tensorflow2.0--keras入门
1.keras框架搭建步骤
1.import //导入依赖库
2.train test //设置训练集和测试集
3.model=tf.keras.models.Sequential //搭建网络,完成前向传播 4.model.comlie //设置训练参数
5.model.fit//执行训练过程
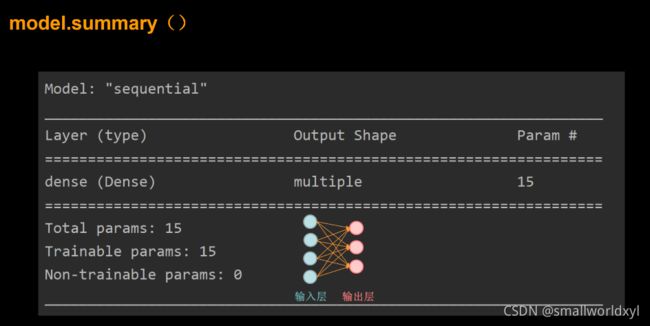
6.model.summary//打印网络结构和参数统计


这里注意,如果你的神经网络输出已经经过了概率分布(如经过了softmax),这里的from_logits参数为False,否则为True.

2.采用keras Sequential结构实现鸢尾花分类
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
#加载数据
x_train=datasets.load_iris().data
y_train=datasets.load_iris().target
#打乱数据
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
model=tf.keras.models.Sequential([
tf.keras.layers.Dense(3,activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
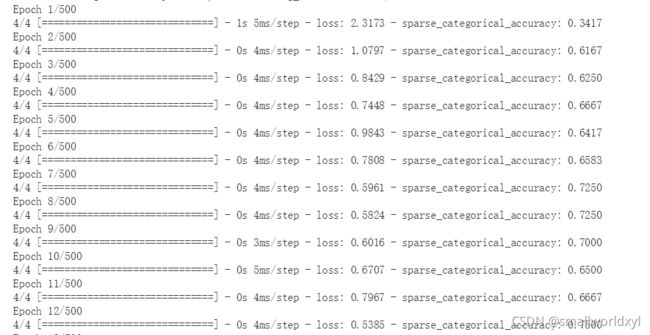
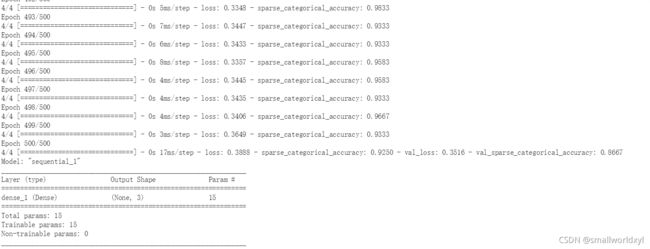
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20)
model.summary()
输出:
3.使用keras class结构搭建
Sequential只能搭建上层输出就是下层输入的网络结构.使用class搭建一些带有跳连的非顺序网络结构

用class结构改写鸢尾花分类
class IrisModel(Model):
def __init__(self):
super(IrisModel,self).__init__()
self.d1=Dense(3,activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())
def call(self,x):
y=self.d1(x)
return y
model=IrisModel()
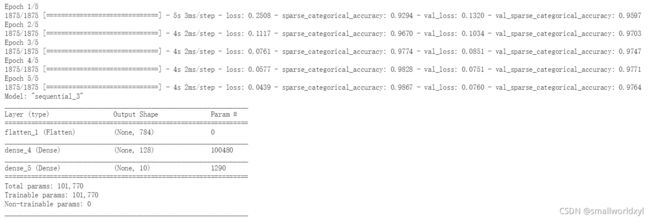
4.采用两种结构实现mnist手写识别数据集的训练
4.1 mnist数据集介绍

每个数据为28*28的矩阵,值为0代表黑色,255代表白色。
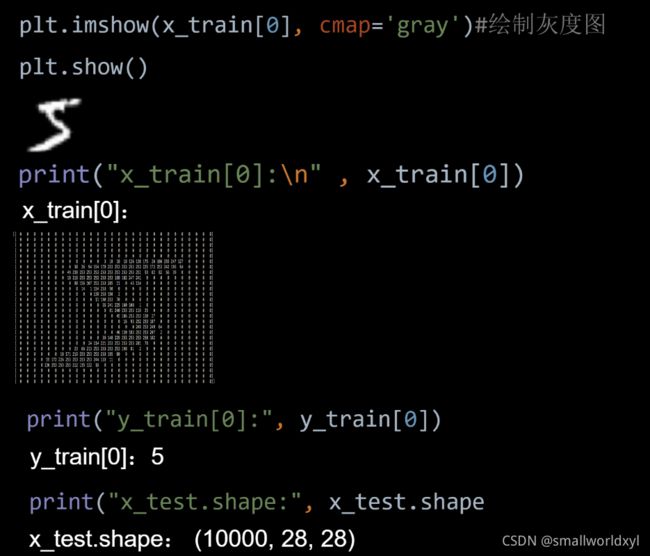
4.2 代码实现
import tensorflow as tf
mnist=tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
#将数据归一化
x_train,x_test=x_train/255.0,x_test/255.0
----------------------------------------------------------------------
#1.采用Sequential结构
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
------------------------------------------------------------------------
#2.采用class结构
class MnistModel(Model):
def __init__(self):
super(MnistModel,self).__init__()
self.flatten=Flatten()
self.d1=Dense(128,activation='relu')
self.d2=Dense(10,activation='rsoftmax')
def call(self,x):
x=self.flattern(x)
x=self.d1(x)
y=self.d2(x)
return y
model=MnistModel
------------------------------------------------------------------------model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train,y_train,batch_size=32,epochs=5,validation_data=(x_test,y_test),validation_freq=1)
model.summary()
输出: