注意力机制Attention Mechanism:从Seq2Seq到BERT
目录
- 前言
- 注意力机制的发展
-
- LSTM和GRU
-
- LSTM和LSTMcell
- BiLSTM
- GRU(待更新)
- Seq2seq
-
- 机器翻译的例子
- encoder
- decoder
- Seq2seq+Attention
- Attention 和 Self Attention理解
-
- Attention
- Self-Attention
- Transformer
-
- 整体流程(以机器翻译为例)
- Encoder
- Q、K、V的计算
- Decoder
- Positional Encoding
- 优点
- 缺点
- BERT
-
- 核心过程
- 输入表征
- Pre-Train过程
- Fine tuning过程
- 一些疑问及解答
- 待更新。。。
前言
先前做项目用到了图的Attention机制,比较著名的有图注意力网络GATs。之前做CV的时候也用到了注意力机制相关的算法,比如Image Caption。在这里对Soft-Attention和Self-Attention做一些理解性的from scratch介绍。
注意力机制的发展
LSTM和GRU
参考:
Understanding LSTM Networks
理解LSTM
LSTM神经网络输入输出究竟是怎样的?
LSTM的结构中,h0和c0是分别代表hidden_0和cell_0的意思吗?在网络中分别传递了什么? - FreakAlexia的回答 - 知乎

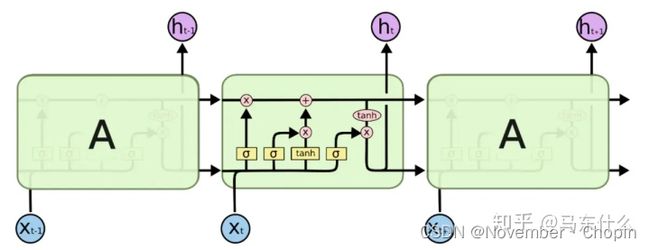
其中 s ( t ) s(t) s(t) 代表了长时记忆,而下面的 h ( t ) h(t) h(t) 则代表了工作记忆或短时记忆。
LSTM和LSTMcell
参考:LSTM和LSTMCELL
LSTMCEll就是LSTM的物理结构,也就是:


RNN无法解决长期依赖问题,输出和前面很长一段序列有关。LSTM则设计用来解决这种问题,LSTM相比RNN来说,就是添加了三个门:遗忘门,输入门,输出门。
- 遗忘门:决定从细胞状态中丢弃什么信息
- 输入门:决定让多少新的信息加入细胞状态,这一步将输出细胞状态
- 输出门:确定输出值,该输出值基于细胞状态
LSTM是LSTMcell在时间上的扩展:
BiLSTM
详解BiLSTM及代码实现
通过BiLSTM可以更好的捕捉双向的语义依赖
(1) 双向LSTM编码句子
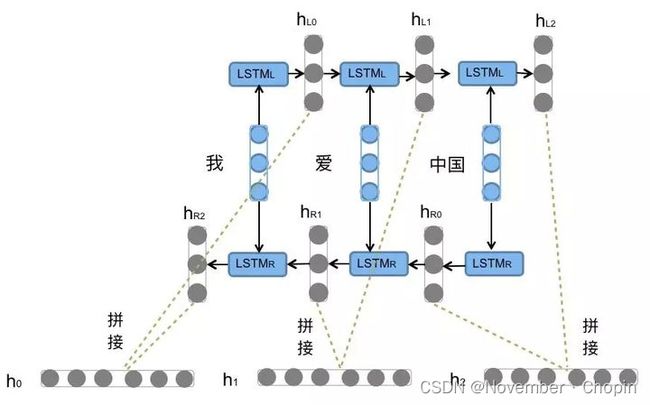
(2) 拼接向量用于情感分类

GRU(待更新)
Seq2seq
参考:Seq2Seq模型概述
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
seq2seq属于encoder-decoder结构的一种,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。
机器翻译的例子

encoder
encoder将的输入序列压缩性指定长度的向量,分为:
- 直接将最后一个输入的隐状态作为语义向量C
- 对最后一个隐含状态做一个变换得到语义向量C
- 将输入序列的所有隐含状态做一个变换得到语义变量C
RNN网络为

decoder
decoder负责根据语义向量生成指定的序列。最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。每个y会依次产生。

decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。

Seq2seq+Attention
参考:完全解析RNN, Seq2Seq, Attention注意力机制
Seq2Seq结构:

Seq2Seq+Attention结构:

Attention 和 Self Attention理解
参考:知乎-目前主流的attention方法都有哪些?
Attention

以中英翻译为例, < S o u r c e , T a r g e t >
S o u r c e = < x 1 , x 2 , … , x m > Source=<\bold{x}_1,\bold{x}_2,\ldots,\bold{x}_m> Source=<x1,x2,…,xm>
T r a g e t = < y 1 , y 2 , … , y n > Traget=<\bold{y}_1,\bold{y}_2,\ldots,\bold{y}_n> Traget=<y1,y2,…,yn>
本质:将Source中的构成元素想象成是由一系列的 < K e y , V a l u e >
也可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。
Self-Attention
Self Attention也经常被称为intra Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已。
Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图11展示的有一定距离的短语结构)或者语义特征。
Transformer
讲得比较好的博客:
[1] NLP中的Attention原理和源码解析
[2] Transformer模型详解
[3] 【NLP】Transformer模型原理详解
在整个 Transformer 架构中,它只使用了注意力机制和全连接层来处理文本,此外,Transformer 中最重要的就是Self-Attention,这种在序列内部执行 Attention 的方法可以视为搜索序列内部的隐藏关系,这种内部关系对于翻译以及序列任务的性能有显著提升。与RNNs不同的是,Transformers 一次处理所有输入,允许并行化。(这也导致了Transformer忽略了时序信息,因为需要PE。)
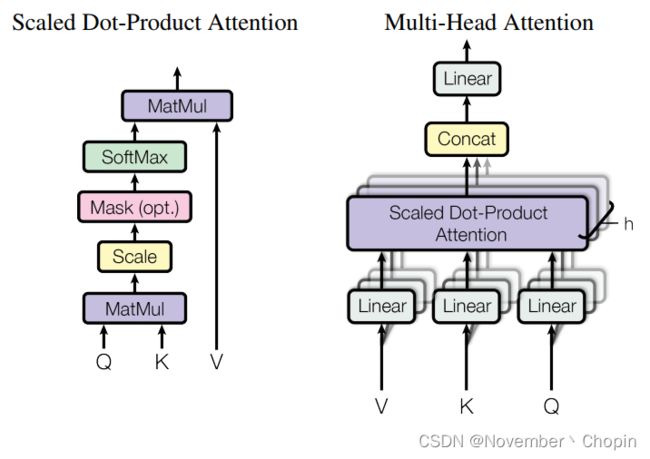
如 Seq2Seq 一样,原版 Transformer 也采用了编码器-解码器框架,但它们会使用多个 Multi-Head Attention、前馈网络、Layer Norm 和残差连接等。下图从左到右展示了原论文所提出的 Transformer 架构、Multi-Head Attention 和点乘注意力。本文只简要介绍这三部分的基本概念与结构,更详细的 Transformer 解释与实现请查看机器之心的 GitHub 项目:基于注意力机制,机器之心带你理解与训练神经机器翻译系统 。
其中点乘注意力是注意力机制的一般表达形式,将多个点乘注意力叠加在一起可以组成 Transformer 中最重要的 Multi-Head Attention 模块,多个 Multi-Head Attention 模块堆叠在一起就组成了 Transformer 的主体结构,并借此抽取文本中的信息。

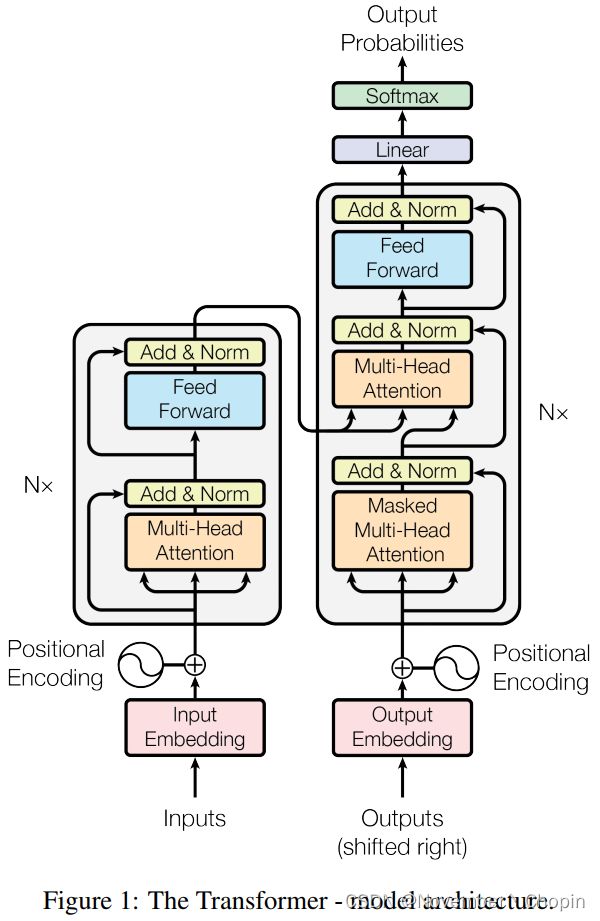
大多数seq2seq模型一样,Transformer的结构也是由encoder和decoder组成。
整体流程(以机器翻译为例)
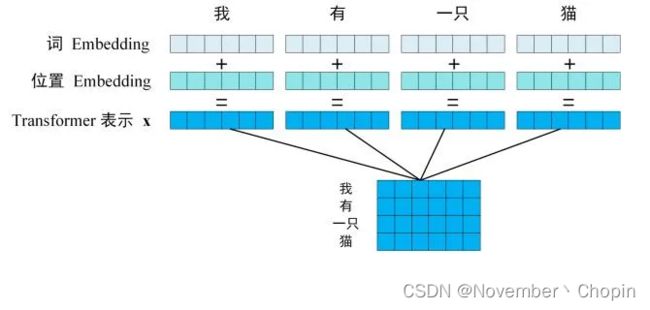
- 第1步:获取输入句子的每一个单词的表示向量 X,X 由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。 (如下图所示,每一行是一个单词的表示 x)
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
- 第2步:将得到的单词表示向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C C C,如下图。词向量矩阵用 X n × d X_{n\times d} Xn×d 表示, n n n 是句子中单词个数, d d d 是表示向量的维度 (论文中 d = 512 d=512 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。

- 第三步:将 Encoder 输出的编码信息矩阵 C C C 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1 i 1~ i 1 i 翻译下一个单词 i + 1 i+1 i+1,如下图所示。在使用的过程中,翻译到单词 i + 1 i+1 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i + 1 i+1 i+1 之后的单词。

上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。(更新输入和输出不等长、语法句式非顺序的解决方案。)
Encoder
由6个相同的Layer组成,每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了残差和norm,因此可以将sub-layer的输出表示为:
s u b _ l a y e r _ o u t p u t = L a y e r N o r m ( x + ( S u b L a y e r ( x ) ) ) sub\_layer\_output=LayerNorm(x+(SubLayer(x))) sub_layer_output=LayerNorm(x+(SubLayer(x)))接下来按顺序解释一下这两个sub-layer:
-
Multi-head self-attention
attention可由以下形式表示:
a t t e n t i o n _ o u t p u t = A t t e n t i o n ( Q , K , V ) attention\_output=Attention(Q,K,V) attention_output=Attention(Q,K,V) multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W O MultiHead(Q,K,V)=Concat(head_1,\ldots,head_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO其中, h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV),self-attention取 Q , K , V Q,K,V Q,K,V相同。
文章中attention的计算采用了scaled dot-product,即:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax({\frac {QK^T} {\sqrt{d_k}}} )V Attention(Q,K,V)=softmax(dkQKT)V 作者同样提到了另一种复杂度相似但计算方法additive attention,在 d k \sqrt{d_k} dk 很小的时候和dot-product结果相似, d k \sqrt{d_k} dk 大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小,具体可见论文中的引用)。 -
Position-wise feed-forward networks
这层主要是提供非线性变换。Attention输出的维度是 [ b a t c h _ s i z e ∗ s e q _ l e n , n u m _ h e a d s ∗ h e a d _ s i z e ] [batch\_size*seq\_len, num\_heads*head\_size] [batch_size∗seq_len,num_heads∗head_size],第二个sub-layer是个全连接层,之所以是position-wise是因为过线性层时每个位置i的变换参数是一样的。
Q、K、V的计算
Self-Attention 的输入矩阵为 X X X ,使用线性变阵矩阵 W Q WQ WQ, W K WK WK, W V WV WV计算得到 Q Q Q, K K K, V V V。 X X X, Q Q Q, K K K, V V V 的每一行都表示一个单词。

Decoder
Decoder和Encoder的结构差不多,相比于Decoder多了一个attention的sub-layer,如上图所示。decoder的输入输出和解码过程:
- 输出:对应位置 i i i的输出词的概率分布
- 输入:encoder的输出 和 对应位置 i − 1 i-1 i−1 decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出。
- 解码:这里要注意一下,训练和预测是不一样的。在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token);而预测时,因为没有ground truth了,需要一个个预测。
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
加了mask的attention原理如图(右侧的Multi-Head Attention由几个并行运行的attention layers组成。)
Positional Encoding

第 t t t 个位置的Position Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
这里作者提到了两种方法:
- 用不同频率的sine和cosine函数直接计算
- 学习出一份positional embedding(参考:Convolutional Sequence to Sequence Learning)
经过实验发现两者的结果一样,所以最后选择了第一种方法,公式如下:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel) 作者提到,方法1的好处有两点:
- 对任意位置的 P E p o s + k PE_{pos+k} PEpos+k 都可以被 P E p o s PE_{pos} PEpos 的线性函数表示,三角函数的特性如下:
c o s ( α + β ) = c o s ( α ) c o s ( β ) − s i n ( α ) s i n ( β ) s i n ( α + β ) = s i n ( α ) c o s ( β ) + c o s ( α ) s i n ( β ) cos(\alpha+\beta)=cos(\alpha)cos(\beta)-sin(\alpha)sin(\beta) \\ sin(\alpha+\beta)=sin(\alpha)cos(\beta)+cos(\alpha)sin(\beta) \\ cos(α+β)=cos(α)cos(β)−sin(α)sin(β)sin(α+β)=sin(α)cos(β)+cos(α)sin(β) - 如果是学习到的positional embedding,(个人认为,没看论文)会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。待验证!
优点
- 计算复杂度
- 并行性
- Path length between long-range dependencies in the network
这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量。
缺点
缺点在原文中没有提到,是后来在Universal Transformers中指出的,主要是两点:
- 实践上:有些RNN轻易可以解决的问题transformer没做到,比如复制string,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding);
- 理论上:transformers非computationally universal(图灵完备), 有博客up主认为因为无法实现“while”循环。???
BERT
参考:
CSDN-一文读懂BERT
谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读
从创新的角度来看,BERT其实并没有过多的结构方面的创新点,其和GPT一样均是采用的transformer的结构,相对于GPT来说,BERT是双向结构的,而GPT是单向的,如下图所示:

详细信息参见博文 BERT原理和结构详解《BERT原理和结构详解》
Bert使用的是Transformer的encoder模块,BERT base和BERT large的区别是encoder的层数。

核心过程
- 句子之间的关系:先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。
- 句子内部的关系:其次随机去除两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。
- 训练:最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
输入表征
BERT 最核心的过程就是同时预测加了 MASK 的缺失词与 A/B 句之间的二元关系,而这些首先都需要体现在模型的输入中,在 Jacob 等研究者的原论文中,有一张图很好地展示了模型输入的结构。

如上所示,输入有 A 句「my dog is cute」和 B 句「he likes playing」这两个自然句,我们首先需要将每个单词及特殊符号都转化为词嵌入向量,因为神经网络只能进行数值计算。其中特殊符 [SEP] 是用于分割两个句子的符号,前面半句会加上分割编码 A,后半句会加上分割编码 B。
因为要建模句子之间的关系,BERT 有一个任务是预测 B 句是不是 A 句后面的一句话,而这个分类任务会借助 A/B 句最前面的特殊符 [CLS] 实现,该特殊符可以视为汇集了整个输入序列的表征。
最后的位置编码是 Transformer 架构本身决定的,因为基于完全注意力的方法并不能像 CNN 或 RNN 那样编码词与词之间的位置关系,但是正因为这种属性才能无视距离长短建模两个词之间的关系。因此为了令 Transformer 感知词与词之间的位置关系,我们需要使用位置编码给每个词加上位置信息。
Pre-Train过程
BERT 最核心的就是预训练过程,这也是该论文的亮点所在。简单而言,模型会从数据集抽取两句话,其中 B 句有 50% 的概率是 A 句的下一句,然后将这两句话转化前面所示的输入表征。现在我们随机遮掩(Mask 掉)输入序列中 15% 的词,并要求 Transformer 预测这些被遮掩的词,以及 B 句是 A 句下一句的概率这两个任务。
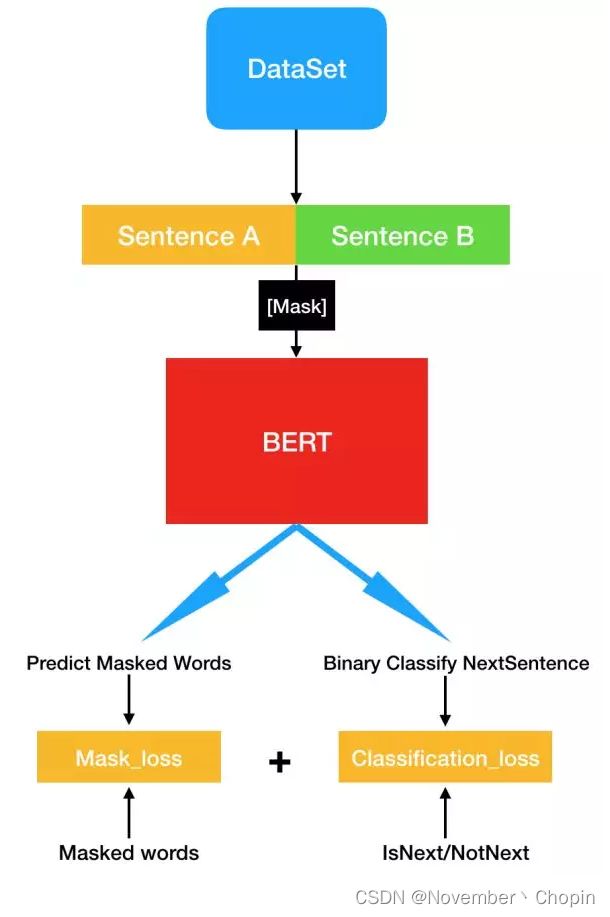
首先谷歌使用了 BooksCorpus(8 亿词量)和他们自己抽取的 Wikipedia(25 亿词量)数据集,每次迭代会抽取 256 个序列(A+B),一个序列的长度为小于等于 512 个「词」。因此 A 句加 B 句大概是 512 个词,每一个「句子」都是非常长的一段话,这和一般我们所说的句子是不一样的。这样算来,每次迭代模型都会处理 12.8 万词。
- 对于二分类任务,在抽取一个序列(A+B)中,B 有 50% 的概率是 A 的下一句。如果是的话就会生成标注「IsNext」,不是的话就会生成标注「NotNext」,这些标注可以作为二元分类任务判断模型预测的凭证。
- 对于 Mask 预测任务,首先整个序列会随机 Mask 掉 15% 的词,这里的 Mask 不只是简单地用「[MASK]」符号代替某些词,因为这会引起预训练与微调两阶段不是太匹配。所以谷歌在确定需要 Mask 掉的词后,80% 的情况下会直接替代为「[MASK]」,10% 的情况会替代为其它任意的词,最后 10% 的情况会保留原词。
- 原句:my dog is hairy
- 80%:my dog is [MASK]
- 10%:my dog is apple
- 10%:my dog is hairy
注意最后 10% 保留原句是为了将表征偏向真实观察值,而另外 10% 用其它词替代原词并不会影响模型对语言的理解能力,因为它只占所有词的 1.5%(0.1 × 0.15)。此外,作者在论文中还表示因为每次只能预测 15% 的词,因此模型收敛比较慢。
Fine tuning过程
最后预训练完模型,就要尝试把它们应用到各种 NLP 任务中,并进行简单的微调。不同的任务在微调上有一些差别,但 BERT 已经强大到能为大多数 NLP 任务提供高效的信息抽取功能。对于分类问题而言,例如预测 A/B 句是不是问答对、预测单句是不是语法正确等,它们可以直接利用特殊符 [CLS] 所输出的向量 C,即 P = softmax(C * W),新任务只需要微调权重矩阵 W 就可以了。
对于其它序列标注或生成任务,我们也可以使用 BERT 对应的输出信息作出预测,例如每一个时间步输出一个标注或词等。下图展示了 BERT 在 11 种任务中的微调方法,它们都只添加了一个额外的输出层。在下图中,Tok 表示不同的词、E 表示输入的嵌入向量、T_i 表示第 i 个词在经过 BERT 处理后输出的上下文向量。

如上图所示,句子级的分类问题只需要使用对应 [CLS] 的 C 向量,例如(a)中判断问答对是不是包含正确回答的 QNLI、判断两句话有多少相似性的 STS-B 等,它们都用于处理句子之间的关系。句子级的分类还包含(b)中判语句中断情感趋向的 SST-2 和判断语法正确性的 CoLA 任务,它们都是处理句子内部的关系。
一些疑问及解答
- Bert [CLS]位的向量是怎么生成的?
通过self attention的机制 weighted sum up其他所有token的embedding得到的。所以可以用了做sentence classification。 - ==