基于Pytorch,从头开始实现Transformer(编码器部分)
Transformer理论部分参考知乎上的这篇文章
Transformer的Attention和Masked Attention部分参考知乎上的这篇文章
Transformer代码实现参考这篇文章,不过这篇文章多头注意力实现部分是错误的,需要注意。
完整代码放到github上了,链接
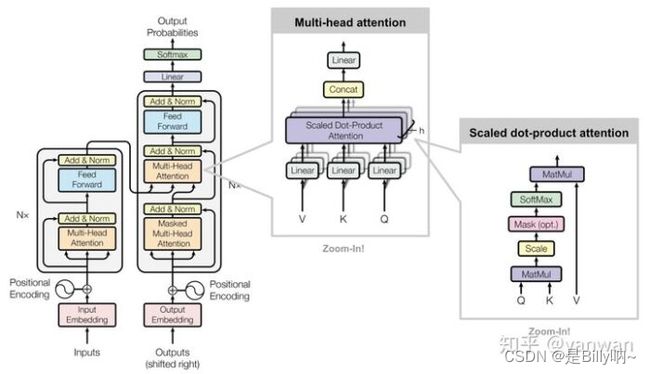
Transformer结构如下图所示:
(1)Self-Attention
在 Transformer 的 Encoder 中,数据首先会经过一个叫做 self-attention 的模块,得到一个加权后的特征向量 Z,这个 Z 就是论文公式1中的Attention(Q,K,V):
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T ( d k ) ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt(d_k)})V Attention(Q,K,V)=softmax((dk)QKT)V
在公式中,之所以要除以根号d_k(词向量或隐含层维度),原因有:1)防止输入softmax的数值过大,进而导致偏导数趋近于0;2)使得q*k的结果满足期望为0,方差为1,类似于归一化。可以参考这篇文章。
代码实现如下:
import torch
from torch import Tensor
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, input_vector_dim:int, dim_k=None, dim_v=None) -> None:
"""
初始化SelfAttention,包含以下参数:
input_vector_dim: 输入向量的维度,对应公式中的d_k。加入我们将单词编码为了10维的向量,则该值为10
dim_k:矩阵W^k和W^q的维度
dim_v:输出向量的维度。例如经过Attention后的输出向量,如果你想让它的维度是15,则该值为15;若不填,则取input_vector_dim,即与输入维度一致。
"""
super().__init__()
self.input_vector_dim = input_vector_dim
# 如果dim_k和dim_v是None,则取输入向量维度
if dim_k is None:
dim_k = input_vector_dim
if dim_v is None:
dim_v = input_vector_dim
"""
实际编写代码时,常用线性层来表示需要训练的矩阵,方便反向传播和参数更新
"""
self.W_q = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_k = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_v = nn.Linear(input_vector_dim, dim_v, bias=False)
# 这个是根号下d_k
self._norm_fact = 1 / np.sqrt(dim_k)
def forward(self, x):
"""
进行前向传播
x: 输入向量,size为(batch_size, input_num, input_vector_dim)
"""
# 通过W_q, W_k, W_v计算出Q,K,V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
"""
permute用于变换矩阵的size中对应元素的位置
即:将K的size由(batch_size, input_num, output_vector_dim) 变为 (batch_size, output_vector_dim, input_num)
----
0,1,2 代表各个元素的下标,即变换前 batch_size所在的位置是0,input_num所在的位置是1
"""
K_T = K.permute(0, 2, 1)
"""
bmm 是batch matrix-matrix product,即对一批矩阵进行矩阵相乘。相比于matmul,bmm不具备广播机制
"""
atten = nn.Softmax(dim=-1)(torch.bmm(Q, K_T) * self._norm_fact)
"""
最后再乘以 V
"""
output = torch.bmm(atten, V)
return output
上面的代码要注意
Tensor.bmm()方法的应用。一般而言,我们输入的Q、K和V的数据形式为(Batchsize, Sequence_length, Feature_embedding),在进行矩阵乘法时,只对后两维执行。
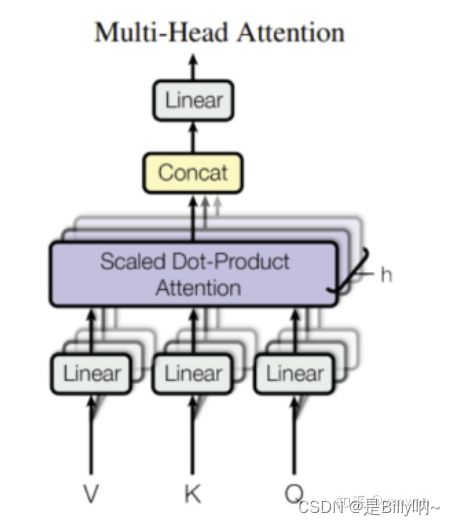
(2)Multi-Head Attention
Multi-Head Attention 的示意图如下所示:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) Q O MultiHead(Q, K, V) = Concat(head_1, ..., head_h)Q^O MultiHead(Q,K,V)=Concat(head1,...,headh)QO
def attention(query:Tensor, key:Tensor, value:Tensor):
"""
计算Attention的结果。
这里其实传入对的是Q,K,V;而Q,K,V的计算是放在模型中的,请参考后续的MultiHeadAttention类。
这里的Q,K,V有两种shape,如果是Self-Attention,shape为(batch, 词数, d_model),
例如(1, 7, 128),表示batch_size为1,一句7个单词,每个单词128维
但如果是Multi-Head Attention,则Shape为(batch, head数, 词数,d_model/head数),
例如(1, 8, 7, 16),表示batch_size为1,8个head,一句7个单词,128/8=16。
这样其实也能看出来,所谓的MultiHead其实也就是将128拆开了。
在Transformer中,由于使用的是MultiHead Attention,所以Q、K、V的shape只会是第二种。
"""
"""
获取 d_model 的值。之所以这样可以获取,是因为 query 和输入的 shape 相同。
若为Self-Attention,则最后一维都是词向量的维度,也就是 d_model 的值;
若为MultiHead-Attention,则最后一维是 d_model/h,h表示head数。
"""
d_k = query.size(-1)
# 执行QK^T / 根号下d_k
scores = torch.matmul(query, key.transpose(-2, -1)) / np.sqrt(d_k)
"""
执行公式中的softmax
这里的 p_attn 是一个方阵;若为Self-Attention,则shape为(batch, 词数, 词数);
若为MultiHead-Attention,则shape为(batch, head数, 词数, 词数)
"""
p_attn = scores.softmax(dim=-1)
"""
最后再乘以 V.
对于Self-Attention来说,结果 shape 为(batch, 词数, d_model),这也就是最终的结果了。
对于MultiHead-Attention来说,结果 shape 为(batch, head数, 词数, d_model/head数)
而这不是最终结果,后续还要将head合并,变为(batch, 词数, d_model)。不过这是MultiHeadAttention该做的事。
"""
return torch.matmul(p_attn, value)
class MultiHeadAttention(nn.Module):
def __init__(self, h:int, d_model:int) -> None:
"""
h: head数
d_model: d_model数
"""
super().__init__()
assert d_model % h == 0, "head number should be divided by d_model"
self.d_k = d_model // h
self.h = h
# 定义W^q、W^k、W^v和W^o矩阵。
self.linears = [
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model)
]
def forward(self, x):
# 获取batch_size
batch_size = x.size(0)
"""
1. 求出Q、K、V。这里是求MultiHead的Q、K、V,所以shape为(batch, head数, 词数, d_model/head数)
1.1 首先,通过定义的W^q, W^k, W^v 求出Self-Attention的Q、K、V。此时,Q、K、V的shape为(batch, 词数, d_model)
对应代码为 linear(x)
1.2 分为多头,即将shape由(batch, 词数, d_model)变为(batch, 词数, head数, d_model/head数)
对应代码为 .view(batch_size, -1, self.h, self.d_k)
1.3 最终交换 词数 和 head数 这两个维度,将head数放在前面,最终shape变为(batch, head数, 词数, d_model/head数)
对应代码为 .transpose(1,2)
"""
query, key, value = [linear(x).view(batch_size, -1, self.h, self.d_k).transpose(1,2) for linear, x in zip(self.linears[:-1], (x, x, x))]
"""
2. 求出Q、K、V后,通过Attention函数计算出Attention结果。
这里x的shape为(batch, head数, 词数, d_model/head数)
self.attn的shape为(batch, head数, 词数, 词数)
"""
x = attention(query, key, value)
"""
3. 将多个head再合并起来,即将x的shape由(batch, head数, 词数, d_model/head数)再变为(batch, 词数, d_model)
3.1 首先, 交换 head数 和 词数 维度,结果为 (batch, 词数, head数, d_model/head数)
对应代码为
"""
x = x.transpose(1,2).reshape(batch_size, -1, self.h * self.d_k)
"""
4. 最后,通过W^o矩阵再执行一次线性变换,得到最终结果
"""
return self.linears[-1](x)
(3) Positional Encoding
在构建完整的 Transformer 之前,我们还需要一个组件—— Positional Encoding。请注意:MultiHeadAttention 没有在序列维度上运行,一起都是在特征维度上进行的,因此它与序列长度和顺序无关。
我们必须向模型提供位置信息,以便它知道输入序列中数据点的相对位置。
Transformer 论文中使用三角函数对位置进行编码:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
如何理解位置坐标编码? 参考这篇文章
在没有 Position embedding 的 Transformer 模型并不能捕捉序列的顺序,交换单词位置后 attention map 的对应位置数值也会进行交换,并不会产生数值变化,即没有词序信息。所以这时候想要将词序信息加入到模型中。
代码实现如下(参考这篇文章):
class PositionalEncoding(nn.Module):
"""
基于三角函数的位置编码
"""
def __init__(self, num_hiddens, dropout=0, max_len=1000):
"""
num_hiddens:向量长度
max_len:序列最大长度
dropout
"""
super().__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P : (1, 1000, 32)
self.P = torch.zeros((1, max_len, num_hiddens))
# 本例中X的维度为(1000, 16)
temp = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(temp) #::2意为指定步长为2 为[start_index : end_index : step]省略end_index的写法
self.P[:, :, 1::2] = torch.cos(temp)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device) # torch 加法存在广播机制,因此可以避免batchsize不确定的问题
return self.dropout(X)
(4) Encoder
Transformer采用的是编码器-解码器结构。编码器(左)处理输入序列并返回特征向量(或存储向量);解码器(右)处理目标序列,并合并来自编码器存储器的信息。解码器的输出是我们模型的预测结果。
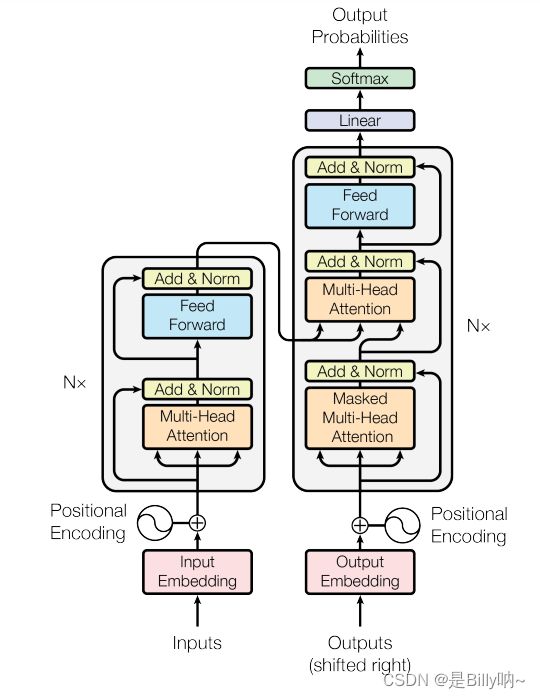
我们可以彼此独立地对编码器和解码器进行编写代码,然后将它们组合。首先,我们先构建编码器(Encoder),具体也包括下述两个步骤,先编写Encoder layer,然后编写Encoder module。
(4.1)Encoder layer
首先,构建残差连接功能模块:
class Residual(nn.Module):
def __init__(self, sublayer: nn.Module, d_model: int, dropout: float = 0.1):
"""
sublayer: Multi-Head Attention module 或者 Feed Forward module的一个.
残差连接:上述两个module的输入x和module输出y相加,然后再进行归一化。
"""
super().__init__()
self.sublayer = sublayer
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x: Tensor) -> Tensor:
return self.norm(x + self.dropout(self.sublayer(x)))
然后,构建feed_forward功能模块:
class FeedForward(nn.Module):
def __init__(self, d_model:int, hidden_num:int=2048) -> None:
super().__init__()
self.linear = nn.Sequential(
nn.Linear(d_model, hidden_num),
nn.ReLU(),
nn.Linear(hidden_num, d_model)
)
def forward(self, x):
return self.linear(x)
最后,构建Encoder layer:
class TransformerEncoderLayer(nn.Module):
def __init__(
self,
d_model: int = 512,
num_heads: int = 6,
dim_feedforward: int = 2048,
dropout: float = 0.1,
):
"""
d_model: 词向量维度数
num_heads: 多头注意力机制的头数
dim_feedforward: feedforward 模块的隐含层神经元数
"""
super().__init__()
"""
1. 进行多头注意力计算
"""
self.multi_head_attention_module = Residual(
sublayer=MultiHeadAttention(h=num_heads, d_model=d_model),
d_model=d_model,
dropout=dropout
)
"""
2. 进行前馈神经网络计算
"""
self.feed_forward_module = Residual(
sublayer=FeedForward(d_model=d_model, hidden_num=dim_feedforward),
d_model=d_model,
dropout=dropout
)
def forward(self, x:Tensor) -> Tensor:
# 1. 多头注意力计算
x = self.multi_head_attention_module(x)
# 2. 前馈神经网络计算
x = self.feed_forward_module(x)
return x
(4.2) Encoder module
将残差连接、Encoder layer、feed forward功能模块拼接成为Encoder module。
class TransformerEncoder(nn.Module):
def __init__(
self,
num_layers: int = 6,
d_model: int = 512,
num_heads: int = 8,
dim_feedforward: int = 2048,
dropout: float = 0.1,
max_len: int = 1000
):
"""
Transformer 编码器
num_layers: TransformerEncoderLayer 层数
d_model: 词向量维度数
num_heads: 多头注意力机制的头数
dim_feedforward: 前馈神经网络的隐含层神经元数
dropout:
max_len: 三角函数位置编码的最大单词数量,需要设置超过数据集中句子单词长度
"""
super().__init__()
"""
1. 实例化 num_layers 个TransformerEncoderLayer
"""
self.layers = nn.ModuleList([
TransformerEncoderLayer(d_model, num_heads, dim_feedforward, dropout)
for _ in range(num_layers)
])
"""
2. 初始化位置编码器
"""
self.pe = PositionalEncoding(num_hiddens=d_model, max_len=max_len)
def forward(self, x: Tensor) -> Tensor:
"""
x: (batchsize, sequence_number, d_model),sequence_number 表示句子的单词数量,d_model表示每个词的编码维度
"""
"""
1. 对输入x添加位置编码信息
"""
x = self.pe(x)
"""
2. 逐层计算,最后输出特征提取后的values
"""
for layer in self.layers:
x = layer(x)
return x