Java 中代码优化的 30 个小技巧(上)
前言
今天我们一起聊聊 Java 中代码优化的 30 个小技巧,希望会对你有所帮助。
1 用 String.format 拼接字符串
不知道你有没有拼接过字符串,特别是那种有多个参数,字符串比较长的情况。
比如现在有个需求:要用 get 请求调用第三方接口,url 后需要拼接多个参数。
以前我们的请求地址是这样拼接的:
String url = "http://susan.sc.cn?userName="+userName+"&age="+age+"&address="+address+"&sex="+sex+"&roledId="+roleId;字符串使用 + 号拼接,非常容易出错。
后面优化了一下,改为使用 StringBuilder 拼接字符串:
StringBuilder urlBuilder = new StringBuilder("http://susan.sc.cn?");
urlBuilder.append("userName=")
.append(userName)
.append("&age=")
.append(age)
.append("&address=")
.append(address)
.append("&sex=")
.append(sex)
.append("&roledId=")
.append(roledId);代码优化之后,稍微直观点。但还是看起来比较别扭。
这时可以使用 String.format 方法优化:
String requestUrl = "http://susan.sc.cn?userName=%s&age=%s&address=%s&sex=%s&roledId=%s";
String url = String.format(requestUrl,userName,age,address,sex,roledId);代码的可读性,一下子提升了很多。
我们平常可以使用 String.format 方法拼接 url 请求参数,日志打印等字符串。
注意:不建议在 for 循环中用它拼接字符串。因为它的执行效率,比使用 + 号拼接字符串,或者使用 StringBuilder 拼接字符串都要慢一些。
2 创建可缓冲的 IO 流
IO 流想必大家都使用得比较多,我们经常需要把数据写入某个文件,或者从某个文件中读取数据到内存中,甚至还有可能把文件 a,从目录 b,复制到目录 c 下等。
JDK 给我们提供了非常丰富的 API,可以去操作 IO 流。
例如:
public class IoTest1 {
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
File srcFile = new File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/1.txt");
File destFile = new File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/2.txt");
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
int len;
while ((len = fis.read()) != -1) {
fos.write(len);
}
fos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}这个例子主要的功能,是将 1.txt 文件中的内容复制到 2.txt 文件中。
这例子使用普通的 IO 流从功能的角度来说,也能满足需求,但性能却不太好。因为这个例子中,从 1.txt 文件中读一个字节的数据,就会马上写入 2.txt 文件中,需要非常频繁的读写文件。
优化:
public class IoTest {
public static void main(String[] args) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
FileInputStream fis = null;
FileOutputStream fos = null;
try {
File srcFile = new File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/1.txt");
File destFile = new File("/Users/dv_susan/Documents/workspace/jump/src/main/java/com/sue/jump/service/test1/2.txt");
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
bos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bos != null) {
bos.close();
}
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (bis != null) {
bis.close();
}
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}这个例子使用 BufferedInputStream 和 BufferedOutputStream 创建了可缓冲的输入输出流。
最关键的地方是定义了一个 buffer 字节数组,把从 1.txt 文件中读取的数据临时保存起来,后面再把该 buffer 字节数组的数据,一次性批量写入到 2.txt 中。
这样做的好处是,减少了读写文件的次数,而我们都知道读写文件是非常耗时的操作。也就是说使用可缓存的输入输出流,可以提升 IO 的性能,特别是遇到文件非常大时,效率会得到显著提升。
3 减少循环次数
在我们日常开发中,循环遍历集合是必不可少的操作。但如果循环层级比较深,循环中套循环,可能会影响代码的执行效率。
反例:
for(User user: userList) {
for(Role role: roleList) {
if(user.getRoleId().equals(role.getId())) {
user.setRoleName(role.getName());
}
}
}这个例子中有两层循环,如果 userList 和 roleList 数据比较多的话,需要循环遍历很多次,才能获取我们所需要的数据,非常消耗cpu资源。
正例:
Map> roleMap = roleList.stream().collect(Collectors.groupingBy(Role::getId));
for (User user : userList) {
List roles = roleMap.get(user.getRoleId());
if(CollectionUtils.isNotEmpty(roles)) {
user.setRoleName(roles.get(0).getName());
}
} 减少循环次数,最简单的办法是,把第二层循环的集合变成 map,这样可以直接通过 key,获取想要的 value 数据。
虽说 map 的 key 存在 hash 冲突的情况,但遍历存放数据的链表或者红黑树的时间复杂度,比遍历整个 list 集合要小很多。
4 用完资源记得及时关闭
在我们日常开发中,可能经常访问资源,比如获取数据库连接,读取文件等。
我们以获取数据库连接为例。
反例:
//1. 加载驱动类
Class.forName("com.mysql.jdbc.Driver");
//2. 创建连接
Connection connection = DriverManager.getConnection("jdbc:mysql//localhost:3306/db?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8","root","123456");
//3.编写sql
String sql ="select * from user";
//4.创建PreparedStatement
PreparedStatement pstmt = conn.prepareStatement(sql);
//5.获取查询结果
ResultSet rs = pstmt.execteQuery();
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
}面这段代码可以正常运行,但却犯了一个很大的错误,即 ResultSet、 PreparedStatement 和 Connection 对象的资源,使用完之后,没有关闭。
我们都知道,数据库连接是非常宝贵的资源。我们不可能一直创建连接,并且用完之后,也不回收,白白浪费数据库资源。
正例:
//1. 加载驱动类
Class.forName("com.mysql.jdbc.Driver");
Connection connection = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
//2. 创建连接
connection = DriverManager.getConnection("jdbc:mysql//localhost:3306/db?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8","root","123456");
//3.编写sql
String sql ="select * from user";
//4.创建PreparedStatement
pstmt = conn.prepareStatement(sql);
//5.获取查询结果
rs = pstmt.execteQuery();
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
}
} catch(Exception e) {
log.error(e.getMessage(),e);
} finally {
if(rs != null) {
rs.close();
}
if(pstmt != null) {
pstmt.close();
}
if(connection != null) {
connection.close();
}
}这个例子中,无论是 ResultSet,或者 PreparedStatement,还是 Connection 对象,使用完之后,都会调用 close 方法关闭资源。
注意:ResultSet,或者PreparedStatement,还是Connection对象,这三者关闭资源的顺序不能反了,不然可能会出现异常。
5 使用池技术
我们都知道,从数据库查数据,首先要连接数据库,获取 Connection 资源。想让程序多线程执行,需要使用 Thread 类创建线程,线程也是一种资源。
通常一次数据库操作的过程是这样的:
-
创建连接
-
进行数据库操作
-
关闭连接
而创建连接和关闭连接,是非常耗时的操作,创建连接需要同时会创建一些资源,关闭连接时,需要回收那些资源。
如果用户的每一次数据库请求,程序都都需要去创建连接和关闭连接的话,可能会浪费大量的时间。此外,可能会导致数据库连接过多。
我们都知道数据库的最大连接数是有限的,以 MySQL 为例,最大连接数是 100,不过可以通过参数调整这个数量。
如果用户请求的连接数超过最大连接数,就会报 "too many connections" 异常。如果有新的请求过来,会发现数据库变得不可用。
这时可以通过命令:
show variables like max_connections查看最大连接数。
然后通过命令:
set GLOBAL max_connections=1000手动修改最大连接数。这种做法只能暂时缓解问题,不是一个好的方案,无法从根本上解决问题。
最大的问题是:数据库连接数可以无限增长,不受控制。
这时我们可以使用数据库连接池。
目前 Java 开源的数据库连接池有:
-
DBCP:是一个依赖 Jakarta commons-pool 对象池机制的数据库连接池。
-
C3P0:是一个开放源代码的 JDBC 连接池,它在 lib 目录中与 Hibernate 一起发布,包括了实现 jdbc3 和 jdbc2 扩展规范说明的 Connection 和 Statement 池的 DataSources 对象。
-
Druid:阿里的 Druid,不仅是一个数据库连接池,还包含一个 ProxyDriver、一系列内置的 JDBC 组件库、一个 SQL Parser。
-
Proxool:是一个 Java SQL Driver 驱动程序,它提供了对选择的其它类型的驱动程序的连接池封装,可以非常简单的移植到已有代码中。
目前用的最多的数据库连接池是 Druid。
6 反射时加缓存
我们都知道通过反射创建对象实例,比使用 new 关键字要慢很多。由此,不太建议在用户请求过来时,每次都通过反射实时创建实例。
有时候,为了代码的灵活性,又不得不用反射创建实例,这时该怎么办呢?
答:加缓存。
其实 Spring 中就使用了大量的反射,我们以支付方法为例。
根据前端传入不同的支付 code,动态找到对应的支付方法,发起支付。
我们先定义一个注解。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface PayCode {
String value();
String name();
}在所有的支付类上都加上该注解。
@PayCode(value = "alia", name = "支付宝支付")
@Service
public class AliaPay implements IPay {
@Override
public void pay() {
System.out.println("===发起支付宝支付===");
}
}
@PayCode(value = "weixin", name = "微信支付")
@Service
public class WeixinPay implements IPay {
@Override
public void pay() {
System.out.println("===发起微信支付===");
}
}
@PayCode(value = "jingdong", name = "京东支付")
@Service
public class JingDongPay implements IPay {
@Override
public void pay() {
System.out.println("===发起京东支付===");
}
}然后增加最关键的类:
@Service
public class PayService2 implements ApplicationListener {
private static Map payMap = null;
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
ApplicationContext applicationContext = contextRefreshedEvent.getApplicationContext();
Map beansWithAnnotation = applicationContext.getBeansWithAnnotation(PayCode.class);
if (beansWithAnnotation != null) {
payMap = new HashMap<>();
beansWithAnnotation.forEach((key, value) ->{
String bizType = value.getClass().getAnnotation(PayCode.class).value();
payMap.put(bizType, (IPay) value);
});
}
}
public void pay(String code) {
payMap.get(code).pay();
}
} PayService2 类实现了 ApplicationListener 接口,这样在 onApplicationEvent 方法中,就可以拿到 ApplicationContext 的实例。这一步,其实是在 Spring 容器启动的时候, Spring 通过反射我们处理好了。
我们再获取打了 PayCode 注解的类,放到一个 map 中。map 中的 key 就是 PayCode 注解中定义的 value,跟 code 参数一致,value 是支付类的实例。
这样,每次就可以每次直接通过 code 获取支付类实例,而不用 if...else 判断了。如果要加新的支付方法,只需在支付类上面打上 PayCode 注解定义一个新的 code 即可。
注意:这种方式的 code 可以没有业务含义,可以是纯数字,只要不重复就行。
7 多线程处理
很多时候,我们需要在某个接口中,调用其他服务的接口。
比如有这样的业务场景:
在用户信息查询接口中需要返回:用户名称、性别、等级、头像、积分、成长值等信息。
而用户名称、性别、等级、头像在用户服务中,积分在积分服务中,成长值在成长值服务中。为了汇总这些数据统一返回,需要另外提供一个对外接口服务。
于是,用户信息查询接口需要调用用户查询接口、积分查询接口 和 成长值查询接口,然后汇总数据统一返回。
调用过程如下图所示:
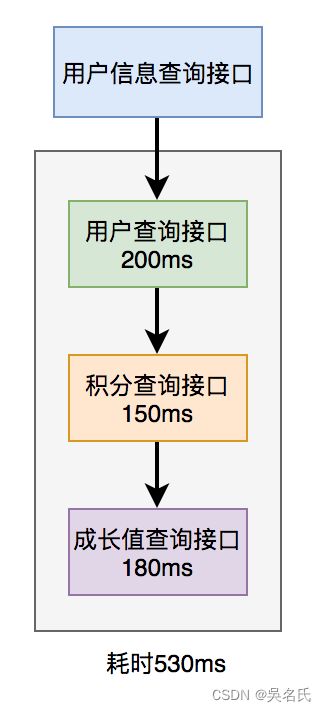
调用远程接口总耗时 530ms = 200ms + 150ms + 180ms
显然这种串行调用远程接口性能是非常不好的,调用远程接口总的耗时为所有的远程接口耗时之和。
那么如何优化远程接口性能呢?
上面说到,既然串行调用多个远程接口性能很差,为什么不改成并行呢?
如下图所示:
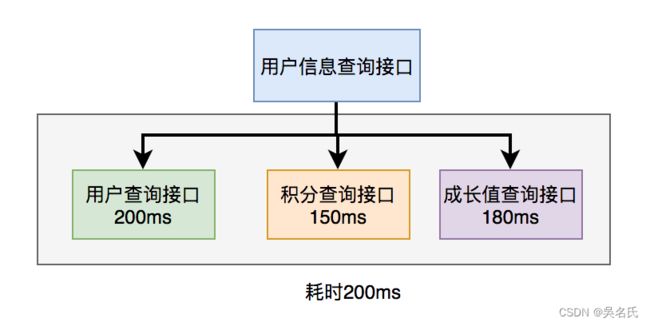
调用远程接口总耗时 200ms = 200ms(即耗时最长的那次远程接口调用)
在 Java8 之前可以通过实现 Callable 接口,获取线程返回结果。
Java8 以后通过 CompleteFuture 类实现该功能。我们这里以 CompleteFuture 为例:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}注意:这两种方式别忘了使用线程池。示例中我用到了executor,表示自定义的线程池,为了防止高并发场景下,出现线程过多的问题。
8 懒加载
有时候,创建对象是一个非常耗时的操作,特别是在该对象的创建过程中,还需要创建很多其他的对象时。
我们以单例模式为例。
在介绍单例模式的时候,必须要先介绍它的两种非常著名的实现方式饿汉模式和懒汉模式。
8.1 饿汉模式
实例在初始化的时候就已经建好了,不管你有没有用到,先建好了再说。具体代码如下:
public class SimpleSingleton {
//持有自己类的引用
private static final SimpleSingleton INSTANCE = new SimpleSingleton();
//私有的构造方法
private SimpleSingleton() {
}
//对外提供获取实例的静态方法
public static SimpleSingleton getInstance() {
return INSTANCE;
}
}使用饿汉模式的好处是:没有线程安全的问题,但带来的坏处也很明显。
private static final SimpleSingleton INSTANCE = new SimpleSingleton();一开始就实例化对象了,如果实例化过程非常耗时,并且最后这个对象没有被使用,不是白白造成资源浪费吗?
还真是啊。
这个时候你也许会想到,不用提前实例化对象,在真正使用的时候再实例化不就可以了?
这就是我接下来要介绍的懒汉模式。
8.2 懒汉模式
顾名思义就是实例在用到的时候才去创建,“比较懒”,用的时候才去检查有没有实例,如果有则返回,没有则新建。具体代码如下:
public class SimpleSingleton2 {
private static SimpleSingleton2 INSTANCE;
private SimpleSingleton2() {
}
public static SimpleSingleton2 getInstance() {
if (INSTANCE == null) {
INSTANCE = new SimpleSingleton2();
}
return INSTANCE;
}
}示例中的 INSTANCE 对象一开始是空的,在调用 getInstance 方法才会真正实例化。
懒汉模式相对于饿汉模式,没有提前实例化对象,在真正使用的时候再实例化,在实例化对象的阶段效率更高一些。
除了单例模式之外,懒加载的思想,使用比较多的可能是:
-
spring 的 @Lazy 注解。在 Spring 容器启动的时候,不会调用其 getBean 方法初始化实例。
-
MyBatis 的懒加载。在 MyBatis 做级联查询的时候,比如查用户的同时需要查角色信息。如果用了懒加载,先只查用户信息,真正使用到角色了,才取查角色信息。
9 初始化集合时指定大小
我们在实际项目开发中,需要经常使用集合,比如 ArrayList、HashMap 等。
但有个问题:你在初始化集合时指定了大小的吗?
反例:
public class Test2 {
public static void main(String[] args) {
List list = new ArrayList<>();
long time1 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list.add(i);
}
System.out.println(System.currentTimeMillis() - time1);
}
} 执行时间:
12如果在初始化集合时指定了大小。
正例:
public class Test2 {
public static void main(String[] args) {
List list2 = new ArrayList<>(100000);
long time2 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list2.add(i);
}
System.out.println(System.currentTimeMillis() - time2);
}
} 执行时间:
6我们惊奇的发现,在创建集合时指定了大小,比没有指定大小,添加 10 万个元素的效率提升了一倍。
如果你看过 ArrayList 源码,你就会发现它的默认大小是 10,如果添加元素超过了一定的阀值,会按 1.5 倍的大小扩容。
你想想,如果装 10 万条数据,需要扩容多少次呀?而每次扩容都需要不停的复制元素,从老集合复制到新集合中,需要浪费多少时间呀,所以,我们在使用集合的时候,如果能实现估计到集合的大小,最好定义一个大小,尽量做到集合不扩容。
10 不要满屏 try...catch 异常
以前我们在开发接口时,如果出现异常,为了给用户一个更友好的提示,例如:
@RequestMapping("/test")
@RestController
public class TestController {
@GetMapping("/add")
public String add() {
int a = 10 / 0;
return "成功";
}
}如果不做任何处理,当我们请求 add 接口时,执行结果直接报错:
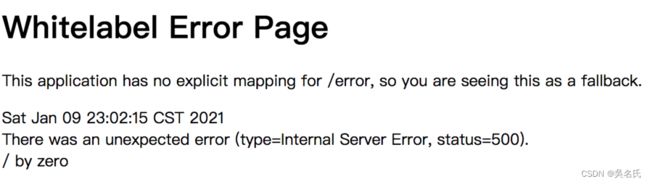
What?用户能直接看到错误信息?
这种交互方式给用户的体验非常差,为了解决这个问题,我们通常会在接口中捕获异常:
@GetMapping("/add")
public String add() {
String result = "成功";
try {
int a = 10 / 0;
} catch (Exception e) {
result = "数据异常";
}
return result;
}接口改造后,出现异常时会提示:“数据异常”,对用户来说更友好。
看起来挺不错的,但是有问题……
如果只是一个接口还好,但是如果项目中有成百上千个接口,都要加上异常捕获代码吗?
答案是否定的,这时全局异常处理就派上用场了 RestControllerAdvice。
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public String handleException(Exception e) {
if (e instanceof ArithmeticException) {
return "数据异常";
}
if (e instanceof Exception) {
return "服务器内部异常";
}
return null;
}
}只需在 handleException 方法中处理异常情况,业务接口中可以放心使用,不再需要捕获异常(有人统一处理了)。真是爽歪歪。
11. 相关文章
一、Java 中代码优化的 30 个小技巧(上)
二、Java 中代码优化的 30 个小技巧(中)
三、Java 中代码优化的 30 个小技巧(下)