序列化方案选型对比 - JSON/ProtocolBuffer/FlatBuffer/DIMBIN
背景
JSON/XML不好吗?
好,再没有一种序列化方案能像JSON和XML一样流行,自由、方便,拥有强大的表达力和跨平台能力。是通用数据传输格式的默认首选。不过随着数据量的增加和性能要求的提升,这种自由与通用带来的性能问题也不容忽视。
JSON和XML使用字符串表示所有的数据,对于非字符数据来说,字面量表达会占用很多额外的存储空间,并且会严重受到数值大小和精度的影响。 一个32位浮点数 1234.5678 在内存中占用 4 bytes 空间,如果存储为 utf8 ,则需要占用 9 bytes空间,在JS这样使用utf16表达字符串的环境中,需要占用 18 bytes空间。 使用正则表达式进行数据解析,在面对非字符数据时显得十分低效,不仅要耗费大量的运算解析数据结构,还要将字面量转换成对应的数据类型。
在面对海量数据时,这种格式本身就能够成为整个系统的IO与计算瓶颈,甚至直接overflow。
JSON/XML之外还有什么?
众多的序列化方案中,按照存储方案,可分为字符串存储和二进制存储,字符串存储是可读的,但是由于以上问题,这里只考虑二进制存储。二进制存储中可分为需要IDL和不需要IDL,或分为自描述与非自描述(反序列化是否需要IDL)。
需要IDL的使用过程:
-
使用该方案所定义的IDL语法编写schema
-
使用该方案提供的编译器将schema编译成生产方和消费方所用语言的代码(类或者模块)
-
数据生产方引用该代码,根据其接口,构建数据,并序列化
-
消费方引用该代码,根据其接口读取数据
不需要IDL的使用过程:
-
生产方与消费方通过文档约定数据结构
-
生产方序列化
-
消费方反序列化
etc.
-
protocol buffers
-
gRPC所用的传输协议,二进制存储,需要IDL,非自描述
-
高压缩率,表达性极强,在Google系产品中使用广泛
-
flat buffers
-
Google推出序列化方案,二进制存储,需要IDL,非自描述(自描述方案不跨平台)
-
高性能,体积小,支持string、number、boolean
-
avro
-
Hadoop使用的序列化方案,将二进制方案和字符串方案的优势结合起来,仅序列化过程需要IDL,自描述
-
然而场景受限,没有成熟的JS实现,不适合Web环境,这里不做对比
-
Thrift
-
Facebook的方案,二进制存储,需要IDL,非自描述
-
基本上只集成在RPC中使用,这里不做对比
-
DIMBIN
-
针对多维数组设计的序列化方案,二进制存储,不需要IDL,自描述
-
高性能,体积小,支持string、number、boolean
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,编解码,推拉流,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
优化原理
空间优化原理
使用数值类型而非字面量来保存数值,本身就能节约一笔十分可观的空间。 protocol buffer为了实现更高的压缩率,使用varint去压缩数值。(不过下面的测试表明,可以使用gzip的环境中,这种方案没有帮助)
时间优化原理
二进制格式用通过特定位置来记录数据结构以及每个节点数据的偏移量,省去了从字符串中解析数据结构所耗费的时间,避免了长字符串带来的性能问题,在GC语言中,也大大减少了中间垃圾的产生。
在可以进行内存直接操作的环境中(包括JS),还可以通过内存偏移量直接读取数据,而避免进行复制操作,也避免开辟额外的内存空间。DIMBIN和flatbuffers都使用了这种理念来优化数据存储性能。在JS环境中,通过建立DataView或者TypedArray来从内存段中提取数据的耗时基本上可以忽略不计。
二进制方案中存储字符串需要额外的逻辑进行UTF8编解码,性能和体积不如JSON这样的字符串格式。
DIMBIN是什么?
我们的数据可视化场景中经常涉及百万甚至千万条数据的实时更新,为解决JSON的性能问题,我们使用内存偏移量操作的思路,开发了DIMBIN作为序列化方案,并基于其上设计了许多针对web端数据处理的传输格式。
作为一种简单直白的优化思路,DIMBIN已经成为我们数据传输的标准方案,保持绝对的精简与高效。
我们刚刚将DIMBIN开源,贡献给社区,希望能为大家带来一个比 JSON/protocol/flatbuffers 更轻、更快、对Web更友好的解决方案。
方案对比
针对Web/JS环境中的使用,我们选择 JSON、protocol buffers、flat buffers、DIMBIN 四种方案,从七个方面进行对比。
工程化
Protocolbuffers 和 flatbuffers 代表Google所倡导的完整的workflow。严格、规范、统一、面向IDL,为多端协作所设计,针对python/java/c++。通过IDL生成代码,多平台/多语言使用一致的开发流程。如果团队采用这种工作流,那么这种方案更便于管理,多端协作和接口更迭都更可控。
但是如果离开了这套工程结构,则显得相对繁杂。
JSON/XML 和 DIMBIN 是中立的,不需要IDL,不对工程化方案和技术选型作假设或限制。可以只通过文档规范接口,也可以自行添加schema约束。
部署/编码复杂度
Protocolbuffers 和 flatbuffers 须在项目设计的早期阶段加入,并作为工作流中的关键环节。如果出于性能优化目的而加入,会对项目架构造成较大影响。
JSON基本是所有平台的基础设施,无部署成本。
DIMBIN只需要安装一个软件包,但是需要数据结构扁平化,如果数据结构无法被扁平化,将无法从中受益。
在JS中使用时:
-
使用JSON序列化反序列化的代码行数基本在5以内
-
使用DIMBIN则10行左右
-
使用protocol需要单独编写schema(proto)文件,引入编译出的几百行代码,序列化和反序列化时,需要通过面向对象风格的接口操作每个节点的数据(数据结构上的每个节点都是一个对象)
-
使用flatbuffer需要单独编写schema(fbs)文件,引入编译出的几百行代码,序列化过程需要通过状态机风格的接口处理每个节点,手动转换并放入每个节点的数据,书写体验比较磨人;反序列化过程通过对象操作接口读取每个节点的数据
性能(JS环境)
Protocol官网声称性能高于JSON,该测试数据显然不是JS端的,我们的测试表明其JS端性相对于JSON更差(数据量大的时候差的多)。
所有的二进制方案处理字符串的过程都是类似的:需要将js中的utf16先解码成unicode,再编码成utf8,写入buffer,并记录每个字符串的数据地址。该过程性能消耗较大,而且如果不使用varint(protocol buffers)的话,体积也没有任何优势。
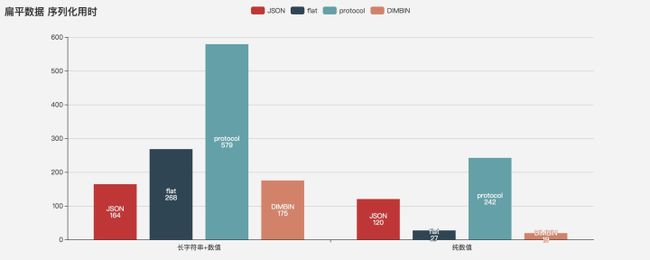
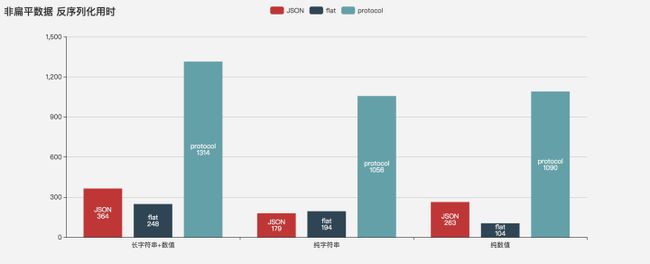
在处理字符串数据时,JSON的性能总是最好的,序列化性能 JSON > DIMBIN > flatbuffers > proto,反序列化 JSON > proto > DIMBIN > flatbuffers
处理数值数据时 Flatbuffers 和 DIMBIN 性能优势明显,
对于扁平化数值数据的序列化性能 DIMBIN > flatbuffers > JSON > proto,
反序列化 DIMBIN > flatbuffers >十万倍> JSON > proto
体积
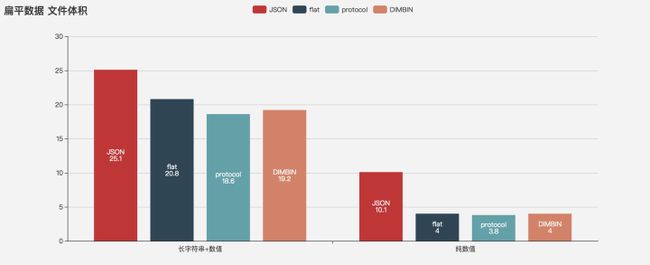
使用字符串与数值混合结构或者纯数值时,protocol < DIMBIN < flat < JSON 使用纯字符串时,JSON最小,二进制方案都比较大
Gzip之后,DIMBIN和flat的体积最小且基本一致,protocol反而没有优势,猜测可能是varint的副作用。
表达力
Protocol 为强类型语言而设计,所支持的类型比JSON要丰富的多,数据结构也可以十分复杂; Flatbuffers 支持 数值/布尔值/字符串 三种基本类型,结构与JSON类似; DIMBIN 支持 数值/布尔值/字符串 三种基本类型,目前只支持多维数组的结构(暂不支持也不鼓励使用键值对),更复杂的结构需要在其上封装。
自由度
JSON和DIMBIN都是自描述的,(弱类型语言中)不需要schema,用户可以动态生成数据结构和数据类型,生产方和消费方之间约定好即可,如果需要类型检查则需要在上层封装。
Protocolbuffers 和 flatbuffers 必须在编码前先写好IDL并生成对应的代码,接口修改则需修改IDL并重新生成代码、部署到生产端和消费端、再基于其上进行编码。
-
Protocolbuffers的C++和java实现中有自描述的特性,可以嵌入.proto文件,但是依然需要编译一个顶层接口来描述这个“自描述的内嵌数据”,基本没有实用性,其文档中也说Google内部从来没有这样用过(不符合IDL的设计原则)。
-
flatbuffers 有一个自描述版本的分支(flexbuffers),试验阶段,无JS支持,无相关文档。
多语言支持
Protocolbuffers 和 flatbuffers 服务端与客户端语言支持都非常完整。两者优先针对C++/Java(android)/Python开发,JS端缺少一部分高级功能,无完整文档,需要自己研究example和生成的代码,不过代码不长,注释覆盖完整。
JSON基本上所有编程语言都有对应的工具。
DIMBIN针对JS/TS开发和优化,目前提供c#版本,c++、wasm、java和python的支持在计划中。
用例(仅测试JS环境)
我们生成一份典型的数据,使用扁平化和非扁平化两种结构,使用JSON、DIMBIN、protocol和flat buffers来实现相同的功能,对比各种方案的性能、体积以及便捷程度。
测试数据
我们生成两个版本的测试数据:非扁平化(多层键值对结构)数据和等效的扁平化(多维数组)数据
考虑到字符串处理的特殊性,在测试时我们分开测试了 字符串/数值混合数据、纯字符串数据,和纯数值数据
// 非扁平化数据
export const data = {
items: [
{
position: [0, 0, 0],
index: 0,
info: {
a: 'text text text...',
b: 10.12,
},
},
// * 200,000 个
],
}
// 等效的扁平化数据
export const flattedData = {
positions: [0, 0, 0, 0, 0, 1, ...],
indices: [0, 1, ...],
info_a: ['text text text', 'text', ...],
info_b: [10.12, 12.04, ...],
}JSON
序列化
const jsonSerialize = () => {
return JSON.stringify(data)
}反序列化
const jsonParse = str => {
const _data = JSON.parse(str)
let _read = null
// 由于flat buffers的读取操作是延后的,因此这里需要主动读取数据来保证测试的公平性
const len = _data.items.length
for (let i = 0; i < len; i++) {
const item = _data.items[i]
_read = item.info.a
_read = item.info.b
_read = item.index
_read = item.position
}
}DIMBIN
序列化
import DIMBIN from 'src/dimbin'
const dimbinSerialize = () => {
return DIMBIN.serialize([
new Float32Array(flattedData.positions),
new Int32Array(flattedData.indices),
DIMBIN.stringsSerialize(flattedData.info_a),
new Float32Array(flattedData.info_b),
])
}反序列化
const dimbinParse = buffer => {
const dim = DIMBIN.parse(buffer)
const result = {
positions: dim[0],
indices: dim[1],
info_a: DIMBIN.stringsParse(dim[2]),
info_b: dim[3],
}
}DIMBIN目前仅支持多维数组,不能处理树状数据结构,这里不做对比。
Protocol Buffers
schema
首先需要按照proto3语法编写schema
syntax = "proto3";
message Info {
string a = 1;
float b = 2;
}
message Item {
repeated float position = 1;
int32 index = 2;
Info info = 3;
}
message Data {
repeated Item items = 1;
}
message FlattedData {
repeated float positions = 1;
repeated int32 indices = 2;
repeated string info_a = 3;
repeated float info_b = 4;
}编译成js
使用 protoc 编译器将schema编译成JS模块
./lib/protoc-3.8.0-osx-x86_64/bin/protoc ./src/data.proto --js_out=import_style=commonjs,,binary:./src/generated
序列化
// 引入编译好的JS模块
const messages = require('src/generated/src/data_pb.js')
const protoSerialize = () => {
// 顶层节点
const pbData = new messages.Data()
data.items.forEach(item => {
// 节点
const pbInfo = new messages.Info()
// 节点写入数据
pbInfo.setA(item.info.a)
pbInfo.setB(item.info.b)
// 子级节点
const pbItem = new messages.Item()
pbItem.setInfo(pbInfo)
pbItem.setIndex(item.index)
pbItem.setPositionList(item.position)
pbData.addItems(pbItem)
})
// 序列化
const buffer = pbData.serializeBinary()
return buffer
// 扁平化方案:
// const pbData = new messages.FlattedData()
// pbData.setPositionsList(flattedData.positions)
// pbData.setIndicesList(flattedData.indices)
// pbData.setInfoAList(flattedData.info_a)
// pbData.setInfoBList(flattedData.info_b)
// const buffer = pbData.serializeBinary()
// return buffer
}反序列化
// 引入编译好的JS模块
const messages = require('src/generated/src/data_pb.js')
const protoParse = buffer => {
const _data = messages.Data.deserializeBinary(buffer)
let _read = null
const items = _data.getItemsList()
for (let i = 0; i < items.length; i++) {
const item = items[i]
const info = item.getInfo()
_read = info.getA()
_read = info.getB()
_read = item.getIndex()
_read = item.getPositionList()
}
// 扁平化方案:
// const _data = messages.FlattedData.deserializeBinary(buffer)
// // 读数据(避免延迟读取带来的标定误差)
// let _read = null
// _read = _data.getPositionsList()
// _read = _data.getIndicesList()
// _read = _data.getInfoAList()
// _read = _data.getInfoBList()
}Flat buffers
schema
首先需要按照proto3语法编写schema
table Info {
a: string;
b: float;
}
table Item {
position: [float];
index: int;
info: Info;
}
table Data {
items: [Item];
}
table FlattedData {
positions:[float];
indices:[int];
info_a:[string];
info_b:[float];
}编译成js
./lib/flatbuffers-1.11.0/flatc -o ./src/generated/ --js --binary ./src/data.fbs
序列化
// 首先引入基础库
const flatbuffers = require('flatbuffers').flatbuffers
// 然后引入编译出的JS模块
const tables = require('src/generated/data_generated.js')
const flatbufferSerialize = () => {
const builder = new flatbuffers.Builder(0)
const items = []
data.items.forEach(item => {
let a = null
// 字符串处理
if (item.info.a) {
a = builder.createString(item.info.a)
}
// 开始操作 info 节点
tables.Info.startInfo(builder)
// 添加数值
item.info.a && tables.Info.addA(builder, a)
tables.Info.addB(builder, item.info.b)
// 完成操作info节点
const fbInfo = tables.Info.endInfo(builder)
// 数组处理
let position = null
if (item.position) {
position = tables.Item.createPositionVector(builder, item.position)
}
// 开始操作item节点
tables.Item.startItem(builder)
// 写入数据
item.position && tables.Item.addPosition(builder, position)
item.index && tables.Item.addIndex(builder, item.index)
tables.Item.addInfo(builder, fbInfo)
// 完成info节点
const fbItem = tables.Item.endItem(builder)
items.push(fbItem)
})
// 数组处理
const pbItems = tables.Data.createItemsVector(builder, items)
// 开始操作data节点
tables.Data.startData(builder)
// 写入数据
tables.Data.addItems(builder, pbItems)
// 完成操作
const fbData = tables.Data.endData(builder)
// 完成所有操作
builder.finish(fbData)
// 输出
// @NOTE 这个buffer是有偏移量的
// return builder.asUint8Array().buffer
return builder.asUint8Array().slice().buffer
// 扁平化方案:
// const builder = new flatbuffers.Builder(0)
// const pbPositions = tables.FlattedData.createPositionsVector(builder, flattedData.positions)
// const pbIndices = tables.FlattedData.createIndicesVector(builder, flattedData.indices)
// const pbInfoB = tables.FlattedData.createInfoBVector(builder, flattedData.info_b)
// const infoAs = []
// for (let i = 0; i < flattedData.info_a.length; i++) {
// const str = flattedData.info_a[i]
// if (str) {
// const a = builder.createString(str)
// infoAs.push(a)
// }
// }
// const pbInfoA = tables.FlattedData.createInfoAVector(builder, infoAs)
// tables.FlattedData.startFlattedData(builder)
// tables.FlattedData.addPositions(builder, pbPositions)
// tables.FlattedData.addIndices(builder, pbIndices)
// tables.FlattedData.addInfoA(builder, pbInfoA)
// tables.FlattedData.addInfoB(builder, pbInfoB)
// const fbData = tables.FlattedData.endFlattedData(builder)
// builder.finish(fbData)
// // 这个buffer是有偏移量的
// return builder.asUint8Array().slice().buffer
// // return builder.asUint8Array().buffer
}反序列化
// 首先引入基础库
const flatbuffers = require('flatbuffers').flatbuffers
// 然后引入编译出的JS模块
const tables = require('src/generated/data_generated.js')
const flatbufferParse = buffer => {
buffer = new Uint8Array(buffer)
buffer = new flatbuffers.ByteBuffer(buffer)
const _data = tables.Data.getRootAsData(buffer)
// 读数据(flatbuffer在解析时并不读取数据,因此这里需要主动读)
let _read = null
const len = _data.itemsLength()
for (let i = 0; i < len; i++) {
const item = _data.items(i)
const info = item.info()
_read = info.a()
_read = info.b()
_read = item.index()
_read = item.positionArray()
}
// 扁平化方案:
// buffer = new Uint8Array(buffer)
// buffer = new flatbuffers.ByteBuffer(buffer)
// const _data = tables.FlattedData.getRootAsFlattedData(buffer)
// // 读数据(flatbuffer是使用get函数延迟读取的,因此这里需要主动读取数据)
// let _read = null
// _read = _data.positionsArray()
// _read = _data.indicesArray()
// _read = _data.infoBArray()
// const len = _data.infoALength()
// for (let i = 0; i < len; i++) {
// _read = _data.infoA(i)
// }
}Flatbuffers 对字符串的解析性能较差,当数据中的字符串占比较高时,其整体序列化性能、解析性能和体积都不如JSON,对于纯数值数据,相对于JSON优势明显。其状态机一般的接口设计对于复杂数据结构的构建比较繁琐。
性能指标
测试环境:15' MBP mid 2015,2.2 GHz Intel Core i7,16 GB 1600 MHz DDR3,macOS 10.14.3,Chrome 75
测试数据:上面例子中的数据,200,000条,字符串使用 UUID*2
测试方式:运行10次取平均值,GZip使用默认配置 gzip ./*
单位:时间 ms,体积 Mb
-
字符串在数据中的占比、单个字符串的长度,以及字符串中unicode的数值大小,都会对测试造成影响。
-
由于DIMBIN针对扁平化数据而设计,因此非扁平化数据只测试了JSON/protocol/flatbuffers
序列化性能

反序列化性能

空间占用



选型建议
从测试结果来看,如果你的场景对性能有较高要求,将数据扁平化总是明智的原则。
-
数据量小、快速迭代、包含大量字符串数据,使用JSON,方便快捷;
-
数据量小、接口稳定、静态语言主导、多语言协作、集成IDL、依赖gPRC,考虑 protocol buffers。
-
数据量大、接口稳定、静态语言主导、集成IDL、数据无法扁平化,考虑 flat buffers。
-
数据量大、快速迭代、性能要求高、数据可以扁平化,不希望使用重量级工具或修改工程结构,考虑DIMBIN。
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,编解码,推拉流,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓