【网络原理4】TCP特性篇
目录
一、滑动窗口
传统发送接收机制的缺点
滑动窗口的特性
发送方什么时候会接着发送下一个窗口的报文
如果在滑动窗口的机制下面发生了丢包会怎样处理
情况1:ack丢了
情况2:主动发送的syn丢包了
滑动窗口的应用场景
二、TCP流量控制:根据接收方的处理能力,协调发送方的发送速率。
TCP滑动窗口过大的缺点
如何衡量接收方的处理能力
有一种量化的方法:
更简单的方法:(直接查看接收方的接收缓冲区的剩余大小):
探测报文
窗口大小为16位,也就是最大位64kb,那么是否意味着窗口大小最大是64kb呢?
三、拥塞控制
为什么有了流量控制,还需要拥塞控制
拥塞窗口(cwnd)
第一阶段,慢增长:
第二阶段:避免拥塞算法
第三阶段:发生了网络拥塞
拥塞窗口的好处:
如何确定TCP滑动窗口的值
四、延时应答机制(也叫延迟确认)
为什么要有演示应答机制?
延时应答机制的策略
对于接收方:
对于接收方
实际场景当中的延时应答机制
五、捎带应答
六、粘包问题
什么是粘包问题
解决粘包问题:两个约定
一、关于协定的约定:
二、约定每个包的长度
三、明确分隔符
七、其余的不可抗力
情况1:进程崩溃了/主机关机
情况2:主机掉电了/网线断开了。
如果是接收方掉电了:
如果是发送方掉电了:
其他的传输层协议
一、滑动窗口
传统发送接收机制的缺点
我们知道:TCP是一个拥有可靠性的协议;它的可靠性是依靠确认应答机制和超时重传机制来保证的。
在这一篇文章当中,也提到了TCP的可靠性是如何实现的。
【网络原理篇2】TCP报头详解_革凡成圣211的博客-CSDN博客TCP报头结构https://blog.csdn.net/weixin_56738054/article/details/128935529?spm=1001.2014.3001.5502
但是关于超时重传,在上述文章的图解当中:是客户端一次会话发送完成之后,下一次客户端再次向服务端发起会话的时候,需要等待直到服务端的ack进行反馈了的时候,才会再次发送文。
为了减少这种不必要的等待,于是引入了TCP滑动窗口机制。
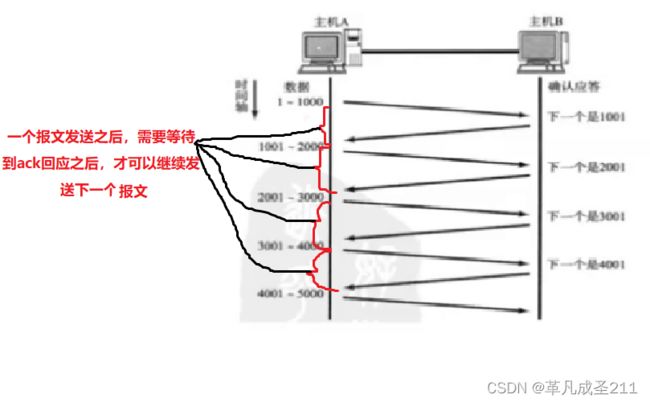
滑动窗口的特性
滑动窗口的特点就是:批量地发送一组数据,只需要使用一份时间来等待多个ack即可。
发送端主机,在发送了一个段以后没必要一直等待确认应答,而是继续发送。
因此,把可以连续发送(不需要等待,就能直接发送)的数据的最大的量,就称为"窗口大小"。
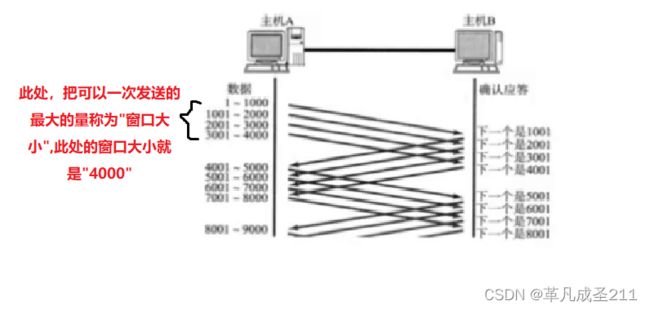
发送方什么时候会接着发送下一个窗口的报文
发送方不是一次等待所有的数据(1-4000)都全部到达了,才会再次发送ack报文。而是等待到一个ack回应过来之后,才会接着发送下一个TCP报文。
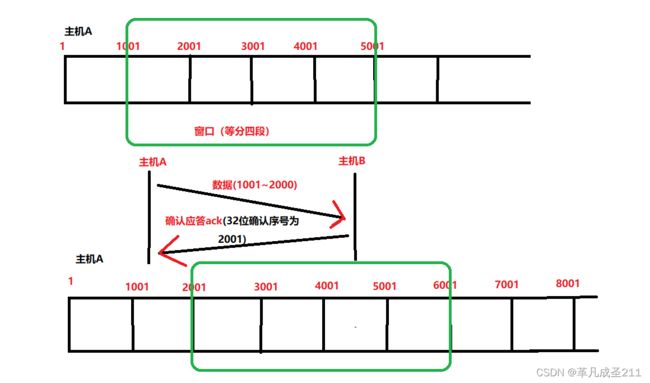
发送方本来需要等待的ack报文的范围是(1001,5001),但是由于已经收到了确认序号为2001的ack报文了,说明编号<2001的报文都收到了。
那么,再次发送新的报文的时候,滑动窗口的范围就变了,变成了原来的范围+1000,也就(2001,6001)。
如果在滑动窗口的机制下面发生了丢包会怎样处理
关于丢包的问题,需要分为两种情况来讨论:
情况1:ack丢了
如果ack丢了,不需要做任何的处理,也不会影响发送方和接收方之间的正常传输。
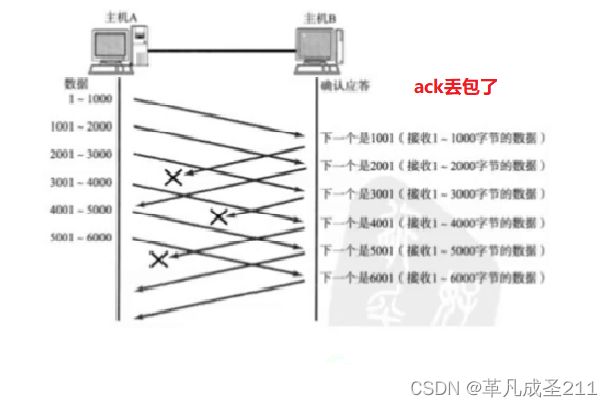
为什么不需要做任何的处理呢?再次图解一下:
| 时间轴 | 发送方 | 接收方 | 报文类型 | 说明 |
| t1 | 发送1-1000的数据 | syn | ||
| t2 | 发送应答报文给发送方(32位确认序号为1001) | ack | 此时发生了丢包。 | |
| t3 | 发送数据1001-2000的数据 | syn | ||
| t4 | 发送应答报文给接收方(32位确认序号为2001) | ack | 没有发生丢包 | |
| t5 | 收到了确认序号为2001的编号 | ack |
可以看到,t5的时候,发送方收到了确认序号为2001的应答报文(ack),那么也就默认了确认序号<2001的报文都已经收到了,无需再次发送syn。
那么,如果数据丢失得比较多,只返回了最后一次的ack,这样岂不是影响比较大?
这里,我们需要注意的是,丢包毕竟是小概率事件。 只返回窗口发送的最后一次的ack, 更加是不太可能的情况,因此这种情况无需担心。
并且,少发送一两次的ack,可以一定程度地减少封装分用的次数,提高效率。
情况2:主动发送的syn丢包了
如果主动发送的syn丢包了,那么发送方就会不断反复发送数据。
下面,模拟一下主动发送的syn丢包的情况:
| 时间轴 | 发送方 | 接收方 | 报文类型 | 说明 |
| t1 | 发送1-1000的数据 | syn | 此时发生了丢包 | |
| t2 | 发送数据1001-2000的数据 | syn | 此时没有发生丢包 | |
| t3 | 发送应答报文给接收方(32位确认序号为1001)................t1时刻对应的ack | ack | ||
| t4 | 收到了确认序号为1001的报文 | ack | ||
| t5 | 发送数据为2001-3000的数据 | syn | 此时没有发生丢包 | |
| t6 | 发送应答报文给接收方(32位确认序号为1001)................t1时刻对应的ack | |||
| t7 | 接收到了确认序号为1001的报文 |
可以看到,站在发送方的角度,发送方如果发送的syn报文如果出现了丢包,那么接收方会不断重复发送方发送第一次发送的报文的ack。
由于发送方多次收到相同的数据,那么就需要由发送方进行重传了。
于是,发送方继续重传数据(t8时刻开始)。
由于接收方在上面的t3、t6时刻收到了发送方发送的报文,编号分别为(1001-2000),(2001-3000)。那么,下一次接收方再次确认数据的时候,就会从3001开始确认了。
| 时间轴 | 发送方 | 接收方 | 报文类型 | 说明 |
| t8 | 发送(1-1001的数据) | syn | ||
| t9 | 接收到了数据,并返回报文(确认序号为1001) | ack |
总结一下:
对于数据报(syn)丢失的情况,接收方会只重传丢失数据对应的ack报文。
直到发送方再次发送之前丢失的数据报。
确认序号,也可以理解为接收方向发送方索要的数据
关于TCP的重传机制,已经在这一篇文章当中提到了。
【网络原理篇2】TCP报头详解_革凡成圣211的博客-CSDN博客 https://blog.csdn.net/weixin_56738054/article/details/128935529?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128935529%22%2C%22source%22%3A%22weixin_56738054%22%7D
https://blog.csdn.net/weixin_56738054/article/details/128935529?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22128935529%22%2C%22source%22%3A%22weixin_56738054%22%7D
滑动窗口的应用场景
如果需要传输的数据比较密集,那么就使用滑动窗口来处理。
如果需要传输的数据不那么密集,那么就无需采用滑动窗口处理。
二、TCP流量控制:根据接收方的处理能力,协调发送方的发送速率。
TCP流量控制是一种干预发送窗口大小的机制。滑动窗口越大,也就意味着一次可以传输的数据越多,也就意味着效率越高;
但是,窗口如果过大,也会影响发送和接收的效率。
TCP滑动窗口过大的缺点
缺点1:完全不需要等待ack的回应;如果ack丢失过多,可靠性无法保证。
缺点2:接收方来不及接收syn,发了≈白发。
缺点3:窗口过大,也是需要一定的开销的。
因此,在考虑设置滑动窗口的大小的时候:
接收方的处理能力,就是一个很重要的约束依据。
发送方的速度,不能超出接收方的处理能力范围。
这就引入了流量控制机制:根据接收方的处理能力,协调发送方的发送速率。
如何衡量接收方的处理能力
有一种量化的方法:
计算接收方每秒钟能处理多少字节
但是这种方式实际上用起来有一些麻烦,因此不太推荐使用。
更简单的方法:(直接查看接收方的接收缓冲区的剩余大小):
每一次发送方(主机A)给接收方(主机B)发送数据的时候,主机B在发送回应报文(ack)的时候,就需要把缓冲区剩余的空间,通过这个ack报文返回给A。
也就是说,接收方发送ack报文,其中的TCP报头当中的16位窗口大小就是接收方TCP缓冲区的剩余容量大小。
在这一篇文章当中,提到了TCP报头结构:
【网络原理篇2】TCP报头详解_革凡成圣211的博客-CSDN博客TCP报头结构https://blog.csdn.net/weixin_56738054/article/details/128935529?spm=1001.2014.3001.5501
里面有一个属性:16位的窗口大小.
这一个属性描述的就是窗口的大小;这一个属性仅仅只在报文类型是ack的时候才会生效。
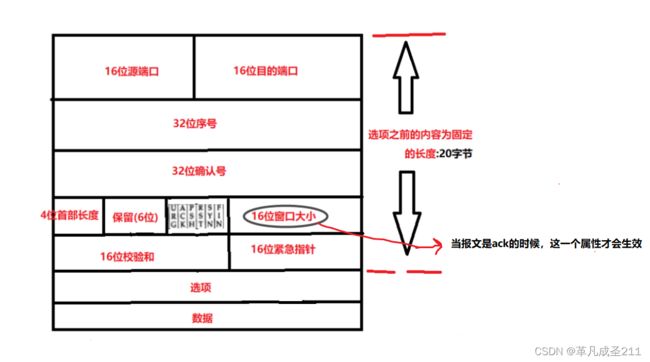
把缓冲区剩余大小通过ack应答报文发送给发送方。让发送方明确下一次发送时候的窗口大小。
如下图:

探测报文
当ack应答报文发送的窗口大小为0的时候,就意味着此时接收方的缓冲区已经无法再次处理更多数据了,因此发送方就会暂停发送。
在等待的过程当中,发送方会发送一个不携带任何数据的探测报文,探测接收方的缓冲区大小。如果接收方的缓冲区大小不为0了,才会继续发送报文。
窗口大小为16位,也就是最大位64kb,那么是否意味着窗口大小最大是64kb呢?
不是的。在选项部分,TCP为了让窗口更大,引入了窗口扩展因子。
如果窗口大小为64kb,扩展因子里面写个2,意思就是让64kb<<2,得到的就是64*4=256kb。
三、拥塞控制
为什么有了流量控制,还需要拥塞控制
在二当中,前面考虑A的发送速率,只是参考B的处理能力(缓冲区剩余空间大小),也就是由B的处理报文的情况来决定A发送的窗口的大小。
但是,A与B之间还有其他的网络节点。具体来说,就是A与B之间的传送需要经过一段链路。于是就需要通过拥塞控制+流量控制,再次确定发送方的窗口大小。
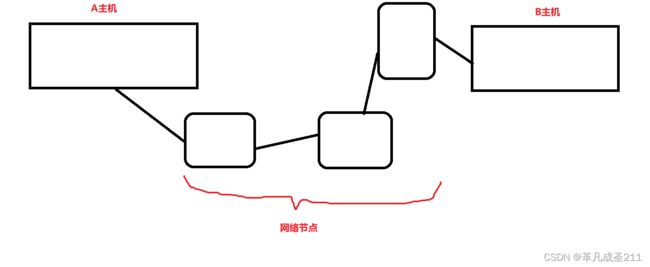
拥塞窗口(cwnd)
拥塞窗口,是发送方维护的一个状态的变量。
拥塞控制,本质上就是通过实验的方式,来逐渐找到一个合适的窗口大小(合适的发送速率)。
大致是这样的一个过程:
进行N轮的传输与发送,统计每一轮的拥塞窗口大小
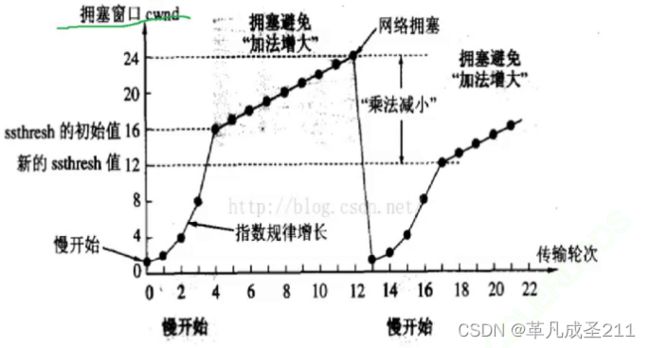
第一阶段,慢增长:
由于窗口大小比较小,每一轮不丢包(发送方收到一个ack)都会让窗口大小扩大一倍,也就是指数增长,这个过程也被称为"慢启动"。
下图来源于《小林coding》

第二阶段:避免拥塞算法
当滑动窗口到达慢启动门限(可以理解为一个阈值)之后,轮次与拥塞窗口大小就变成了线性增长的关系了。
每收到一个ack,cwnd就增加1/cwnd。
第三阶段:发生了网络拥塞
在第三阶段,一旦发生了丢包,说明此时窗口的大小已经比较大了,那么说明此时发生了网络拥塞。那么就需要把窗口大小一下缩小成很小的值,防止丢包的发生。然后重复第一、第二、第三阶段。
拥塞窗口的好处:
拥塞窗口不是固定的值,而是一直动态变化的。
随着时间的推移,逐渐到达一个动态平衡的过程。既可以找到一个合适的窗口大小,又可以让窗口的大小随着网络环境的变化而变化。
如何确定TCP滑动窗口的值
流量控制和拥塞控制共同决定发送方的窗口大小是多少。
取的是拥塞窗口和流量窗口的较小值。
四、延时应答机制(也叫延迟确认)
这个机制是在滑动窗口的基础上面新增的一个机制。
也就是发送方把syn报文发送给接收方的时候,接收方并不是立即返回ack,而是稍等一会儿再发送ack报文。
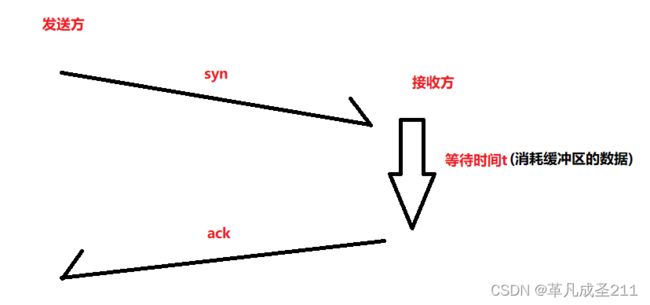
为什么要有演示应答机制?
单独发送一次没有携带数据的ack,在TCP看来,其实是有点不值得的。
因为:
原因1:一次发送需要封装、分用一次;
原因2:一个ACK,对应的TCP报头比较大,单独发送浪费开销;
原因3:便于接收方服务器消耗一下缓冲区的数据。
延时应答机制的策略
对于接收方:
如果有数据需要响应给发送方,那么ack就会携带业务数据发送到发送方。
如果没有数据需要响应给发送方,那么ack等到了对应的时间t,就直接发送ack。
下图来源于《小林coding》
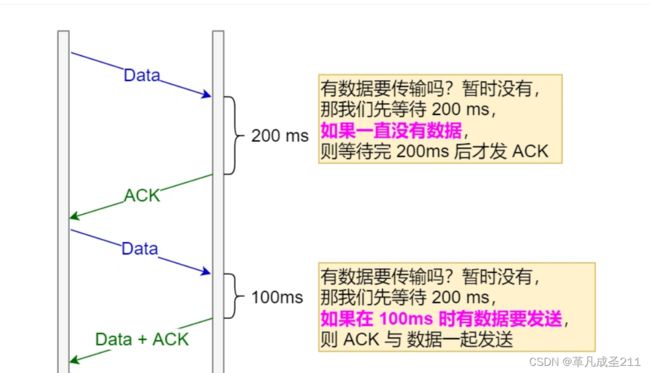 因此,这也就导致了四次挥手变为3次。关于什么是四次挥手,已经在这一篇文章当中提到了。
因此,这也就导致了四次挥手变为3次。关于什么是四次挥手,已经在这一篇文章当中提到了。
nullTCP三次握手、四次挥手https://blog.csdn.net/weixin_56738054/article/details/128961091?spm=1001.2014.3001.5501
对于接收方
如果在等待的时间t内,如果发送方连续两次发送syn报文给接收方,那么接收方会在第二次收到ack之后立即返回ack。
下图来源于《小林coding》

实际场景当中的延时应答机制
在实际的滑动窗口当中,并不再是每发送一次syn,就返回一次ack了。而是有可能隔一条syn发送一条ack。

五、捎带应答
捎带应答机制,其实就是一种合并内核报文和普通业务报文的机制;
在这一篇文章当中,我们也提到了四次TCP断开连接的四次挥手的过程:
【网络原理3】TCP连接管理_革凡成圣211的博客-CSDN博客TCP三次握手、四次挥手https://blog.csdn.net/weixin_56738054/article/details/128961091?spm=1001.2014.3001.5501
重新回顾一下,什么情况下四次挥手可以变成三次:那就是第二次挥手(发送ack)和第三次挥手(发送FIN)之间的间隔比较小的时候,就会合并第二次挥手和第三次挥手。
图解一下: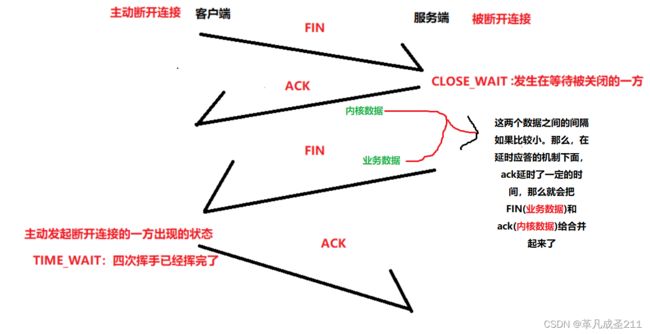
让业务数据捎带上内核数据,合并起来一起发送。这个捎带的过程,就是捎带应答机制。
六、粘包问题
什么是粘包问题
我们都知道TCP是面向字节流的协议。一次读取一个字节,一次读取N个字节都是可以的。
这就导致一次读取的数据,有可能是半个应用层的数据报,有可能是3/4个,也有可能是一个完整的应用层数据报,或者一次读取,读到了多个应用层数据报......
但是,在TCP的socket api当中没有告诉我们应该读取多少个字节。那么就会导致,一次读取的结果是不可预料的。
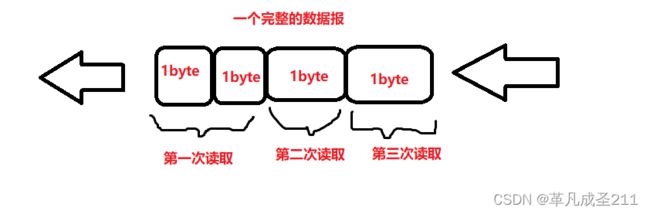
举个例子,假如有下面一段文字:
儿的生活好痛苦一点儿也没有粮食多病少挣了很多钱。
这句话,如果以TCP的形式进行传输,就有可能产生一些歧义。
一次发送的报文大小直接决定了读取的含义。
解决粘包问题:两个约定
一、关于协定的约定:
例如约定好传输层的协议是TCP还是UDP这样的轨迹。
二、约定每个包的长度
例如明确一次读取的字节大小是多少,例如read的时候尽量把字节数组填满。
也就是限制字节数组的大小。
byte[] buffer=new byte[4];
read(buffer)一次read的时候,会把这一个字节数组填满
三、明确分隔符
以什么分隔符作为结束的标志等等,像之前的手写tcp,就是以\n作为分隔符的。
下面来一段伪代码:

七、其余的不可抗力
以下四种情况,可以分为两种情况讨论:
情况1:进程崩溃了/主机关机
情况1可以理解为进程没了,也就是对应的PCB没了,对应的文件描述符表也就释放了。
相当于调用了socket.close(),此时内核会继续完成4次挥手。
情况1会触发正常的四次挥手。
情况2:主机掉电了/网线断开了。
这两个情况,是来不及挥手的了。
如果是接收方掉电了:
| 步骤 | 发送方 |
| 1 | 发送报文syn |
| 2 | 迟迟没有等待ack |
| 3 | 触发超时重传机制(再次发送syn) |
| 4 | 重传无果,仍然收不到ack |
| 5 | 重置tcp连接(此处采用的重传是发送复位报文段RST) |
| 6 | 仍然无果,那么放弃连接。 |
如果是发送方掉电了:
接收方需要周期性的给发送方发送一个消息,确认一下对方是否工作正常。
此处发送一个消息,被形象地称为"心跳包",也就是验证一下接收方是否仍然在工作。
这个"心跳包"类比的就是心跳:周期性地发送
如果心跳"无了",那么说明发送方已经"无了"
以上接收方为了验证发送方是否正常的机制,被称为"保活机制"。
其他的传输层协议
传输层的协议并不是只有一两个的。
回顾一下TCP的特点:可靠性、有连接、面向字节流、全双工。
回顾一下UDP的特点:不可靠、无连接、面向数据报、全双工。
大部分的传输场景,都是需要有连接并且可靠的,虽然效率上可能有一定的损失。
但是,也有少部分的场景:例如一家公司的机房内部,可能这些同一个机房之间的电脑之间的传输,需要效率比较高,那就要使用UDP协议了。
可仍然有一些场景,既需要可靠性,又需要效率的,例如多人联机打游戏的场景。而TCP和UDP是两个极端,一个TCP追求极端可靠,UDP追求极端的效率,因此都不太适用。
因此,引入了一种叫做KCP的协议:在可靠性方面,比TCP的可靠性差一点。在效率方面,
又比UDP的效率低一些。