逻辑回归做分类预测-客户购买
目录
文章目录
前言
一、初始化
二、了解数据集
三、了解变量
四、特征处理
五、 建模
总结
前言
本文的主要内容是对银行客户进行分类 预测其是否会购买银行的定期存款产品。
以下内容主要展现简单的数据分析、画图、分类变量编码、数据缩放和逻辑回归完整过程。
变量含义:
· ID:客户唯一标识
· age:客户年龄
· job:客户的职业
· marital:婚姻状况
· education:受教育水平
· default:是否有违约记录
· balance:每年账户的平均余额
· housing:是否有住房贷款
· loan:是否有个人贷款
· contact:客户联系的沟通方式
· day:最后一次联系的时间(几号)
· month:最后一次联系的时间(月份)
· duration:最后一次联系的交流时长
· campaign:在本次活动中,与该客户交流过的次数
· pdays:距离上次活动最后一次联系该客户,过去了多久
· previous:在本次活动之前,与该客户交流过的次数
· poutcome:上一次活动的结果
· y:预测客户是否会订购定期存款业务
一、初始化
导入相关包和库
#数据处理包
import numpy as np
import pandas as pd
#画图
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
#建模
from sklearn.preprocessing import scale,LabelEncoder #用于数据预处理模块的缩放器、标签编码
from sklearn.model_selection import train_test_split #数据集分类器 用于划分训练集和测试集
from sklearn.metrics import classification_report,accuracy_score #评估预测结果
from sklearn.linear_model import LogisticRegression #需要使用的逻辑回归模型设置显示
#设置输出全部结果 而非只有最后一个
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
#设置正常显示负号和中文
%matplotlib inline
plt.rcParams['font.family'] = 'SimHei' #用来正常显示中文
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号导入数据
data = pd.read_csv("/逻辑回归做分类预测-客户购买/train_set.csv")
二、了解数据集
data.shape # 查看数据集结构
data.head() # 预览数据
data.isnull().sum() # 查看每一列的缺失值数量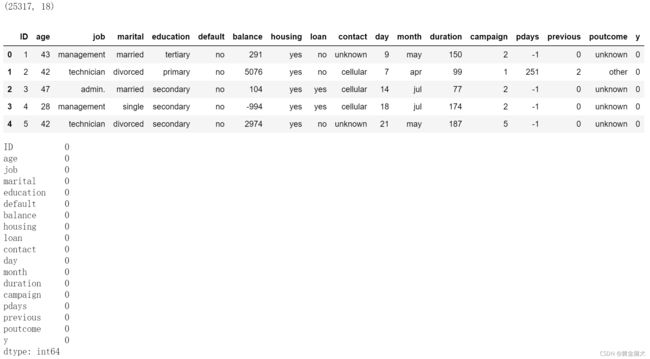
数据集共有25317行18列,特征变量中无缺失值。
除ID外,根据特征含义,有9个分类变量和7个数值(连续)变量。
data.info() # 查看特征类型 
三、了解变量
· 根据变量含义,将特征分为分类变量col_cate和数值变量col_num
· 对分类变量col_cate查看频率分布
· 对数值变量col_num查看数值分布
col_all = list(data.columns) # 全部特征
col_cate = ['job','marital','education','default','housing','loan','contact','month','poutcome'] # 分类特征
col_num = ['age','balance','day','duration','campaign','pdays','previous'] # 连续(数值)特征构建简单for循环 对每个分类变量查看各数据出现的次数 同时绘制直方图
for i in col_cate:
print(i,"特征的各数据出现次数:\n",data[i].value_counts()) # “\n”代表换行 value_counts()可设置参数ascending=True|False对结果升序|降序
plt.figure(figsize=(6,4)) # 新增一个画布
plt.hist(data[i],color="darkcyan") # 对该变量绘制直方图 选个自己喜欢的颜色参数~
plt.show()
print("--"*30,"\n") #分割线fig, ((ax1, ax2, ax3), (ax4, ax5, ax6), (ax7, ax8, ax9)) = plt.subplots(3, 3, figsize=(15, 8))
ax1.hist(data['job'],color="darkcyan")
ax2.hist(data['marital'],color="darkcyan")
ax3.hist(data['education'],color="darkcyan")
ax4.hist(data['default'],color="darkcyan")
ax5.hist(data['housing'],color="darkcyan")
ax6.hist(data['loan'],color="darkcyan")
ax7.hist(data['contact'],color="darkcyan")
ax8.hist(data['month'],color="darkcyan")
ax9.hist(data['poutcome'],color="darkcyan")
对数值型变量绘制直方图 查看数据分布
data[col_num].hist(bins=20,figsize=(15,10),color ="darkcyan") 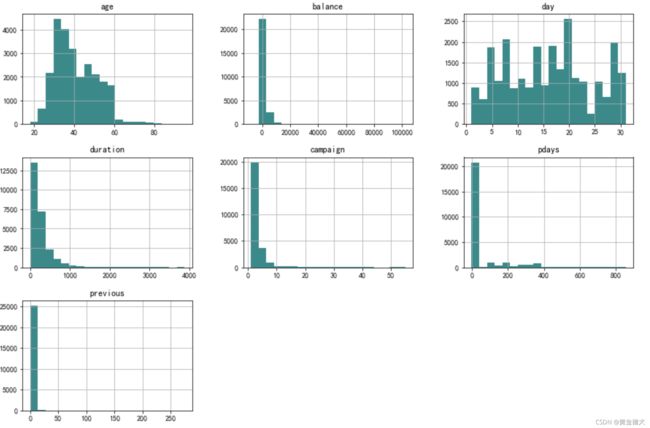
四、特征处理
· 结合实际含义观察各个特征变量 可以进一步探索or修正数据 方便起见 这里简单对分类变量进行编码 使其数值化并能够顺利拟合到模型中即可
· LabelEncode编码方式 能够自动将特征中不同的值对应为不同的数字 优点是简单直接 缺点是不一定有符合实际的数值含义
· 其他的编码方式还有One—Hot、get_dummy或map自定义方式 可按需使用
# 构建简单循环 对分类变量编码
for k in col_cate:
le = LabelEncoder()
data[k] = le.fit_transform(data[k])编码后我们所有的变量都数值化了,在此基础上我们再了解下目前的数据集
data.head()
data.describe() # 描述性统计
查看目前数据集中变量之间的相关系数
corr = data.corr()
plt.figure(figsize=(20,8))
sns.heatmap(data=corr,xticklabels=corr.columns,yticklabels=corr.columns,annot=True,cmap="YlGnBu_r") #参数annot设置为True可以将数值展示出来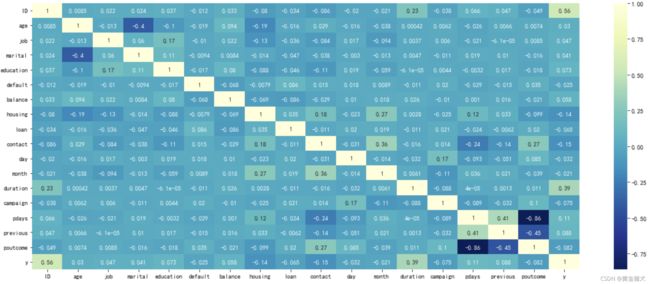
五、 建模
· 划分数据 对数据进行缩放处理
· 划分训练集和测试集
· 模型实例化+拟合训练集+预测测试集
· 对预测结果进行展示和评估
X = data.iloc[:,1:17].values # 从索引1开始 不含ID列
y = data.iloc[:,[17]].values对数据集进行划分 test_size参数设置为0.3 取其中30%的数据作为测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)模型实例化 对数据进行拟合
model = LogisticRegression() # 实例化逻辑回归模型
model_fit = model.fit(X_train,y_train) # 将训练集的特征和目标放进去调用模型的predict()方法 对测试集的特征数据进行预测 预测结果为y_pred
y_pred = model_fit.predict(X_test)查看预测得到的结果y_pred
y_pred=pd.DataFrame(y_pred) # 转化为DataFrame形式
y_pred.head() # 预览前五行
y_pred.value_counts() # 预测结果数据分布
y_pred.hist(color="darkcyan") # 绘制直方图查看分布
对预测结果进行评估
· accuracy_score 分类准确率分数 返回分类正确的样本占全部样本之比
· precision 精确度 TP/(TP+FP) 反映是否查准
· recall 召回率 TP/(TP+FN) 反映是否查全
· f1-score 调和平均值
print(accuracy_score(y_test,y_pred))
print(classification_report(y_test,y_pred))
predict是对客户是否购买的行为进行0或1预测 也可以采用predict_proba方式来预测每个客户产生0或1行为分别对应的概率
如下面的DataFrame所示 第一列结果就是该客户不购买的概率 第二列是该客户购买的概率 二者相加为1
y_pred_prob = model_fit.predict_proba(X_test) # 对结果的概率进行预测
y_pred_prob = pd.DataFrame(y_pred_prob) # 转化为DataFrame
y_pred_prob.head()
y_pred_prob.hist(color="darkcyan") # 绘制直方图查看分布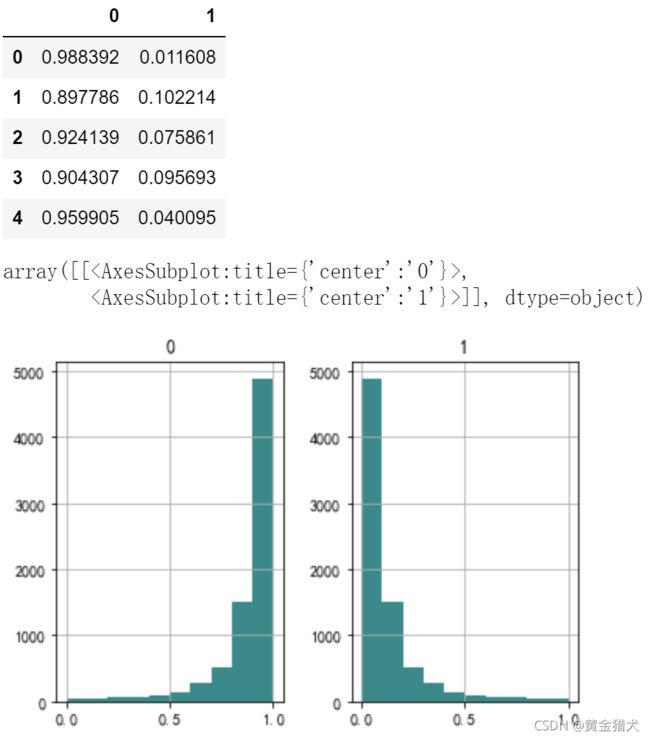
# 导出结果
result = y_pred_prob.iloc[:,[1]]
result.columns=["pred"]
result
# result.to_csv("result.csv")
总结
除了逻辑回归 还可以尝试其他分类模型(KNN、DecisionTreeClassifier、RandomForestClassifier、GradientBoostingClassifier等) 或者对特征进行进一步加工 来获得更好的预测结果