Mybatis源码分析(7)之缓存原理源码分析
一、前言
在 Web 应用中,缓存是必不可少的组件。通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力。作为一个重要的组件,MyBatis 自然也在内部提供了相应的支持。通过在框架层面增加缓存功能,可减轻数据库的压力,同时又可以提升查询速度,可谓一举两得。MyBatis 缓存结构由一级缓存和二级缓存构成,这两级缓存均是使用 Cache 接口的实现类。因此,在接下里的章节中,我将首先会向大家介绍 Cache 几种实现类的源码,然后再分析一级和二级缓存的实现。下面先来分析 Cache 及其实现类。
二、Mybatis缓存类介绍
在 MyBatis 中,Cache 是顶级缓存接口,定义了一些基本的缓存操作,所有缓存类都应该实现该接口。MyBatis 内部提供了丰富的缓存实现类,比如具有基本缓存功能的 PerpetualCache,具有 LRU 策略的缓存 LruCache,以及可保证线程安全的缓存 SynchronizedCache 和具备阻塞功能的缓存 BlockingCache 等。除此之外,还有很多缓存实现类,,MyBatis 在实现缓存模块的过程中,使用了装饰模式。在以上几种缓存实现类中,PerpetualCache 相当于装饰模式中的 ConcreteComponent。LruCache、SynchronizedCache 和 BlockingCache 等相当于装饰模式中的 ConcreteDecorator。它们的关系如下:
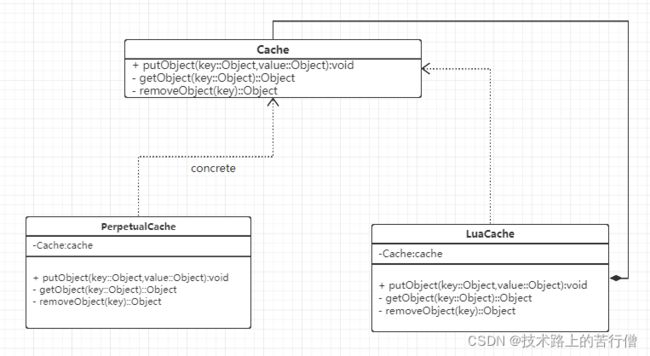
接下来我们来看看各个缓存类的基本实现。
2.1PerpetualCache
PerpetualCache 是一个具有基本功能的缓存类,其实也比较简单,他的内部使用了 HashMap 实现缓存功能。它的源码如下:
/**
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
private final String id;
private Map cache = new HashMap();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
} 2.2LruCache
LruCache,顾名思义,是一种具有 LRU 策略的缓存实现类。除此之外,MyBatis 还提供了具有 FIFO 策略的缓存 FifoCache。
/**
* Lru (least recently used) cache decorator
*
* @author Clinton Begin
*/
public class LruCache implements Cache {
private final Cache delegate;
private Map keyMap;
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
setSize(1024);
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
public void setSize(final int size) {
/*
* 初始化 keyMap,注意,keyMap 的类型继承自 LinkedHashMap,
* 并覆盖了 removeEldestEntry 方法
*/
keyMap = new LinkedHashMap(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
// 覆盖 LinkedHashMap 的 removeEldestEntry 方法
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 获取将要被移除缓存项的键值
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
cycleKeyList(key);
}
@Override
public Object getObject(Object key) {
// 刷新 key 在 keyMap 中的位置
keyMap.get(key);
// 从被装饰类中获取相应缓存项
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
// 从被装饰类中移除相应的缓存项
return delegate.removeObject(key);
}
@Override
public void clear() {
delegate.clear();
keyMap.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private void cycleKeyList(Object key) {
// 存储 key 到 keyMap 中
keyMap.put(key, key);
if (eldestKey != null) {
// 从被装饰类中移除相应的缓存项
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
} 如上,LruCache 的 keyMap 属性是实现 LRU 策略的关键,该属性类型继承自 LinkedHashMap,并覆盖了 removeEldestEntry 方法。LinkedHashMap 可保持键值对的插入顺序,当插入一个新的键值对时,LinkedHashMap 内部的 tail 节点会指向最新插入的节点。head 节点则指向第一个被插入的键值对,也就是最久未被访问的那个键值对。默认情况下,LinkedHashMap 仅维护键值对的插入顺序。若要基于 LinkedHashMap 实现 LRU 缓存,还需通过构造方法将 LinkedHashMap 的 accessOrder 属性设为 true,此时 LinkedHashMap 会维护键值对的访问顺序。比如,上面代码中 getObject 方法中执行了这样一句代码 keyMap.get(key),目的是刷新 key 对应的键值对在 LinkedHashMap 的位置。LinkedHashMap 会将 key 对应的键值对移动到链表的尾部,尾部节点表示最久刚被访问过或者插入的节点。除了需将 accessOrder 设为 true,还需覆盖 removeEldestEntry 方法。LinkedHashMap 在插入新的键值对时会调用该方法,以决定是否在插入新的键值对后,移除老的键值对。在上面的代码中,当被装饰类的容量超出了 keyMap 的所规定的容量(由构造方法传入)后,keyMap 会移除最长时间未被访问的键,并保存到 eldestKey 中,然后由 cycleKeyList 方法将 eldestKey 传给被装饰类的 removeObject 方法,移除相应的缓存项目。
2.3BlockingCache
BlockingCache 实现了阻塞特性,该特性是基于 Java 重入锁实现的。同一时刻下,BlockingCache 仅允许一个线程访问指定 key 的缓存项,其他线程将会被阻塞住。下面我们来看一下 BlockingCache 的源码。
/**
* Simple blocking decorator
*
* Simple and inefficient version of EhCache's BlockingCache decorator.
* It sets a lock over a cache key when the element is not found in cache.
* This way, other threads will wait until this element is filled instead of hitting the database.
*
* @author Eduardo Macarron
*
*/
public class BlockingCache implements Cache {
private long timeout;
private final Cache delegate;
private final ConcurrentHashMap locks;
public BlockingCache(Cache delegate) {
this.delegate = delegate;
this.locks = new ConcurrentHashMap();
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
@Override
public void putObject(Object key, Object value) {
try {
// 存储缓存项
delegate.putObject(key, value);
} finally {
// 释放锁
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
// 请求锁
acquireLock(key);
Object value = delegate.getObject(key);
// 若缓存命中,则释放锁。需要注意的是,未命中则不释放锁
if (value != null) {
// 释放锁
releaseLock(key);
}
return value;
}
@Override
public Object removeObject(Object key) {
// despite of its name, this method is called only to release locks
releaseLock(key);
return null;
}
@Override
public void clear() {
delegate.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private ReentrantLock getLockForKey(Object key) {
ReentrantLock lock = new ReentrantLock();
// 存储 键值对到 locks 中
ReentrantLock previous = locks.putIfAbsent(key, lock);
return previous == null ? lock : previous;
}
private void acquireLock(Object key) {
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
// 尝试加锁
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
// 加锁
lock.lock();
}
}
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
public long getTimeout() {
return timeout;
}
public void setTimeout(long timeout) {
this.timeout = timeout;
}
} 如上,查询缓存时,getObject 方法会先获取与 key 对应的锁,并加锁。若缓存命中,getObject 方法会释放锁,否则将一直锁定。getObject 方法若返回 null,表示缓存未命中。此时 MyBatis 会进行数据库查询,并调用 putObject 方法存储查询结果。同时,putObject 方法会将指定 key 对应的锁进行解锁,这样被阻塞的线程即可恢复运行。
三、一级缓存
在进行数据库查询之前,MyBatis 首先会检查以及缓存中是否有相应的记录,若有的话直接返回即可。一级缓存是数据库的最后一道防护,若一级缓存未命中,查询请求将落到数据库上。一级缓存是在 BaseExecutor 被初始化的,下面我们来看一下相关的初始化逻辑:
/**
* @author Clinton Begin
*/
public abstract class BaseExecutor implements Executor {
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
this.deferredLoads = new ConcurrentLinkedQueue();
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
// ....省略部分代码
} 如上,一级缓存的类型为 PerpetualCache,没有被其他缓存类装饰过。一级缓存所存储从查询结果会在 MyBatis 执行更新操作(INSERT/UPDATE/DELETE),以及提交和回滚事务时被清空。下面我们来看一下查询一级缓存的逻辑。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取BoundSql对象,BoundSql是对动态SQL解析生成的SQL语句和参数映射信息的封装
BoundSql boundSql = ms.getBoundSql(parameter);
// 创建CacheKey,用于缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用重载的query()方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
// 从一级缓存中获取结果
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 缓存中获取不到,则调用queryFromDatabase()方法从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 从一级缓存中延迟加载嵌套查询结果
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
} 在计算 CacheKey 的过程中,有很多影响因子参与了计算。比如 MappedStatement 的 id 字段,SQL 语句,分页参数,运行时变量,Environment 的 id 字段等。通过让这些影响因子参与计算,可以很好的区分不同查询请求。所以,我们可以简单的把 CacheKey 看做是一个查询请求的 id。有了 CacheKey,我们就可以使用它读写缓存了。在上面代码中,若一级缓存没有命中,BaseExecutor 会调用 queryFromDatabase 查询数据库,并将查询结果写入缓存中。下面看一下 queryFromDatabase 的逻辑。
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
// 向缓存中存储一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 调用doQuery()方法查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 缓存查询结果
localCache.putObject(key, list);
// 存储过程相关逻辑,忽略
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
到此,关于一级缓存相关的逻辑就差不多分析完了。一级缓存的逻辑比较简单,大家可以简单过一遍。接下来分析二级缓存。
四、二级缓存
二级缓存构建在一级缓存之上,在收到查询请求时,MyBatis 首先会查询二级缓存。若二级缓存未命中,再去查询一级缓存。与一级缓存不同,二级缓存和具体的命名空间绑定,一级缓存则是和 SqlSession 绑定。在按照 MyBatis 规范使用 SqlSession 的情况下,一级缓存不存在并发问题。二级缓存则不然,二级缓存可在多个命名空间间共享。这种情况下,会存在并发问题,因此需要针对性去处理。除了并发问题,二级缓存还存在事务问题,相关问题将在接下来进行分析。下面首先来看一下访问二级缓存的逻辑。
@Override
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取boundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 调用createCacheKey()方法创建缓存Key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 调用重载方法
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取MappedStatement对象中维护的二级缓存对象
Cache cache = ms.getCache();
// 若映射文件中未配置缓存或参照缓存,此时 cache = null
if (cache != null) {
// 判断是否需要刷新二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
// 从MappedStatement对象对应的二级缓存中获取数据
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);
if (list == null) {
// 若缓存未命中,则调用被装饰类的 query 方法
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 將数据存放到MappedStatement对象对应的二级缓存中
tcm.putObject(cache, key, list);
}
return list;
}
}
// 调用被装饰类的 query 方法
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} 如上,注意二级缓存是从 MappedStatement 中获取的,而非由 CachingExecutor 创建。由于 MappedStatement 存在于全局配置中,可以多个 CachingExecutor 获取到,这样就会出现线程安全问题。除此之外,若不加以控制,多个事务共用一个缓存实例,会导致脏读问题。线程安全问题可以通过 SynchronizedCache 装饰类解决,该装饰类会在 Cache 实例构造期间被添加上。
下面分析一下TransactionalCacheManager。
/**
* @author Clinton Begin
*/
public class TransactionalCacheManager {
// 通过HashMap对象维护二级缓存对应的TransactionalCache实例
private final Map transactionalCaches = new HashMap();
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
// 获取二级缓存对应的TransactionalCache对象,然后根据缓存Key获取缓存对象
return getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
// 获取二级缓存对应的TransactionalCache对象
TransactionalCache txCache = transactionalCaches.get(cache);
if (txCache == null) {
// 如果获取不到则创建,然后添加到Map中
txCache = new TransactionalCache(cache);
transactionalCaches.put(cache, txCache);
}
return txCache;
}
} TransactionalCacheManager 内部维护了 Cache 实例与 TransactionalCache 实例间的映射关系,该类也仅负责维护两者的映射关系,真正做事的还是 TransactionalCache。TransactionalCache 是一种缓存装饰器,可以为 Cache 实例增加事务功能。我在之前提到的脏读问题正是由该类进行处理的。下面分析一下该类的逻辑。
/**
* The 2nd level cache transactional buffer.
*
* This class holds all cache entries that are to be added to the 2nd level cache during a Session.
* Entries are sent to the cache when commit is called or discarded if the Session is rolled back.
* Blocking cache support has been added. Therefore any get() that returns a cache miss
* will be followed by a put() so any lock associated with the key can be released.
*
* @author Clinton Begin
* @author Eduardo Macarron
*/
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
private final Cache delegate;
private boolean clearOnCommit;
// 在事务被提交前,所有从数据库中查询的结果将缓存在此集合中
private final Map entriesToAddOnCommit;
// 在事务被提交前,当缓存未命中时,CacheKey 将会被存储在此集合中
private final Set 在 TransactionalCache 的代码中,我们要重点关注 entriesToAddOnCommit 集合,TransactionalCache 中的很多方法都会与这个集合打交道。该集合用于存储从查询的结果,那为什么要将结果保存在该集合中,而非 delegate 所表示的缓存中呢?主要是因为直接存到 delegate 会导致脏数据问题。下面通过一张图演示一下脏数据问题发生的过程,假设两个线程开启两个不同的事务,它们的执行过程如下:
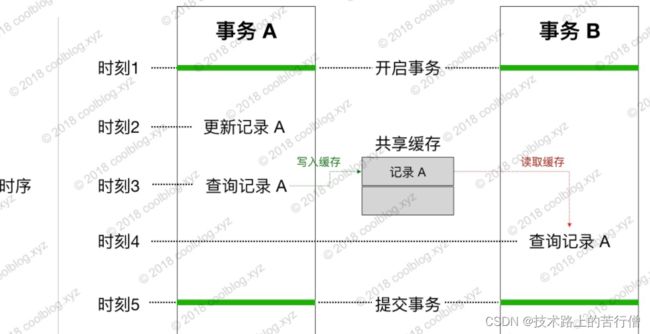
如上图,时刻2,事务 A 对记录 A 进行了更新。时刻3,事务 A 从数据库查询记录 A,并将记录 A 写入缓存中。时刻4,事务 B 查询记录 A,由于缓存中存在记录 A,事务 B 直接从缓存中取数据。这个时候,脏数据问题就发生了。事务 B 在事务 A 未提交情况下,读取到了事务 A 所修改的记录。为了解决这个问题,我们可以为每个事务引入一个独立的缓存。查询数据时,仍从 delegate 缓存(以下统称为共享缓存)中查询。若缓存未命中,则查询数据库。存储查询结果时,并不直接存储查询结果到共享缓存中,而是先存储到事务缓存中,也就是 entriesToAddOnCommit 集合。当事务提交时,再将事务缓存中的缓存项转存到共享缓存中。这样,事务 B 只能在事务 A 提交后,才能读取到事务 A 所做的修改,解决了脏读问题。整个过程大致如下:
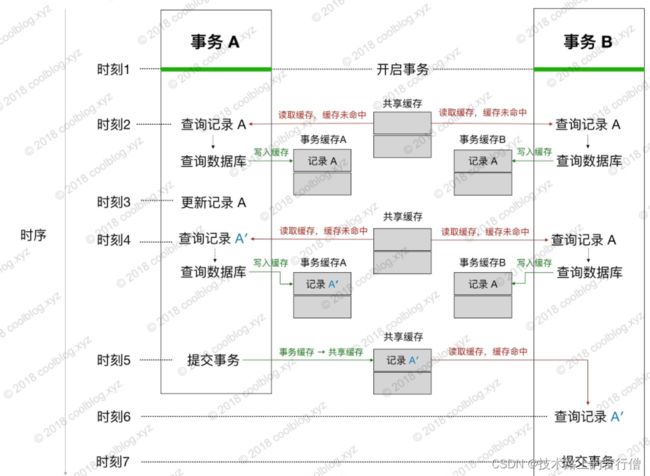
如上,时刻2,事务 A 和 B 同时查询记录 A。此时共享缓存中还没没有数据,所以两个事务均会向数据库发起查询请求,并将查询结果存储到各自的事务缓存中。时刻3,事务 A 更新记录 A,这里把更新后的记录 A 记为 A′。时刻4,两个事务再次进行查询。此时,事务 A 读取到的记录为修改后的值,而事务 B 读取到的记录仍为原值。时刻5,事务 A 被提交,并将事务缓存 A 中的内容转存到共享缓存中。时刻6,事务 B 再次查询记录 A,由于共享缓存中有相应的数据,所以直接取缓存数据即可。因此得到记录 A′,而非记录 A。但由于事务 A 已经提交,所以事务 B 读取到的记录 A′ 并非是脏数据。MyBatis 引入事务缓存解决了脏读问题,事务间只能读取到其他事务提交后的内容,这相当于事务隔离级别中的“读已提交(Read Committed)”。但需要注意的时,MyBatis 缓存事务机制只能解决脏读问题,并不能解决“不可重复读”问题。再回到上图,事务 B 在被提交前进行了三次查询。前两次查询得到的结果为记录 A,最后一次查询得到的结果为 A′。最有一次的查询结果与前两次不同,这就会导致“不可重复读”的问题。MyBatis 的缓存事务机制最高只支持“读已提交”,并不能解决“不可重复读”问题。即使数据库使用了更高的隔离级别解决了这个问题,但因 MyBatis 缓存事务机制级别较低。此时仍然会导致“不可重复读”问题的发生,这个在日常开发中需要注意一下。
五、总结
本篇文章简单介绍了一些缓存类的实现,并对一二级缓存进行了深入分析。本文仅分析了缓存的使用过程,并未对缓存的初始化,以及 CachingExecutor 和 SimpleExecutor(继承自 BaseExecutor)创建过程进行分析。