dex文件全解析C语言,中篇
文章目录
- 前言(必读)
- 一、DEX文件头及其详解
-
- 拿到简单dex文件的强烈建议
- 二、DexStringId
- 三:DexTypeId
- 四:DexProtoId
- 五:DexFieldId
- 六:DexMethodId
- 总结
前言(必读)
在上篇文章中我们完成了对dex中的特殊字符串格式解析,不了解这个的可以看一下上篇文章,本篇将直接使用上篇的代码进一步进行解析,链接如下:dex文件MUTF-8字符串提取
本篇我们主要解析除了类及其相关结构(DexClassDef)之外的所有其余结构内容,主要包括:DexStringId,DexTypeId,DexProtoId,DexFieldId,DexMethodId,由于类本身最为复杂且包含方法的指令偏移等逆向所需的重要信息,我们放在后篇中单独着重讲解,方便之后的运行时修改内存指令
(小小的大贴士:类解析这东西真的是把我折磨没了,前几个加起来都没它这么折磨,不过问题不大,咱逆向不就有点找虐那意思嘛)(狗头保命ing)
小贴士:本篇需要读者对C语言尤其指针有一定深度的了解,全篇在VS的x86下运行,指针长度和int相同,其余有疑问部分欢迎留言提问,指导。
同时,由于结构的灵活性,我在原始结构的基础上有些许变化,但都是为了解析方便,代码测试无问题,放心食用
一、DEX文件头及其详解
dex文件头的定义如下
此处需要告知读者,我是直接从头拿到各个类型的数量和偏移,不通过map_off,有兴趣的读者可自行实现
文中每一个偏移都是相对文件起始位置,一定一定记得加上基址再操作,否则,直接螺旋升天
struct dexHeader {
char magic[8];
int checksum;
char signature[20];
int file_size;
int header_size;
int endian_tag;
int link_size;
int link_off;
int map_off;
int string_ids_size;
int string_ids_off;//存储偏移->dexStringId
int type_ids_size;
int type_ids_off;
int proto_ids_size;
int proto_ids_off;
int field_ids_size;
int field_ids_off;
int method_ids_size;
int method_ids_off;
int class_defs_size;
int class_defs_off;
int data_size;
int data_off;
};
当然,前提是我们需要一个dex文件,读者可自行下载安装androidStudio,注意不要打断androidStudio的安装过程,等它自己结束,编译工程,拿到apk,解压缩apk拿到dex文件,但这个文件中各中结构数量过多,不利于手动解析,排错。
拿到简单dex文件的强烈建议
读者安装androidStudio之后,写一个简单的java类,例如:HelloWorld,使用jdk编译为java字节码,找到androidStudio的sdk位置,打开build-tools中的bin文件夹,以HelloWorld.class为例,使用命令
java -jar dx.jar --dex --output HelloWorld.dex HelloWorld.class就可以拿到这个java字节码的dalvik字节码文件啦。
接着就是读入文件到缓冲之中,使用指针指向缓冲头部,而后,就可以拿到每一个结构的数量和偏移啦,代码如下:
FILE* fp;
int test = fopen_s(&fp,"Hello.dex","rb+");
if (test) {
printf("文件打开失败\n");
return 0;
}
fseek(fp, 0, SEEK_END);
int sizeOfFile = ftell(fp);
void* buffer = malloc(sizeOfFile);
if (buffer == NULL) {
fclose(fp);
printf("空间申请失败\n");
return 0;
}
fseek(fp, 0, SEEK_SET);
fread(buffer, sizeOfFile, 1, fp);
fclose(fp);
struct dexHeader* head = (struct dexHeader*)buffer;
二、DexStringId
DexStringId官方定义如下:
struct DexStringId {
u4 stringDataOff
};
我对它这样定义
struct stringsId {
//这个变量不存在,真实为指向不定长的char数组的偏移,正好贴合指针
char* content;
};
这里需要注意了,我们从head里拿到的是一个指向DexStringId的偏移,而这个结构同时也是一个偏移,它指向的是真正的MUTF-8字符串,我对这个地方的处理:先将head中的偏移加缓冲基址赋值给结构体指针,同时,对于结构体的content,再对其加上基址,也就是真正的MUTF-8位置了,代码如下:
int stringSize = head->string_ids_size;
//注意此处指针,string为二级指针,别的项为一级指针
struct stringsId* stringTable = (struct stringsId*)((char*)buffer + (head->string_ids_off));
//加基地址,此处是一个二级指针,较为特殊
stringTable->content += (int)buffer;
char* stringPosition = stringTable->content;
char** trueString = (char**)malloc(stringSize * sizeof(int));
stringPosition为缓冲中string的位置,trueString为提取出的位置,本文对其余结构提取的变量命名都是类似的
接着依次调用字符串提取算法,拿到字符串,赋值给我们的trueString,
代码如下:
struct uleb128 a;
//遍历string
for (int i = 0; i < stringSize; i++) {
a = Uleb128(stringPosition);
trueString[i] = a.content;
stringPosition += (a.lengthOfHead + a.lengthOfString+1);
}
好的,DexStringId我们就提取机结束了,
我们在这里对字符串采用输出操作,输出每一个字符的原因是将换行输出为’\n’的形式,方便观看,使用完毕记得free掉空间,代码如下:(所有内容输出结果附图在最后)
printf("------------------\n");
printf("-----Strings------\n");
for (int i = 0; i < stringSize; i++) {
printf("string %d is ", i);
int count = strlen(trueString[i]);
for (int j = 0; j < count; j++) {
if (trueString[i][j] == '\n') {
printf("\\");
printf("n");
}
else {
printf("%c",trueString[i][j]);
}
}
printf("\n");
free(trueString[i]);
trueString[i] = NULL;
}
三:DexTypeId
DexTypeId定义如下,也就是说,每一个结构都是一个int值:
结构体意义:指向string列表下标,表示一个类型
struct dexTypeId {
int indexOfStringTable;
};
我们此处不使用这个定义进行操作,而是直接定义一个int指针,指向head中的type_ids_off,加上基址,直接操作起来,直接进行提取,不care官方定义,代码如下,老规矩,老变量名命名想法:
int typeSize = head->type_ids_size;
int* typePosition= (int*)((char*)buffer + (head->type_ids_off));
char** trueType = (char**)malloc(typeSize * sizeof(int));
为啥是个char** 呢,因为这个结构体本身是指向string的一个整数,那我直接申请typeSize个指针,这不就是一个type表格了吗,对吧,同时,我直接让指针每一项指向trueString对应的type存储的下标,这岂不美哉,代码如下:
for (int i = 0; i < typeSize; i++) {
trueType[i] = trueString[*(typePosition++)];
}
而后,输出,free空间,巴适得很
printf("------------------\n");
printf("-----typeIds------\n");
for (int i = 0; i < typeSize; i++) {
printf("type %d is %s\n",i,trueType[i]);
}
free(trueType);
trueType=NULL;
四:DexProtoId
DexProtoId它是本篇中最难的结构,官方定义如下,
结构体意义:对一个方法的声明,返回值,参数列表,可以直接理解为一个方法的声明
struct DexProtoId{
u4 shortyIdx;
u4 returnTypeidx;
u4 parameterOff;//DexTypeList的偏移
}
struct DexTypeList{
u4 size;//接下来的DexTypeItem数量
DexTypeItem[1];
}
struct DexTypeItem{
u2 typeIdx;
}
自定义如下:
struct dexProtoTypeId {
int indexOfStringTable;//一个函数声明的字符串
int indexOfTypeTable;//return type
//注意使用时加上基址,否则直接崩盘,指针 不需要重新赋值
struct dexTypeList* offsetOfTypeList;
};
struct dexTypeList {
int sizeOfTypeItem;
//short*需要重新赋值为address of struct+4
short* indexOfType;
};
自定义的话,就比较随便啦,咱就是怎么方便怎么来。
你指向列表吗不是,我直接定义成自己的列表的指针,反正都是一样大小。
你不知道short有多大吗不是,我直接short指针,无非用的时候重新赋值一下,赋值为本结构体所在位置加4即可。
希望大家好好揣摩理解一下,这里没有问题的。
接着就是提取,显示啦,
int protoSize = head->proto_ids_size;
struct dexProtoTypeId*protoPosition= (struct dexProtoTypeId*)((char*)buffer + (head->proto_ids_off));
struct dexProtoTypeId* trueProto = (struct dexProtoTypeId*)malloc(sizeof(struct dexProtoTypeId) * protoSize);
for (int i = 0; i < protoSize; i++) {
trueProto[i].indexOfStringTable = protoPosition->indexOfStringTable;
trueProto[i].indexOfTypeTable = protoPosition->indexOfTypeTable;
if (protoPosition->offsetOfTypeList == 0) {
trueProto[i].offsetOfTypeList = NULL;
protoPosition++;
continue;
}
struct dexTypeList*tmp= (struct dexTypeList*)((char*)buffer + (int)protoPosition->offsetOfTypeList);
struct dexTypeList* typeList =(struct dexTypeList*)malloc(sizeof(struct dexTypeList));
short* dexFileTypeList = (short*)((char*)tmp + 4);
typeList->sizeOfTypeItem = tmp->sizeOfTypeItem;
typeList->indexOfType = malloc(sizeof(short) * tmp->sizeOfTypeItem);
for (int j = 0; j < tmp->sizeOfTypeItem;j++ ) {
typeList->indexOfType[j] = dexFileTypeList[j];
}
trueProto[i].offsetOfTypeList = typeList;
protoPosition++;
}
注意:如果指向参数列表的偏移为零,这个方法是没有参数的,就这一点坑
接着是输出和空间的释放,简单看一下,代码:
printf("------------------\n");
printf("-----protoIds------\n");
printf("声明 返回值 参数列表\n");
for (int i = 0; i < protoSize; i++) {
printf("%d %s %d %s ", trueProto[i].indexOfStringTable, trueString[trueProto[i].indexOfStringTable],
trueProto[i].indexOfTypeTable, trueType[trueProto[i].indexOfTypeTable]);
if (trueProto[i].offsetOfTypeList != NULL) {
for (int j = 0; j < trueProto[i].offsetOfTypeList->sizeOfTypeItem; j++) {
printf("%d %s ", trueProto[i].offsetOfTypeList->indexOfType[j], trueType[trueProto[i].offsetOfTypeList->indexOfType[j]]);
}
free(trueProto[i].offsetOfTypeList);
printf("\n");
}
else {
printf("no param\n");
}
}
free(trueProto);
五:DexFieldId
DexFieldId官方定义:
(字段意义:描述一个成员变量所属类,字段类型和变量名)
struct DexFieldId{
u2 classIdx;
u2 typeIdx;
u4 nameIdx;
}
自定义也就直接使用啦,无非转为short和int类型,还是老变量名命名,加上解析代码:
int fieldSize = head->field_ids_size;
struct dexFieldId*fieldPosition= (struct dexFieldId*)((char*)buffer + (head->field_ids_off));
struct dexFieldId* trueField =(struct dexFieldId*) malloc(sizeof(struct dexFieldId) * fieldSize);
for (int i = 0; i < fieldSize; i++) {
trueField[i].classId=fieldPosition->classId;
trueField[i].typeId = fieldPosition->typeId;
trueField[i].nameId = fieldPosition->nameId;
fieldPosition++;
}
输出和释放空间如下:
printf("------------------\n");
printf("-----fieldIds------\n");
printf("-----ClassName field's type field's name------\n");
for (int i = 0; i < fieldSize; i++) {
printf("%d %s %d %s %d %s\n", trueField[i].classId, trueType[trueField[i].classId],
trueField[i].typeId, trueType[trueField[i].typeId], trueField[i].nameId, trueString[trueField[i].nameId]);
}
free(trueField);
六:DexMethodId
DexMethodId官方定义如下:
结构意义:指定一个方法所属类,声明,方法名,当然,声明就自然是上边proto的下标啦
struct DexMethodId{
u2 classIdx;//DexTypeId的下标
u2 protoIdx;//DexProtoId的下标
u4 nameIdx;//DexStringId下标
}
自定义的结构也一样啦,就是变一下short和int的区别,定义和提取如下,还是老的命名规则:
int methodSize = head->method_ids_size;
struct dexMethodId* methodPosition = (struct dexMethodId*)((char*)buffer + (head->method_ids_off));
struct dexMethodId* trueMethod = (struct dexMethodId*)malloc(sizeof(struct dexMethodId) * methodSize);
for (int i = 0; i < methodSize; i++) {
trueMethod[i].classId = methodPosition->classId;
trueMethod[i].protoId = methodPosition->protoId;
trueMethod[i].nameId = methodPosition->nameId;
methodPosition++;
}
接着是输出和释放,代码:
printf("------------------\n");
printf("-----methodIds------\n");
printf("classIndex protoIndex stringIndex\n");
for (int i = 0; i < methodSize; i++) {
printf(" %d ", trueMethod[i].classId);
//只输出proto声明
printf(" %d ", trueMethod[i].protoId);
printf(" %d ", trueMethod[i].nameId);
printf("(%s)%s--->%s\n", trueString[trueProto[trueMethod[i].protoId].indexOfStringTable], trueType[trueMethod[i].classId],
trueString[trueMethod[i].nameId]);
}
free(trueMethod);
结束,完美收官,再贴一个运行截图叭,
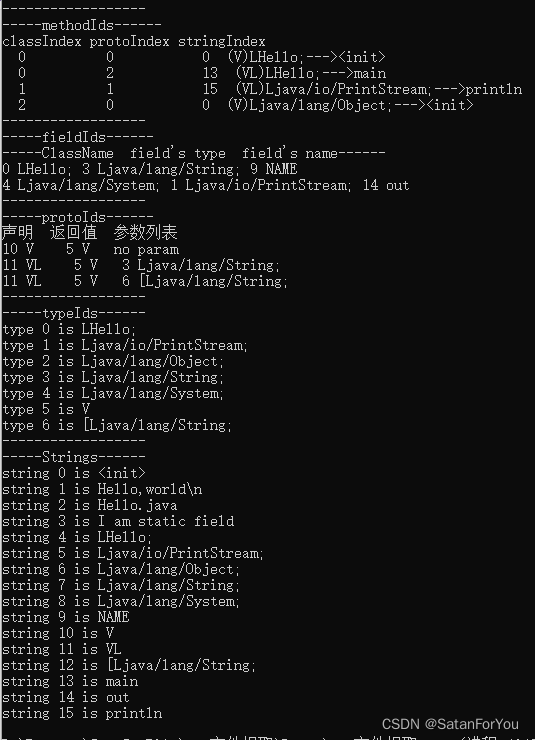
总结
小贴士:对于上述解析的结构,它们都是连续存放的,所以指针直接加1就可以指向下一个啦,它们的子结构啦之类的,都是偏移,不需要care的,我有手动解析过dex,下一篇是解析DexClassDef哦,逆向的重中之重,也是函数抽取技术的基础
代码就不贴给大家了,上边的整合一下也就可以拿得到,自己写出来真的很重要,很重要,后边解析DexClassDef时加个链接直接整个全部文件一起叭,结束!巴适得很。
(DexClassDef解析的内容在这里:Dex文件解析,后篇)
欢迎大家指导,纠错。