python并发编程(并发与并行,同步和异步,阻塞与非阻塞)
最近在学python的网络编程,学了socket通信,并利用socket实现了一个具有用户验证功能,可以上传下载文件、可以实现命令行功能,创建和删除文件夹,可以实现的断点续传等功能的FTP服务器。但在这当中,发现一些概念区分起来很难,比如并发和并行,同步和异步,阻塞和非阻塞,但是这些概念却很重要。因此在此把它总结下来。
1. 并发 & 并行
并发:在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。简言之,是指系统具有处理多个任务的能力。
并行:当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。简言之,是指系统具有同时处理多个任务的能力。
下面我们来两个例子:
import threading #线程
import time
def music():
print('begin to listen music {}'.format(time.ctime()))
time.sleep(3)
print('stop to listen music {}'.format(time.ctime()))
def game():
print('begin to play game {}'.format(time.ctime()))
time.sleep(5)
print('stop to play game {}'.format(time.ctime()))
if __name__ == '__main__':
music()
game()
print('ending.....')
music的时间为3秒,game的时间为5秒,如果按照我们正常的执行,直接执行函数,那么将按顺序顺序执行,整个过程8秒。
import threading #线程
import time
def music():
print('begin to listen music {}'.format(time.ctime()))
time.sleep(3)
print('stop to listen music {}'.format(time.ctime()))
def game():
print('begin to play game {}'.format(time.ctime()))
time.sleep(5)
print('stop to play game {}'.format(time.ctime()))
if __name__ == '__main__':
t1 = threading.Thread(target=music) #创建一个线程对象t1 子线程
t2 = threading.Thread(target=game) #创建一个线程对象t2 子线程
t1.start()
t2.start()
# t1.join() #等待子线程执行完 t1不执行完,谁也不准往下走
t2.join()
print('ending.......') #主线程
print(time.ctime())
在这个例子中,我们开了两个线程,将music和game两个函数分别通过线程执行,运行结果显示两个线程同时开始,由于听音乐时间3秒,玩游戏时间5秒,所以整个过程完成时间为5秒。我们发现,通过开启多个线程,原本8秒的时间缩短为5秒,原本顺序执行现在是不是看起来好像是并行执行的?看起来好像是这样,听音乐的同时在玩游戏,整个过程的时间随最长的任务时间变化。但真的是这样吗?那么下面我来提出一个GIL锁的概念。
GIL(全局解释器锁):无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行。
import time
from threading import Thread
def add():
sum = 0
i = 1
while i<=1000000:
sum += i
i += 1
print('sum:',sum)
def mul():
sum2 = 1
i = 1
while i<=100000:
sum2 = sum2 * i
i += 1
print('sum2:',sum2)
start = time.time()
add()
mul() #串行比多线程还快
print('cost time %s'%(time.time()-start))
import time
from threading import Thread
def add():
sum = 0
i = 1
while i<=1000000:
sum += i
i += 1
print('sum:',sum)
def mul():
sum2 = 1
i = 1
while i<=100000:
sum2 = sum2 * i
i += 1
print('sum2:',sum2)
start = time.time()
t1 = Thread(target=add)
t2 = Thread(target=mul)
l = []
l.append(t1)
l.append(t2)
for t in l:
t.start()
for t in l:
t.join()
print('cost time %s'%(time.time()-start))

哎吆,这是怎么回事,串行执行比多线程还快?不符合常理呀。是不是颠覆了你的人生观,这个就和GIL锁有关,同一时刻,系统只允许一个线程执行,那么,就是说,本质上我们之前理解的多线程的并行是不存在的,那么之前的例子为什么时间确实缩短了呢?这里有涉及到一个任务的类型。
--任务: 1.IO密集型(会有cpu空闲的时间) 注:sleep等同于IO操作, socket通信也是IO
2.计算密集型
而之前那个例子恰好是IO密集型的例子,后面这个由于涉及到了加法和乘法,属于计算密集型操作,那么,就产生了一个结论,多线程对于IO密集型任务有作用,
而计算密集型任务不推荐使用多线程。
而其中我们还可以得到一个结论:由于GIL锁,多线程不可能真正实现并行,所谓的并行也只是宏观上并行微观上并发,本质上是由于遇到io操作不断的cpu切换
所造成并行的现象。由于cpu切换速度极快,所以看起来就像是在同时执行。
--问题:没有利用多核的优势
--这就造成了多线程不能同时执行,并且增加了切换的开销,串行的效率可能更高。
2. 同步 & 异步
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready) 2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
同步:当进程执行IO(等待外部数据)的时候,-----等。同步(例如打电话的时候必须等) 异步:当进程执行IO(等待外部数据)的时候,-----不等,去执行其他任务,一直等到数据接收成功,再回来处理。异步(例如发短信) 当我们去爬取一个网页的时候,要爬取多个网站,有些人可能会发起多个请求,然后通过函数顺序调用。执行顺序也是先调用先执行。效率非常低。 下面我们看一下异步的一个例子:
import socket
import select
"""
########http请求本质,IO阻塞########
sk = socket.socket()
#1.连接
sk.connect(('www.baidu.com',80,)) #阻塞
print('连接成功了')
#2.连接成功后发送消息
sk.send(b"GET / HTTP/1.0\r\nHost: baidu.com\r\n\r\n")
#3.等待服务端响应
data = sk.recv(8096)#阻塞
print(data) #\r\n\r\n区分响应头和影响体
#关闭连接
sk.close()
"""
"""
########http请求本质,IO非阻塞########
sk = socket.socket()
sk.setblocking(False)
#1.连接
try:
sk.connect(('www.baidu.com',80,)) #非阻塞,但会报错
print('连接成功了')
except BlockingIOError as e:
print(e)
#2.连接成功后发送消息
sk.send(b"GET / HTTP/1.0\r\nHost: baidu.com\r\n\r\n")
#3.等待服务端响应
data = sk.recv(8096)#阻塞
print(data) #\r\n\r\n区分响应头和影响体
#关闭连接
sk.close()
"""
class HttpRequest:
def __init__(self,sk,host,callback):
self.socket = sk
self.host = host
self.callback = callback
def fileno(self):
return self.socket.fileno()
class HttpResponse:
def __init__(self,recv_data):
self.recv_data = recv_data
self.header_dict = {}
self.body = None
self.initialize()
def initialize(self):
headers, body = self.recv_data.split(b'\r\n\r\n', 1)
self.body = body
header_list = headers.split(b'\r\n')
for h in header_list:
h_str = str(h,encoding='utf-8')
v = h_str.split(':',1)
if len(v) == 2:
self.header_dict[v[0]] = v[1]
class AsyncRequest:
def __init__(self):
self.conn = []
self.connection = [] # 用于检测是否已经连接成功
def add_request(self,host,callback):
try:
sk = socket.socket()
sk.setblocking(0)
sk.connect((host,80))
except BlockingIOError as e:
pass
request = HttpRequest(sk,host,callback)
self.conn.append(request)
self.connection.append(request)
def run(self):
while True:
rlist,wlist,elist = select.select(self.conn,self.connection,self.conn,0.05)
for w in wlist:
print(w.host,'连接成功...')
# 只要能循环到,表示socket和服务器端已经连接成功
tpl = "GET / HTTP/1.0\r\nHost:%s\r\n\r\n" %(w.host,)
w.socket.send(bytes(tpl,encoding='utf-8'))
self.connection.remove(w)
for r in rlist:
# r,是HttpRequest
recv_data = bytes()
while True:
try:
chunck = r.socket.recv(8096)
recv_data += chunck
except Exception as e:
break
response = HttpResponse(recv_data)
r.callback(response)
r.socket.close()
self.conn.remove(r)
if len(self.conn) == 0:
break
def f1(response):
print('保存到文件',response.header_dict)
def f2(response):
print('保存到数据库', response.header_dict)
url_list = [
{'host':'www.youku.com','callback': f1},
{'host':'v.qq.com','callback': f2},
{'host':'www.cnblogs.com','callback': f2},
]
req = AsyncRequest()
for item in url_list:
req.add_request(item['host'],item['callback'])
req.run()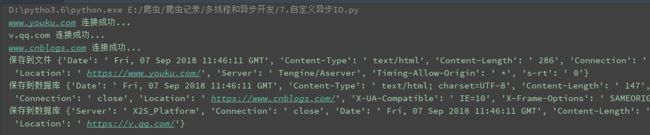
我们可以看到,三个请求发送顺序与返回顺序,并不一样,这样就体现了异步请求。即我同时将请求发送出去,哪个先回来我先处理哪个。
即我们可以理解为:我打电话的时候只允许和一个人通信,和这个人通信结束之后才允许和另一个人开始。这就是同步。
我们发短信的时候发完可以不去等待,去处理其他事情,当他回复之后我们再去处理,这样就大大解放了我们的时间。这就是异步。
体现在网页请求上面就是我请求一个网页时候等待他回复,否则不接收其它请求,这就是同步。另一种就是我发送请求之后不去等待他是否回复,而去处理其它请求,当处理完其他请求之后,某个请求说,我的回复了,然后程序转而去处理他的回复数据。这就是异步请求。所以,异步可以充分cpu的效率。
3. 阻塞 & 非阻塞
调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。 下面我们通过socket实现一个命令行功能来感受一下。
#服务端
from socket import *
import subprocess
import struct
ip_port = ('127.0.0.1', 8000)
buffer_size = 1024
backlog = 5
tcp_server = socket(AF_INET, SOCK_STREAM)
tcp_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加
tcp_server.bind(ip_port)
tcp_server.listen(backlog)
while True:
conn, addr = tcp_server.accept()
print('新的客户端链接:', addr)
while True:
try:
cmd = conn.recv(buffer_size)
print('收到客户端命令:', cmd.decode('utf-8'))
#执行命令cmd,得到命令的结果cmd_res
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
)
err = res.stderr.read()
if err:
cmd_res = err
else:
cmd_res = res.stdout.read()
if not cmd_res:
cmd_res = '执行成功'.encode('gbk')
#解决粘包
length = len(cmd_res)
data_length = struct.pack('i',length)
conn.send(data_length)
conn.send(cmd_res)
except Exception as e:
print(e)
break
conn.close()
#客户端
from socket import *
ip_port = ('127.0.0.1',8000)
buffer_size = 1024
backlog = 5
tcp_client = socket(AF_INET,SOCK_STREAM)
tcp_client.connect(ip_port)
while True:
cmd = input('>>:').strip()
if not cmd:
continue
if cmd == 'quit':
break
tcp_client.send(cmd.encode('utf-8'))
#解决粘包
length = tcp_client.recv(4)
length = struct.unpack('i',length)[0]
recv_size = 0
recv_msg = b''
while recv_size < length:
recv_msg += tcp_client.recv(buffer_size)
recv_size = len(recv_msg)
print(recv_msg.decode('gbk'))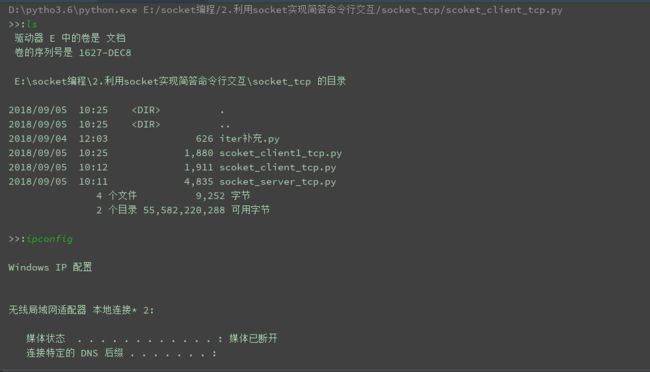
开启了服务器和一个客户端之后,我们在客户端输入一些命令,然后正确显示,功能实现。这是在我再打开一个客户端,输入命令,发现服务器迟迟没有响应。

这个就是当一个客户端在请求的时候,当这个客户端没有结束的时候,服务器不会去处理其他客户端的请求。这时候就阻塞了。
如何让服务器同时处理多个客户端请求呢?
![]()
View Code
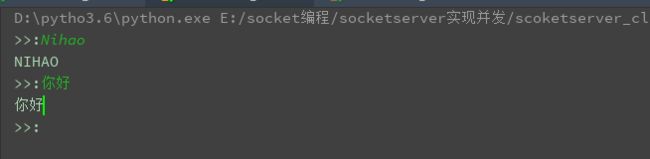

这段代码通过socketserver模块实现了socket的并发。这个过程中,当一个客户端在向服务器请求的时候,另一个客户端也可以正常请求。服务器在处理一个客户端请求的时候,另一个请求没有被阻塞。
总结:只要有一丁点阻塞,就是阻塞IO。
异步IO的特点就是全程无阻塞。
有些人常把同步阻塞和异步非阻塞联系起来,但实际上经过分析,阻塞与同步,非阻塞和异步的定义是不一样的。同步和异步的区别是遇到IO请求是否等待。阻塞和非阻塞的区别是数据没准备好的情况下是否立即返回。关于这两点的区别,看了很多博客,最后总结如下。
阻塞和非阻塞指的是执行一个操作是等操作结束再返回,还是马上返回。
比如餐馆的服务员为用户点菜,当有用户点完菜后,服务员将菜单给后台厨师,此时有两种方式:
- 第一种:就在出菜窗口等待,直到厨师炒完菜后将菜送到窗口,然后服务员再将菜送到用户手中;
- 第二种:等一会再到窗口来问厨师,某个菜好了没?如果没有先处理其他事情,等会再去问一次;
第一种就是阻塞方式,第二种则是非阻塞的。
同步和异步又是另外一个概念,它是事件本身的一个属性。还拿前面点菜为例,服务员直接跟厨师打交道,菜出来没出来,服务员直接知道,但只有当厨师将菜送到服务员手上,这个过程才算正常完成,这就是同步的事件。同样是点菜,有些餐馆有专门的传菜人员,当厨师炒好菜后,传菜员将菜送到传菜窗口,并通知服务员,这就变成异步的了。其实异步还可以分为两种:带通知的和不带通知的。前面说的那种属于带通知的。有些传菜员干活可能主动性不是很够,不会主动通知你,你就需要时不时的去关注一下状态。这种就是不带通知的异步。
对于同步和异步的事件,阻塞和非阻塞都是可以的。非阻塞又有两种方式:主动查询和被动接收消息。被动不意味着一定不好,在这里它恰恰是效率更高的,因为在主动查询里绝大部分的查询是在做无用功。对于带通知的异步事件,两者皆可。而对于不带通知的,则只能用主动查询。
但是对于非阻塞和异步的概念有点混淆,非阻塞只是意味着方法调用不阻塞,就是说作为服务员的你不用一直在窗口等,非阻塞的逻辑是"等可以读(写)了告诉你",但是完成读(写)工作的还是调用者(线程)服务员的你等菜到窗口了还是要你亲自去拿。而异步意味这你可以不用亲自去做读(写)这件事,你的工作让别人(别的线程)来做,你只需要发起调用,别人把工作做完以后,或许再通知你,它的逻辑是“我做完了 告诉/不告诉 你”,他和非阻塞的区别在于一个是"已经做完"另一个是"可以去做"。
这也是同步和异步最大的区别,就是同步在有通知时可以进行相关操作,而异步有通知时则代表操作已经完成
再举一个例子:
去书店借一本书,同步就是我要亲自到书店,问老板有没有这本书,阻塞就是老板查询的时候(读写)我只能在那等着,老板找到书后把书交给我,这就是同步阻塞。
我亲自到书店借书,老板在找这本书的时候,我可以去干别的,然后每隔一段时间去问老板书找到了没有,也可以等老板找到书以后通知我,这就是同步非阻塞。
我想借本书,找个人帮我去借,借到书以后再通知我,这就是异步,我只发起调用,但是本身并不参与这个事件,而是让别的线程去做这个事。
同步与异步是对应的,它们是线程之间的关系,两个线程之间要么是同步的,要么是异步的。
阻塞与非阻塞是对同一个线程来说的,在某个时刻,线程要么处于阻塞,要么处于非阻塞。
帮我借书的那个人有没有借到书,我可以打电话问他(轮询),也可以等他通知我,这是异步的通知;在借书的过程中借书的那个人可以轮询的方式查看书是否已经找到(缓冲区有没有数据),找到了你可以把它拿走,也可以等老板找到书后通知我,这是非阻塞的通知与轮询。
这里面其实涉及到的知识点还很多,这里只是凭我的记忆简单总结了一下,以后会补充更多。