新手探索NLP(三)
目录
NLP语言模型
词的表示方法类型
1、词的独热表示one-hot representation
简介
不足
2. 词的分布式表示distributed representation
简介
建模类型
语言模型
Word Embedding
神经网络语言模型
NNLM
word2vec
Glove
Embedding from Language Models (ELMO)动态词向量
Generative Pre-Training(GPT)
Bert
NLP语言模型
语言模型包括文法语言模型和统计语言模型。一般我们指的是统计语言模型。
统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = 〈w1, · · · , wT 〉 ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。

语言模型计算一个句子的概率大小的这种模型。打分概率越高,这个句子越合乎人正常组织语言的用法和习惯。
常见的统计语言模型有N元文法模型(N-gram Model),最常见的是unigram model、bigram model、trigram model等等。形式化讲,统计语言模型的作用是为一个长度为 m 的字符串确定一个概率分布 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示这段文本中的各个词。一般在实际求解过程中,通常采用下式计算其概率值:
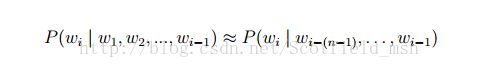
N-gram Model在我的新手探索NLP(一)中略有介绍。
词的表示方法类型
1、词的独热表示one-hot representation
简介
这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,(比如:0001000)这个维度就代表了当前的词。
不足
- 向量的维度会随着句子的词的数量类型增大而增大;
- “词汇鸿沟”现象:任意两个词之间都是孤立的,根本无法表示出在语义层面上词语词之间的相关信息。
2. 词的分布式表示distributed representation
简介
Harris 在 1954 年提出的分布假说( distributional hypothesis)为这一设想提供了理论基础:上下文相似的词,其语义也相似。Firth 在 1957 年对分布假说进行了进一步阐述和明确:词的语义由其上下文决定( a word is characterized by the company it keeps)。
分布式表示是一种低维实数向量。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的。
分布式表示最大的贡献就是让相关或者相似的词,在距离上更接近了,在一定程度上解决了独热表示的维度和词汇鸿沟问题。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
建模类型
1. 基于矩阵的分布表示
基于矩阵的分布表示通常又称为分布语义模型,这类方法需要构建一个“词-上下文”矩阵,从矩阵中获取词的表示。在“词-上下文”矩阵中,每行对应一个词,每列表示一种不同的上下文,矩阵中的每个元素对应相关词和上下文的共现次数。在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。
由于分布假说认为上下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。常见到的Global Vector 模型( GloVe模型)是一种对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示。
2. 基于聚类的分布表示
该方法以根据两个词的公共类别判断这两个词的语义相似度。最经典的方法是布朗聚类(Brown clustering)。
3. 基于神经网络的分布表示,词嵌入(word embedding)
基于神经网络的分布表示一般称为词向量、词嵌入( word embedding)或分布式表示( distributed representation)。
语言模型
Word Embedding
大概的过程就是将文本归总起来,单词用独热编码作为原始单词输入。之后乘以矩阵Q后获得向量 ,每个单词的 拼接,上接隐层,然后接softmax去预测后面应该后续接哪个单词。这个 是什么?这其实就是单词对应的Word Embedding值,那个矩阵Q包含V行,V代表词典大小,每一行内容代表对应单词的Word embedding值。只不过Q的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵Q,当这个网络训练好之后,矩阵Q的内容被正确赋值,每一行代表一个单词对应的Word embedding值。所以你看,通过这个网络学习语言模型任务,这个网络不仅自己能够根据上文预测后接单词是什么,同时获得一个副产品,就是那个矩阵Q,这就是单词的Word Embedding是被如何学会的。
前面提过,one-hot表示法具有维度过大的缺点,那么现在将vector做一些改进:1、将vector每一个元素由整形改为浮点型,变为整个实数范围的表示;2、将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间。

不足: 无法区分多义词的不同语义。
神经网络语言模型
a) Neural Network Language Model ,NNLM
b) Log-Bilinear Language Model, LBL
c) Recurrent Neural Network based Language Model,RNNLM
d) Collobert 和 Weston 在2008 年提出的 C&W 模型
e) Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
NNLM
NNLM由Bengio等人提出,他的主要想法就是:
- 把字典里的每一个单词对应一个词特征向量
- 把单词序列表示成联合概率函数
- 自动学习词特征向量和概率函数的参数
在NNLM中,每一个单词为向量空间中的一个点,而且特征的数目要比字典的大小要小,它的概率函数表示为在给定前一个词下,后一个词的条件概率的乘积。
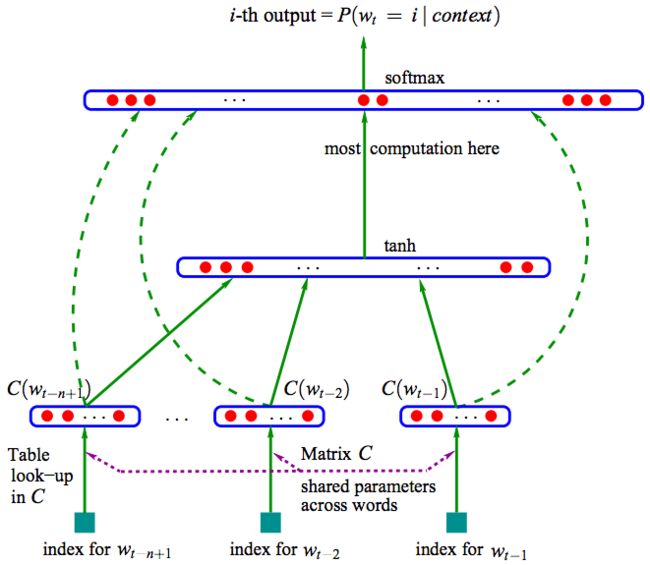
输入:
- 首先是对整个词汇表建立一个索引,每个单词对应一个索引号,其实就是one-hot编码
- one-hot编码建立索引矩阵D,维度为 (n−1)×|V|,即每一行代表一个单词的one hot。
- 而矩阵C每一行为一个单词的词向量,这样D⋅C就抽取出对应单词的向量了,这就是图中的table look-up in c
- 找出对应的词向量后,将这些词向量拼接在一起,形成一个 (n−1)m维的列向量x
- 经过隐含层tanh函数的激活,再经过softmax输出层的输出,这就得到了函数g的输出向量。
输出:函数g把输入的上下文单词的特征向量(C(wt−n+1),...,C(wt−1))映射为下一个单词wt的条件概率分布函数,当然,这个单词wt在字典V中。
word2vec
实现CBOW( Continuous Bagof-Words)和 Skip-gram 语言模型的工具正是word2vec。
2013年,Google团队发表了word2vec工具。word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种近似训练法:负采样(negative sampling)和层序softmax(hierarchical softmax)。值得一提的是,word2vec的词向量可以较好地表达不同词之间的相似和类比关系。
在开始之前,引入模型复杂度,定义如下:
O = E * T * Q
其中,E表示训练的次数,T表示训练语料中词的个数,Q因模型而异。E值不是我们关心的内容,T与训练语料有关,其值越大模型就越准确,Q在下面讲述具体模型是讨论。
Glove
Glove是斯坦福大学Jeffrey Pennington等人提出的,他们认为虽然skip-gram模型在计算近义词方面比较出色,但它们只是在局部上下文窗口训练模型,并且它很少使用语料中的一些统计信息,因此Jeffrey Pennington等人又提出了一个新型模型GloVe。。
词-词共现计数矩阵可以表示为X,则Xij为单词j出现在单词i上下文中的次数。Xi=ΣkXik表示任何词出现在单词i上下文中的次数,Pij=P(j|i)=Xij/Xi表示单词j出现在单词i上下文中的比率。
例如i=ice, j=steam,假设有共现词k,但是k与ice的联系要比与steam的联系强,也就是说单词k与ice出现的概率比与 steam出现的概率大,比如说k=solid,那么我们认Pik/Pjk会很大。相似地,如果单词k与steam的联系比与ice的联系强,例如k=gas,那么Pik/Pjk的比率会很小,对于其他的单词k如water, fashion与ice,steam联系都强或都不强的话,则Pik/Pjk的比率会接近1。
这个比率就能区别相关词(solid, gas)和不相关词(water, fashion),并且也能区别这两个相关的词(solid, gas)。那么得到的向量可能为ice-steam=solid-gas,这与word2vec相似。
word2vec和glove的区别:
Omer Levy等人对基于计数的方法和基于embedding的方法做了对比,发现它们之间并没有非常大的差距,在不同的场景各个模型发挥不同的作用,它们之间并没有谁一定优于谁,相比于算法而言,增加语料量,进行预处理以及超参数的调整显得非常重要。特别指出,基于negtive sampling的skip-gram模型可以作为一个基准,尽管对不同的任务它可能不是最好的,但是它训练快,占用内存和磁盘空间少。
Embedding from Language Models (ELMO)动态词向量
对于一个多义词,它事先学好的Word Embedding中混合了几种语义 。此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 的上下文去正确预测单词 , 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。这个网络结构其实在NLP中是很常用的。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 ,句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
它首先在大文本语料库上预训练了一个深度双向语言模型(bilm),然后把根据它的内部状态学到的函数作为词向量。实验表明,这些学到的词表征可以轻易地加入到现有的模型中,并在回答问题、文本蕴含、情感分析等 6 个不同的有难度的 NLP 问题中大幅提高最佳表现。实验表明显露出预训练模型的深度内部状态这一做法非常重要,这使得后续的模型可以混合不同种类的半监督信号。
ELMo与word2vec、glove最大的不同:
即词向量不是一成不变的,而是根据上下文而随时变化,这与word2vec或者glove具有很大的区别。
Generative Pre-Training(GPT)
与ELMo的区别:
首先,特征抽取器不是用的RNN,而是用的Transformer,其特征抽取能力要强于RNN;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 单词的上下文去正确预测单词 , 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。
GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
Transformer:
Transformer是个叠加的“自注意力机制(Self Attention)”构成的深度网络,是目前NLP里最强的特征提取器。Transformer同时具备并行性好和适合捕获长距离特征两大优点。大有取代CNN和RNN之势。
Bert
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。
通常而言,绝大部分NLP问题可以归入上图所示的四类任务中:
一类是序列标注,这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
第二类是分类任务,比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。
第三类任务是句子关系判断,比如Entailment,QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系。
第四类是生成式任务,比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。
上面列出的NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性。
参考资料:
- http://licstar.net/archives/328
- https://blog.csdn.net/Scotfield_msn/article/details/69075227
- https://blog.csdn.net/m0_37565948/article/details/84989565
- https://zhuanlan.zhihu.com/p/49271699