量化神经网络的有效部署
背景
越来越多的现实应用使用深度学习模型实现预测功能,这需要大量计算和内存的使用。如此规模的资源的耗费常常会给强大的服务器带来负担,更不用说低功耗的边缘设备了。如何合理使用资源以达到高效计算成为了热点问题。不同的技术方法(从算法,软件,硬件考虑)得到发展来减少实际问题中模型的计算和内存消耗,进而方便模型的开发和部署。目前来看,这些技术中量化是一个广泛被研究且有前景的方法,量化是将深度学习模型中的普遍使用的 32 位浮点数 转化为 8 位整数 进行存储,直观上能将内存占用减少 4 倍。除了更少的计算和内存资源的占用,量化的另外一个特点是保证了模型准确率与非量化模型相比不会有大的波动。这两个优点使得 量化在实际应用中已经被大量采用,许多硬件平台(如 Intel CPUS,Nvidia GPUS,ARM CPUS)纷纷引入了低精度指令来支持 数据类型的计算。现有的工作主要集中在探索新的量化方法来更好的使量化模型保持精度。在模型推理问题中,除了保持精度,降低推理时延也是一项重要衡量指标。量化技术相关的另一项研究被提出,关于如何广泛部署和高效执行这些量化后的模型,即如何将不同深度学习框架下的预量化模型执行在异构的硬件平台上。
挑战
上面讲述了量化的优点,那么量化模型的使用是否拿来就能用呢?当时不是。对于深度学习框架,量化模型的应用受限于 kernel 库的依赖,其他算子的相互作用以及不同硬件平台的适配;对于深度学习编译器,绝大部分是基于 类型的,尽管一些编译器支持量化运算符的生成和优化,但没有一个专注于编译和执行预量化模型。那么如何构建这样一种机制来使得开发者可以容易且快速地使用量化后的模型呢?主要存在如下挑战:
多框架结构:当下主流的深度学习框架有 TensorFlow, TFLite, MXNet, 和PyTorch,所以需要提出的方法可以处理不同框架下的神经网络模型。
多量化方法:不同的量化方法有均匀量化(使用最多),对称量化,非对称量化,per-channel量化等等,不同的方法在不同的问题带来不同的结果。所以提出的方法需要包含所有的这些方法。
多硬件平台:提出的方法需要可以将预量化模型运行在大量的异构设备上,并且支持使用快速整数指令,例如 Intel VNNI 或 Nvidia DP4A 指令。
表 1 展示了当下不同框架受限的硬件支持和量化方法支持。
 Tab 1 深度学习框架对量化方法与设备的支持现状
Tab 1 深度学习框架对量化方法与设备的支持现状
方法
尽管流行的深度学习框架不能解决上述挑战,但 DL 编译器提供了可能性。深度学习编译器拥有框架无关的图级别的 IR(中间表示),可以将任何由任何框架编写的模型转化到这个 IR,而不同的量化方法可自然在编译器中得到使用,最后编译器依赖 LLVM 和 NVCC 等成熟的代码生成器来覆盖广泛的硬件平台,于是三个问题可迎刃而解。由于编译器原本是被设计来编译 模型的,并不支持量化算子和相关优化,而直接增加算子需要在图级别和 tensor 级别整个工具链进行更新支持,这些工作是繁琐且耗时的,这便引发一个新的问题,如何让开发者可以快速简易的的将量化之后的模型应用在不同的硬件平台上。
通过观察发现,量化算子的计算可以很容易地表示为一系列更简单的、熟悉的算子。尽管这些分解会造成初始计算图的体积增大,但现存编译器在图级别和算子级别的优化方案可直接借鉴。开发者要做的工作只需要关注不同设备上所要求的数据类型(如:intel:int8;armv8:int16),余下的优化操作都留给编译器解决。基于这些观察,一种解决方案是量化神经网络 (QNN),这是一种具有量化上下文的图形级方言(dialect),可简化预量化模型在各种硬件平台上的高效执行,如图 1 所示。
 Fig.1 基于深度学习编译器的 QNN 设计
Fig.1 基于深度学习编译器的 QNN 设计
开发者增加了新的 QNN 算子,并规定了它们降级为现有的图级(中继)运算符的方式。不同框架解析器使用 QNN 算子来将计算图转化为 QNN 图,QNN 框架内部然后运行一系列量化感知图级优化,最终生成仅中继图(无 QNN 算子),这些算子通过使用 TVM 调度来降级为适配不同硬件平台的机器码。因此,在 QNN 的增强下,DL 编译器可以执行跨多个硬件平台的量化模型。
设计
QNN 方言的构建基于TVM编译器。TVM 包含两种级别的 IR——图级别 Relay IR 和 tensor 级别 Tensor IR。QNN方言主要基于 Relay IR,复用了 TVM 中大部分已存在的基础结构。
整体设计如图 1 所示,开发者首先需要增加新的 QNN 算子(量化后的算子)并明确如何将该算子转化为一系列存在的 Relay 算子。框架解析器将预量化模型转化有 QNN 算子和 Relay 算子的混合组成的与框架无关的图 IR。接下来是 QNN 图级别的优化过程,包含 QNN Canonicalize 和 QNN Legalize。由于 QNN 方言是量化感知的 IR,不能直接用于下面的 Relay passes。QNN Legalize 的作用是进行专用设备的数据格式转化,QNN Canonicalize 的作用是将 QNN 算子转化为一系列 Relay 算子。接下来便可沿用TVM的的基础编译架构,先进行 Relay IR 的优化,再进行 tensor IR 的优化,最后使用现有的编译器 LLVM\NVCC 编译生成机器码。
QNN 被提出的目的是通过复用现存 DL 编译器的基础结构和只关注一些 数据类型的项目来减少开发者的精力投入。使用 QNN 来扩展DL编译器的新工作在图一中被标记为黑色盒子——包含 QNN 算子,框架解析器,QNN 优化 pass 和整数算子调度。
QNN算子和框架解析器
QNN 算子像是一个包装器,它由现存的多个 Relay 算子组成。开发者需要定义两者间的转化方法,由 QNN Canonicalize pass 负责转换为全部是 Relay 算子的表示。在从流行的不同框架中收集量化算子的过程中,发现相同的算子名字可能会对应不同的计算过程,例如:TFLite 量化 conv2d 算子依次进行了 卷积运算,输出张量的重新量化,ReLU 和加偏置的运算,而在 MXNet 中该算子增加了进一步融合,融合剩余加法运算和折叠批量正常化。QNN 为了解决该问题,设计了新的算子来表达这些主流框架下的不同计算和量化算子,方法是将原算子转化为一个或多个 QNN/RELAY 算子。下面是一个关于 TFLite 量化 conv2d 算子转化的实例:
 Fig.2 TFLite 量化 conv2d 算子解析示例
Fig.2 TFLite 量化 conv2d 算子解析示例
TFLite conv2d 内部融合了很多算子,被重新解析为一系列 QNN 和现存的 Relay 算子 QNN conv2d, Relay bias add, Relay clip 和 QNN requantize operator。QNN conv2d 只接受量化算子,Relay clip 用来对向量值根据预定义输出的最大最小值进行裁剪,QNN requantize operator 则使算子重新返回到 数据类型。
QNN Canonicalization Pass (CP)
QNN CP 的作用是使用由开发者定义的规则将 QNN ops 转换为一系列 Realy 算子。QNN 提供了基础结构,开发人员可以在其中指定将 QNN 算子降级为一系列 Relay 算子,不同算子的转化的难度是不同的。为更直观的理解算子转化的复杂度,并对设计过程有更直观理解,拿 QNN Pooling 和 QNN Conv2d 举例。
QNN Pooling
QNN pooling 算子规范化只需要简单的转化。对于所有深度学习框架量化 pooling 算子对于输入和输出张量有相同的尺寸和零点汇集。该转化过程可表示为:是零点(zero point), 和 均代表量化算子。我们可以跳过缩放和零点处理(因为它们是相等的)而只执行平均池化操作。在池化操作中,我们必须小心除法期间的舍入并将输入向上转换为 以避免累积时上溢/下溢。
QNN Conv2d
设 和 是输入 tensor, 是输出 tensor, 代表卷积操作,conv2d 量化算子的计算如下:可分解为 4 项,每一项可对应一个 Relay 算子。假设 和 分别代表输出通道,输入通道,滤波器高度,滤波器宽度, 分别代表 batch 大小,输出高度,输出宽度,则 表示为:
QNN conv2d 算子分解后的 4 个 term:Term 1 是处理量化后 输入 tensor 的 Relay conv2d;Term 2 包含了对 维度上的权重张量执行归约求和运算,可以被表示为 pool2d,reduce sum 和 multiplication 算子,Term 3 对输入数据量化张量执行滑动窗口缩减;Term 4 是常量之间的相乘。QNN 到 Relay 的规范化转化示意图如图 3。
 Fig.3 QNN Conv2D 规范化
Fig.3 QNN Conv2D 规范化
图中显示, Reshape 和 cast 算子被添加进来以确保在组合不同项时张量形状和数据类型匹配。编译时常量项(第 2 项和第 4 项)首先被提取执行来进行常量折叠。
QNN Legalize Pass
与 Relay passes 不同的是,QNN 有量化上下文,这有助于进行专用硬件的图-IR 转换来适配指令集差异导致的数据类型限制,QNN legalize pass 允许开发者轻松执行这些量化感知平台特定的图形优化。它的主干建立在现有的 Relay 基础框架上,允许为硬件平台定制图形优化。
举例来说:TFLite 中 QNN conv2d 预量化图输入是 ,但是基于 Intel VNN1指令集平台需要 的数据类型,QNN Legalize pass 通过允许在 conv2d 的第二个操作数之前插入重新量化运算符,将数据类型从 转换为 ,以一种对开发人员友好的方式弥合了这一差距。
整数算子的TVM调度
在经历图级优化后,下面要进行的是 tensor 级别的优化。对于很多简单的算子,如“加”和“ReLU”算子,不涉及数据重用,也就不需要进行额外优化了。但是像 conv2d 或者矩阵乘需要特别的 tensor 级别的进一步优化来有效进行数据重用,又由于不同设备存在结构的巨大差异,同样的优化工作需要在每一种平台上进行。QNN 基础结构迅速将开发人员的注意力转移到那些由于整数计算而需要额外关注的运算符上。这与框架形成对比,框架需要单独实现新的量化算子。QNN 对于受整数计算影响较大的算子,编写了特定的调度程序,利用硬件提供的快速整数指令来获得理想的性能。该方法在服务器和边缘设备上针对不同类型的问题都有了实践的的验证,证明了其可行性和有效性。
评价
QNN 从以下四个方面进行了实验:
QNN 是否可以编译预量化的模型来取得与框架解决方案相近的模型准确率;
使用 QNN 优化后的模型与 原模型相比效果如何;
与框架解决方案相比,QNN 能否在预量化模型上获得同等甚至更好的性能,同时覆盖比框架更多的硬件平台;
QNN 在编译新设计的预量化模型时表现如何。
实验设置上,测试的框架包括了 TFLite,MXNet,PyTorch,QNN 的设计及运行整体以 TVM 框架为基础。测试平台包括:服务器层级的 Intel 24-core Xeon Cascade Lake CPU 和 Nvidia T4 GPU,边缘设备包括 Raspberry Pi3 和 Raspberry Pi4。
针对问题一,图 4 基于 ImageNet 验证集中的 10k 张图片,展现了预量化模型在不同 DL 框架与 QNN 扩展后的 TVM stack 方案的准确率。可以看出对比所有主流框架,QNN 可以实现相当的准确率,这些细小的差异归咎于不同方法中浮点数的舍入方法的差别。
 Fig.4 QNN 在所有主流框架(MXNet、TFLite 和 PyTorch)中预量化模型实现的准确率
Fig.4 QNN 在所有主流框架(MXNet、TFLite 和 PyTorch)中预量化模型实现的准确率
针对问题二,对比了编译 MXNet 实现下的原模型与 QNN 模型,图 5 和图 6 分别展示了在服务器和边缘设备上的加效果。整体上对比 TVM-fp32,QNN-int8 在 Intel Cascade Lake CPU 和 Nvidia T4 GPU 上分别取得了 2.35 和 2.13 倍的加速效果,在 ARM Raspberry Pi3 和 Pi4 上分别取得了 1.35 和 1.40 倍的加速效果。
 Fig.5 QNN 在服务器端使用快速int8指令相比 TVM fp32 基线获得的加速效果
Fig.5 QNN 在服务器端使用快速int8指令相比 TVM fp32 基线获得的加速效果  Fig.6 QNN 在边缘设备上相比 TVM fp32 基线获得的加速效果. 红叉代表内存不够,实验未成功
Fig.6 QNN 在边缘设备上相比 TVM fp32 基线获得的加速效果. 红叉代表内存不够,实验未成功
除了模型推理时间得到了降低, 表示带来的另一大好处是模型占用的下降。图 7 展示比较了所有硬件平台上所有托管 MXNet 模型的 TVM-fp32 和 QNN-int8 模型的总运行时内存占用,QNN-int8 中的内存占用作为 TVM-fp32 的一部分,每个模型的内存占用被分为 weights 和中间特征映射(即参数和中间输出)。可以观察到,不同的模型根据中间表示占用的内存大小有着不同的内存减少。在边缘设备中,QNN-int8 只有近 50% 的内存占用减少,这是因为 weighs 被上调至 int16 来适配 ARM 的快 int16 累乘指令。
 Fig.7 模型权重和中间特征图的运行时内存占用的比例
Fig.7 模型权重和中间特征图的运行时内存占用的比例
针对问题三:由于不同的框架对于不同的硬件平台支持是有差异的,所以针对不同的框架在支持的平台上进行了测试,并对比相同模型下以 QNN 编译和执行的效果。TFLite 和 PyTorch 都不支持预量化模型执行在 GPU 上,MXNet 虽然支持,但效果很差,于是没有对比 GPU 平台。就 MXNet 举例,图展示了端到端的性能对比。整体来说,可以观察到对比在 Intel Cascade Lake CPU 上运行的MXNet模型,QNN-int8 取得了 1.09 倍的加速。在 resnet-50, 和 resnet-50 v1b 上效果略差,这可能是因为英特尔 DNNL 为 resnet 模型定制了优化,因为它们很受欢迎。
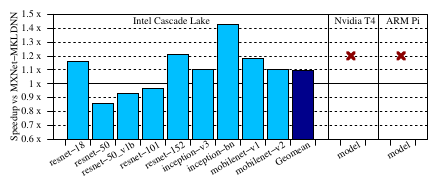 Fig.8 MXNet vs QNN. 红叉标志MXNet不支持执行预量化模型
Fig.8 MXNet vs QNN. 红叉标志MXNet不支持执行预量化模型
针对问题四,选取的新模型是一个内部构建的关键字检测模型,它在资源受限的边缘设备上执行,以检测人类语音中的特定关键字或触发器。该模型必须同时具有低延迟和资源利用率,使得可以同时在同一设备上共同执行其他应用程序。实验主要对比了 模型在 TVM 上编译执行与预量化模型在 QNN-int8 上编译执行,后者在单线程和 4 线程中分别取得了 2 倍和 2.7 倍的加速效果,获得了 50% 整个运行时的内存占用较少,在准确率上无损失。该样例展示了 QNN 扩充后的深度学习编译器在新设备上快速轻便部署新模型是有效的。
总结
本次分享主要介绍了一种量化模型编译执行的通用解决方案,可应对跨各种硬件平台的各种框架有效执行预量化模型的挑战,同时保持开发人员的低工作量。由于大多数深度学习框架只提供量化模型方法但不支持将这些模型执行在不用平台上。被称作量化神经网络 (QNN) 的新图形级方言增强的深度学习编译器可以帮助解决这个问题。QNN 的实现基于 TVM 框架,除了 QNN 自身所新增的功能,也复用了 TVM 原生库中的大部分基础结构,最终简化了将预量化模型有效执行在不同硬件设备上的工作流程。
欢迎关注Adlik的Github仓库:
