【Kotlin】函数式编程 ② ( 过滤函数 | predicate 谓词函数 | filter 过滤函数 | 合并函数 | zip 函数 | folder 函数 | 函数式编程意义 )
文章目录
- 一、过滤函数
- 二、filter 函数原型
- 三、filter 过滤函数代码示例
-
- 1、filter 函数简单示例
- 2、filter 过滤函数与 flatMap 变换函数 组合使用示例
- 3、filter 过滤函数与 map 变换函数 组合使用示例
- 四、合并函数
-
- 1、zip 合并函数
- 2、folder 合并函数
- 五、函数式编程意义
函数式编程的三种函数类别 :
- 变换 Transform
- 过滤 Filter
- 合并 Combine
在上一篇博客 函数式编程 ① 中 讲解了 变换函数 map 函数 与 flatMap 函数 , 本篇博客中着重讲解 过滤函数 和 合并函数 ;
一、过滤函数
过滤函数 是 函数式编程 中的函数类型 , 一般该类型函数 接收一个 Predicate 谓词函数 作为参数 ;
该 谓词函数 参数 是一个 Lambda 表达式 / 匿名函数 / 闭包 ; ( 三者是同一个概念 )
过滤函数 的 接收者 是一个 集合 , 也就是说 过滤函数 要从 接收者集合 中 过滤掉一些元素 , 生成一个 新的集合 ;
谓词函数 主要是 按照一定的逻辑条件 , 判断 接收者集合 中的元素 是否符合某种条件 , 如果符合返回 true , 不符合条件返回 false ;
- 谓词函数 返回 true , 将该元素添加到新的集合中 ;
- 谓词函数 返回 false , 该函数不能被添加到新的集合中 ;
注意 : 过滤函数 会返回一个新的集合 , 原来的接收者集合不会发生改变 ;
二、filter 函数原型
filter 函数原型 :
/**
* Returns a list containing only elements matching the given [predicate].
* 返回只包含匹配给定[predicate]的元素的列表。
* @sample samples.collections.Collections.Filtering.filter
*/
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}
该 过滤函数 filter 函数 , 是 集合 类型的扩展函数 , 集合的元素类型 是 泛型 T , 可以是任意类型 ;
filter 函数的参数 predicate: (T) -> Boolean 谓词函数 , 是匿名函数 , 用于 判断 接收者集合 中的 受检元素 是否符合 该 匿名函数 的要求 ,
- 如果 该元素 符合要求 , 该 匿名函数 返回 true , 将该 接收者集合 中的 受检元素 放到 返回值集合 List
中 ; - 如果 该元素 不符合要求 , 该 匿名函数 返回 false , 该 接收者集合 中的 受检元素 不会放到返回值集合 List
中 , 相当于 被过滤掉了 ;
三、filter 过滤函数代码示例
1、filter 函数简单示例
代码示例 :
fun main() {
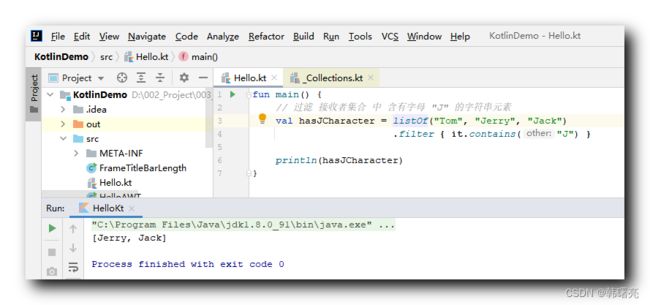
// 过滤 接收者集合 中 含有字母 "J" 的字符串元素
val hasJCharacter = listOf("Tom", "Jerry", "Jack")
.filter { it.contains("J") }
println(hasJCharacter)
}
执行结果 :
[Jerry, Jack]
2、filter 过滤函数与 flatMap 变换函数 组合使用示例
代码示例 :
- 先 使用 flatMap 变换函数 , 将 集合的集合 拉平 , 在 flatMap 函数的闭包参数中的 it 是 返回的是 集合元素 ,
- 然后针对该集合 调用 filter 过滤函数 , 将其中 包含 J 字幕的元素过滤出来 ,
- 最终得到的集合是 先 将两个集合合并 , 然后 再过滤包含 J 的元素 的新集合 ;
fun main() {
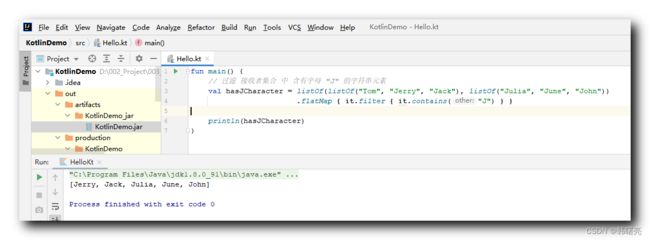
// 过滤 接收者集合 中 含有字母 "J" 的字符串元素
val hasJCharacter = listOf(listOf("Tom", "Jerry", "Jack"), listOf("Julia", "June", "John"))
.flatMap { it.filter { it.contains("J") } }
println(hasJCharacter)
}
执行结果 :
[Jerry, Jack, Julia, June, John]
如果要在 Java 中实现上述功能 , 需要设置双重循环 , 外层循环遍历 外层集合 , 内层循环 遍历 内层集合 ;
在 Kotlin 中使用函数式编程实现 , 仅需要 1 行代码 ;
3、filter 过滤函数与 map 变换函数 组合使用示例
找出 2 到 10 之间的 质数 ; 质数 是 大于 1 并且 只有 1 和 其本身 可以被其整除 ;
代码示例 :
- 执行
numbers.filter{}代码 , 如果 匿名函数 参数 返回 true , 则为质数 , 该 匿名函数 的 参数 number 是被遍历的 接收者集合 的 受检元素 ; - 判定质数 , 就需要根据 " 质数只有 1 和 其本身 可以被其整除 " 的原理进行判定 , 遍历时每个 受检元素 都要 被 [2…number - 1] 区间的数值进行遍历 , 使用
(2..number - 1).map{}进行遍历 , 计算 number 与 [2…number - 1] 区间中的数值 相除的 余数 , 确保这些余数不为 0 即可 ; - 上面的 map 变换函数 会 返回一个 余数集合 , 调用该 余数集合的
.none{it == 0}函数 , 确保余数中不会有 0 , 没有 0 则返回 true , 说明余数都不为 0 , [2…number - 1] 区间的数值都不能被整除 , 该数值为 质数 ;
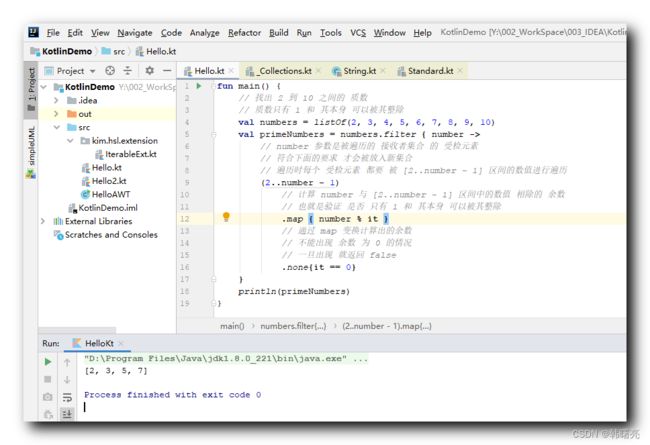
fun main() {
// 找出 2 到 10 之间的 质数
// 质数只有 1 和 其本身 可以被其整除
val numbers = listOf(2, 3, 4, 5, 6, 7, 8, 9, 10)
val primeNumbers = numbers.filter { number ->
// number 参数是被遍历的 接收者集合 的 受检元素
// 符合下面的要求 才会被放入新集合
// 遍历时每个 受检元素 都要 被 [2..number - 1] 区间的数值进行遍历
(2..number - 1)
// 计算 number 与 [2..number - 1] 区间中的数值 相除的 余数
// 也就是验证 是否 只有 1 和 其本身 可以被其整除
.map { number % it }
// 通过 map 变换计算出的余数
// 不能出现 余数 为 0 的情况
// 一旦出现 就返回 false
.none{it == 0}
}
println(primeNumbers)
}
执行结果 : 最终得到如下几个质数 ;
[2, 3, 5, 7]
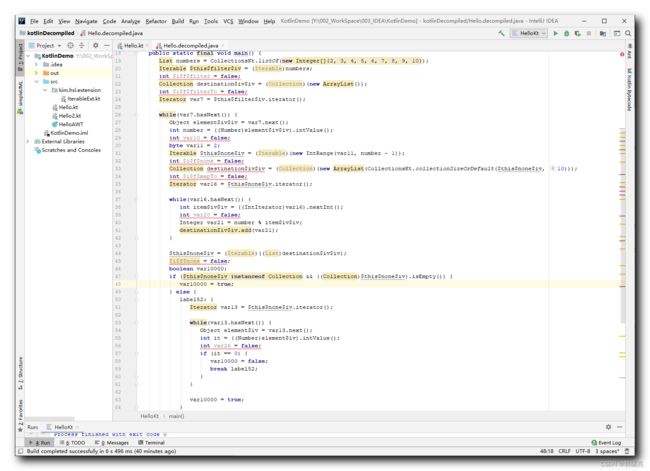
上述判定质数的操作 , 使用 Kotlin 代码只需要一行链式调用代码搞定 , 如果是 Java 代码 , 要写好多循环 , 至少 50 行代码 ;
使用 Kotlin Bytecode 将字节码反编译会 Java 代码如下 : 可以看到有几十行代码 , 使用 Java 代码实现很复杂 ;
none 函数原型 : 接收者集合 调用 none 函数 , 传入 谓词匿名函数 参数 返回布尔值 , 如果 所有的 接收者集合元素 对应的 匿名函数参数 都 返回 false , 则整体返回 true ;
/**
* Returns `true` if no elements match the given [predicate].
* 如果没有元素匹配给定的[谓词],则返回' true '。
* @sample samples.collections.Collections.Aggregates.noneWithPredicate
*/
public inline fun <T> Iterable<T>.none(predicate: (T) -> Boolean): Boolean {
if (this is Collection && isEmpty()) return true
for (element in this) if (predicate(element)) return false
return true
}
四、合并函数
合并函数 是 函数式编程 的一种函数类型 , 该类型函数 的作用是 将不同的集合 合并成 新的集合 ;
1、zip 合并函数
zip 函数 可以将 两个元素个数相同的集合 合并成 一个 新的 Pair 键值对 List 集合 , 其中 一个集合的元素作为 键 Key , 另外一个集合的元素作为 值 Value ;
被合并 的 两个集合 可以是 不同类型的集合 ;
zip 组合函数原型 :
/**
* Returns a list of pairs built from the elements of `this` collection and [other] collection with the same index.
* The returned list has length of the shortest collection.
* 返回由具有相同索引的' this '集合和[other]集合的元素构建的对列表。
* 返回的列表长度为最短的集合。
* @sample samples.collections.Iterables.Operations.zipIterable
*/
public infix fun <T, R> Iterable<T>.zip(other: Iterable<R>): List<Pair<T, R>> {
return zip(other) { t1, t2 -> t1 to t2 }
}
zip 函数 是为 Iterable
该 zip 函数的 参数是 Iterable
最终返回的类型是 List
由于 zip 函数使用了 infix 修饰 , 可以使用如下方式进行调用 , 下面的调用是等效的 ;
// 合并函数
val nameAndAges = names.zip(ages)
// 由于 zip 函数使用了 infix 修饰
// 因此可以使用如下方式进行调用
val nameAndAges2 = names zip ages
代码示例 :
fun main() {
val names = listOf("Tom", "Jerry", "Jack")
val ages = listOf(16, 17, 18)
// 合并函数
val nameAndAges = names.zip(ages)
// 由于 zip 函数使用了 infix 修饰
// 因此可以使用如下方式进行调用
val nameAndAges2 = names zip ages
println(nameAndAges)
println(nameAndAges2)
}
执行结果 :
[(Tom, 16), (Jerry, 17), (Jack, 18)]
[(Tom, 16), (Jerry, 17), (Jack, 18)]
2、folder 合并函数
folder 合并函数 接收一个 初始的 累加器值 , 之后该值 会 根据 匿名函数 的执行结果 进行更新 ;
folder 函数原型 :
/**
* Accumulates value starting with [initial] value and applying [operation] from left to right
* to current accumulator value and each element.
* 从[初始值]开始累加值,从左到右应用[操作]到当前累加器值和每个元素。
*
* Returns the specified [initial] value if the collection is empty.
* 如果集合为空,则返回指定的[初始值]。
*
* @param [operation] function that takes current accumulator value and an element,
* and calculates the next accumulator value.
* 匿名函数,该函数获取当前累加器值和一个元素,并计算下一个累加器值。
*/
public inline fun <T, R> Iterable<T>.fold(initial: R, operation: (acc: R, T) -> R): R {
var accumulator = initial
for (element in this) accumulator = operation(accumulator, element)
return accumulator
}
遍历 集合中的元素 , 将集合中的元素 进行平方 后相加 ;
分析下面代码的执行过程 :
- 遍历集合元素 1 , 此时累加器值为 0 , 匿名函数 返回结果 0 + 1 * 1 = 1 , 这个 结果 1 会作为下一次遍历的 累加器值 ;
- 遍历集合元素 2 , 此时累加器值为 1 , 匿名函数 返回结果 1 + 2 * 2 = 5 , 这个 结果 5 会作为下一次遍历的 累加器值 ;
- 遍历集合元素 3 , 此时累加器值为 5 , 匿名函数 返回结果 5 + 3 * 3 = 14 , 遍历完成 ;
代码示例 :
fun main() {
val numbers = listOf(1, 2, 3).fold(0) {
accumulator, number ->
println("累加器值 : $accumulator, number : $number")
accumulator + number * number
}
println(numbers)
}
执行结果 :
累加器值 : 0, number : 1
累加器值 : 1, number : 2
累加器值 : 5, number : 3
14

五、函数式编程意义
函数式编程意义 :
- 代码量 : 函数式编程 代码量 远远小于 传统的 面向对象编程 的 代码量 ; 函数式编程 一行 调用链代码 相当于 Java 几十行代码量 ;
- 代码量对比 : 函数式编程 < 面向对象编程 < 面向过程编程
- 可读性高 : 由于代码量减小 , 对应的中间变量和流程也大大的减少了 , 函数式编程 的 可读性 远远高于 面向对象编程 ;
- 健壮性 : 使用 函数式编程 , 计算过程中使用的 累加变量 都是隐式定义的 , 运算结果自动赋值给累加变量 , 代码健壮性比较高 , 出错几率变小 ;
- 适配所有集合 : 函数式编程 的 变换 | 过滤 | 合并 函数 , 都是 为 Iterable
类型定义的 扩展函数 , 所有的集合都可以直接添加到 函数式编程 的调用链 中 ;