以用columns关键字重新索引
In [102]: states = ['Texas', 'Utah', 'California']
In [103]: frame.reindex(columns=states)
Out[103]:
Texas Utah California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8

删除drop
In [105]: obj = pd.Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
In [106]: obj
Out[106]:
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: float64
In [109]: obj.drop(['d', 'c'])
Out[109]:
a 0.0
b 1.0
e 4.0
dtype: float64
通过传递axis=1或axis='columns'可以删除列的值
In [113]: data.drop('two', axis=1)
Out[113]:
one three four
Ohio 0 2 3
Colorado 4 6 7
Utah 8 10 11
New York 12 14 15
索引、选取和过滤
Series索引与普通python切片不同,其末端是包含的
对DataFrame进行索引关键字可以获取一个或多个列
对DataFrame进行索引数字列表或布尔型数组可以获取一个或多个行
还有类似numpy二维数组的语法
In [128]: data = pd.DataFrame(np.arange(16).reshape((4, 4)),
.....: index=['Ohio', 'Colorado', 'Utah', 'New York'],
.....: columns=['one', 'two', 'three', 'four'])
In [131]: data[['three', 'one']]
Out[131]:
three one
Ohio 2 0
Colorado 6 4
Utah 10 8
New York 14 12
In [132]: data[:2]
Out[132]:
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
In [133]: data[data['three'] > 5]
Out[133]:
one two three four
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
In [134]: data < 5
Out[134]:
one two three four
Ohio True True True True
Colorado True False False False
Utah False False False False
New York False False False False
- 用轴标签loc,整数标签iloc可以类似NumPy的标记选择行、列
In [137]: data.loc['Colorado', ['two', 'three']]
Out[137]:
two 5
three 6
Name: Colorado, dtype: int64
In [138]: data.iloc[2, [3, 0, 1]]
Out[138]:
four 11
one 8
two 9
Name: Utah, dtype: int6

算数运算和数据对齐
pandas可以对不同索引的对象进行算术运算。
在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。
自动的数据对齐操作在不重叠的索引处引入了NA值。
In [150]: s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
In [151]: s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],
.....: index=['a', 'c', 'e', 'f', 'g'])
In [152]: s1
Out[152]:
a 7.3
c -2.5
d 3.4
e 1.5
dtype: float64
In [153]: s2
Out[153]:
a -2.1
c 3.6
e -1.5
f 4.0
g 3.1
dtype: float64
In [154]: s1 + s2
Out[154]:
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
对于DataFrame,对齐操作会同时发生在行和列上
add方法,传入df2以及一个fill_value参数,当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值
In [171]: df1.add(df2, fill_value=0)
Out[171]:
a b c d e
0 0.0 2.0 4.0 6.0 4.0
1 9.0 5.0 13.0 15.0 9.0
2 18.0 20.0 22.0 24.0 14.0
3 15.0 16.0 17.0 18.0 19.0
- 常用算数方法,每个都有一个副本,以字母r开头,它会翻转参数。
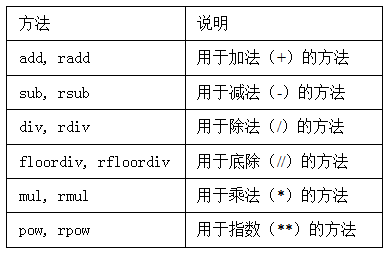
DataFrame和Series之间的运算
- 不同维度的NumPy数组运算,每一行都会执行这个操作。这就叫做广播(broadcasting)
In [175]: arr = np.arange(12.).reshape((3, 4))
In [176]: arr
Out[176]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
In [177]: arr[0]
Out[177]: array([ 0., 1., 2., 3.])
In [178]: arr - arr[0]
Out[178]:
array([[ 0., 0., 0., 0.],
[ 4., 4., 4., 4.],
[ 8., 8., 8., 8.]])
DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集
In [179]: frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
.....: columns=list('bde'),
.....: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [180]: series = frame.iloc[0]
In [181]: frame
Out[181]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [182]: series
Out[182]:
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
In [183]: frame - series
Out[183]:
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
In [184]: series2 = pd.Series(range(3), index=['b', 'e', 'f'])
In [185]: frame + series2
Out[185]:
b d e f
Utah 0.0 NaN 3.0 NaN
Ohio 3.0 NaN 6.0 NaN
Texas 6.0 NaN 9.0 NaN
Oregon 9.0 NaN 12.0 NaN
- 如果匹配行且在列上广播,则必须使用算术运算方法。
In [186]: series3 = frame['d']
In [187]: frame
Out[187]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In [188]: series3
Out[188]:
Utah 1.0
Ohio 4.0
Texas 7.0
Oregon 10.0
Name: d, dtype: float64
In [189]: frame.sub(series3, axis='index')
# (axis='index' or axis=0)
Out[189]:
b d e
Utah -1.0 0.0 1.0
Ohio -1.0 0.0 1.0
Texas -1.0 0.0 1.0
Oregon -1.0 0.0 1.0
函数应用和映射
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象
apply方法即可实现将函数应用到由各列或行所形成的一维数组上
In [193]: f = lambda x: x.max() - x.min()
In [194]: frame.apply(f)
Out[194]:
b 1.802165
d 1.684034
e 2.689627
dtype: float64
函数f计算了一个Series的最大值和最小值的差,在frame的每列都执行了一次
传递axis='columns'到apply,这个函数会在每行执行
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series
元素级的Python函数也是可以用的,使用applymap即可,Series有一个用于应用元素级函数的map方法
In [198]: format = lambda x: '%.2f' % x
In [199]: frame.applymap(format)
Out[199]:
b d e
Utah -0.20 0.48 -0.52
Ohio -0.56 1.97 1.39
Texas 0.09 0.28 0.77
Oregon 1.25 1.01 -1.30
In [200]: frame['e'].map(format)
Out[200]:
Utah -0.52
Ohio 1.39
Texas 0.77
Oregon -1.30
Name: e, dtype: object
排名和排序
sort方法
要对行或列索引进行排序(按字典顺序),可使用sort_index方法,sort_values方法,它将返回一个已排序的新对象,默认是按升序排序的,缺失值默认放末尾
对于DataFrame,sort_index可以根据任意一个轴上的索引进行排序.将一个或多个列的名字传递给sort_values的by选项,可以根据特定值排列
In [203]: frame = pd.DataFrame(np.arange(8).reshape((2, 4)),
.....: index=['three', 'one'],
.....: columns=['d', 'a', 'b', 'c'])
In [206]: frame.sort_index(axis=1, ascending=False)
Out[206]:
d c b a
three 0 3 2 1
one 4 7 6 5
In [214]: frame.sort_values(by=['a', 'b'])
Out[214]:
a b
2 0 -3
0 0 4
3 1 2
1 1 7
rank方法
默认通过“为各组分配一个平均排名”的方式破坏平级关系的
也可以根据值在原数据中出现的顺序给出排名
In [215]: obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
In [216]: obj.rank()
Out[216]:
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
In [218]: obj.rank(ascending=False, method='max')
Out[218]:
0 2.0
1 7.0
2 2.0
3 4.0
4 5.0
5 6.0
6 4.0
dtype: float64
In [221]: frame.rank(axis='columns')
Out[221]:
a b c
0 2.0 3.0 1.0
1 1.0 3.0 2.0
2 2.0 1.0 3.0
3 2.0 3.0 1.0

重复标签的轴索引
许多pandas函数(如reindex)都要求标签唯一,但这并不是强制性的
索引的is_unique属性可以告诉你它的值是否是唯一的
如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值
汇总和计算描述统计
汇总统计
pandas对象拥有一组常用的数学和统计方法,大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series
调用DataFrame的sum方法将会返回一个含有列的和的Series,传入axis='columns'或axis=1将会按行进行求和运算
NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能
In [230]: df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5],
.....: [np.nan, np.nan], [0.75, -1.3]],
.....: index=['a', 'b', 'c', 'd'],
.....: columns=['one', 'two'])
In [231]: df
Out[231]:
one two
a 1.40 NaN
b 7.10 -4.5
c NaN NaN
d 0.75 -1.3
In [233]: df.sum(axis=1)
Out[233]:
a 1.40
b 2.60
c NaN
d -0.55

- 有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引)或累计型
In [235]: df.idxmax()
Out[235]:
one b
two d
dtype: object
In [236]: df.cumsum()
Out[236]:
one two
a 1.40 NaN
b 8.50 -4.5
c NaN NaN
d 9.25 -5.8
In [237]: df.describe()
Out[237]:
one two
count 3.000000 2.000000
mean 3.083333 -2.900000
std 3.493685 2.262742
min 0.750000 -4.500000
25% 1.075000 -3.700000
50% 1.400000 -2.900000
75% 4.250000 -2.100000
max 7.100000 -1.300000
In [238]: obj = pd.Series(['a', 'a', 'b', 'c'] * 4)
In [239]: obj.describe()
Out[239]:
count 16
unique 3
top a
freq 8
dtype: object

相关系数与协方差
- pct_change()方法用于计算百分数变化
In [242]: returns = price.pct_change()
In [243]: returns.tail()
Out[243]:
AAPL GOOG IBM MSFT
Date
2016-10-17 -0.000680 0.001837 0.002072 -0.003483
2016-10-18 -0.000681 0.019616 -0.026168 0.007690
2016-10-19 -0.002979 0.007846 0.003583 -0.002255
2016-10-20 -0.000512 -0.005652 0.001719 -0.004867
2016-10-21 -0.003930 0.003011 -0.012474 0.042096
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数,cov用于计算协方差
DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵
DataFrame的corrwith方法可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算)
In [244]: returns['MSFT'].corr(returns['IBM'])
Out[244]: 0.49976361144151144
In [245]: returns['MSFT'].cov(returns['IBM'])
Out[245]: 8.8706554797035462e-05
In [247]: returns.corr()
Out[247]:
AAPL GOOG IBM MSFT
AAPL 1.000000 0.407919 0.386817 0.389695
GOOG 0.407919 1.000000 0.405099 0.465919
IBM 0.386817 0.405099 1.000000 0.499764
MSFT 0.389695 0.465919 0.499764 1.000000
In [248]: returns.cov()
Out[248]:
AAPL GOOG IBM MSFT
AAPL 0.000277 0.000107 0.000078 0.000095
GOOG 0.000107 0.000251 0.000078 0.000108
IBM 0.000078 0.000078 0.000146 0.000089
MSFT 0.000095 0.000108 0.000089 0.000215
In [249]: returns.corrwith(returns.IBM)
Out[249]:
AAPL 0.386817
GOOG 0.405099
IBM 1.000000
MSFT 0.499764
dtype: float64
唯一值、值计数以及成员资格
unique可以得到Series中的唯一值数组
可以对结果再次进行排序(uniques.sort())
value_counts用于计算一个Series中各值出现的频率
In [251]: obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
In [252]: uniques = obj.unique()
In [253]: uniques
Out[253]: array(['c', 'a', 'd', 'b'], dtype=object)
In [255]: pd.value_counts(obj.values, sort=False)
Out[255]:
a 3
b 2
c 3
d 1
dtype: int64
- isin用于判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子集,返回布尔值Series