循环神经网络及Pytorch实现
1.概述
循环神经网络简称RNN,与之前的神经网络不同的是:它的输入包含了上一层的输出和原始输入。非常适合处理序列问题,序列问题中的上一个序列对下一个序列会产生影响,这正是RNN模型中的输入。目前的RNN模型有传统的RNN模型、GRU模型、LSTM模型、Bi-GRU模型、Bi-LSTM模型。正因为RNN模型中上一层的输出也是下一层的输入,所以RNN模型不能进行并行计算。
2.RNN模型
主要概念:
主要就是上一步的输出作为下一步的一部分输入,这样就有效的利用了上一个序列的结果(很符合自然语言序列输入)
以序列数据为输入,通过网络内部的结构设计有效捕获序列之间的关系特征,一般也是以序列形式进行输出
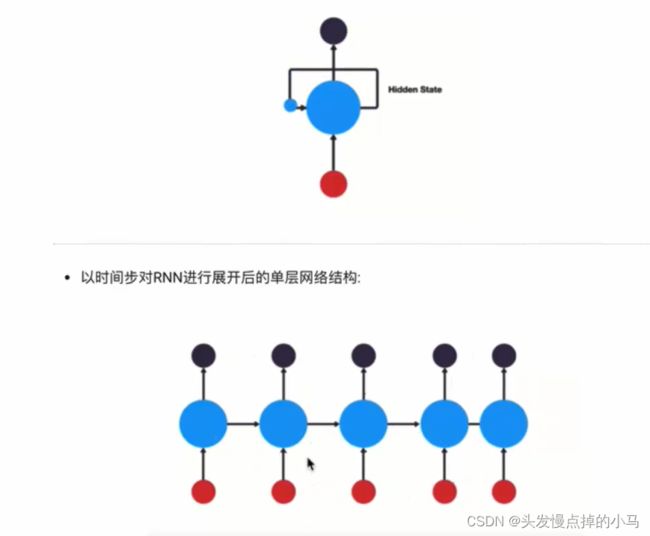
RNN的循环机制使模型隐层上一时间步产生的结果,能够作为当下时间步输入的一部分(就是下一步的输入除了正常的输入还包括上一步的隐层输出)
RNN结构能很好的利用序列之间的关系,针对大自然具有连续的输入序列,如人类语言都进行很好的处理,可以广泛运用在NLP中:对于一个语言文本,正常输入是一个一个词的输入,但是RNN将上一步的输出也作为下一步的输入进行处理(就很好的结合了前面词的意思(序列))

RNN模型的分类:
按输入输出的结构:
-
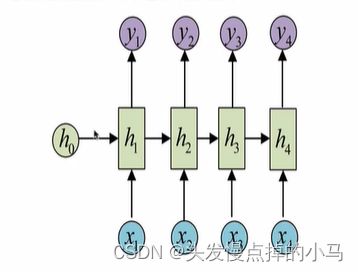
N vs N N个输入对应N个输出
输入和输出序列是等长,适用范围比较小,可以用来生成等长度的合理诗句
-
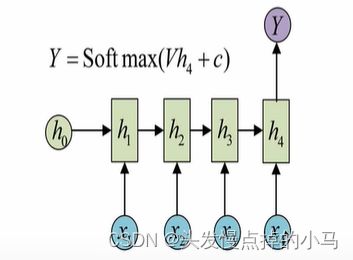
N vs 1 N个输入对应1个输出
输入是一个序列,只要求输出一个单独的值而不是序列,只要在最后的一个隐层输出h上进行线性变换就可以了。这种结构经常被应用在文本分类问题上面。
-
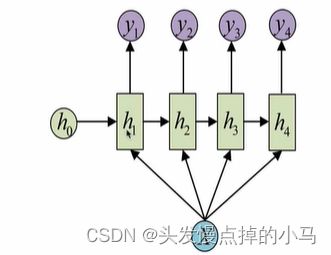
1 vs N 1个输入对应N个输出
将输入作用在每次的输入之上,这种结构可以用于将图片生成文字任务
-
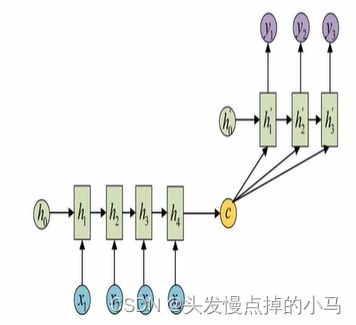
N vs M N个输入对应M个输出
不限输入和输出的RNN结构,由编码器(N vs 1)和解码器(1 vs N)两部分组成,两者的内部结构都是某类RNN,被称为seq2seq架构。
输入数据先通过解码器最终输出一个隐含变量c,然后将隐含变量c作用在解码器的每一步上面。
可以广泛的用于机器翻译、阅读理解、文本摘要等(最广泛的模型)
内部构造分类:
-
传统RNN
-
LSTM
-
Bi-LSTM
-
GRU
-
Bi-GRU
3.典型RNN结构:
(1)传统RNN结构:
model结构
主要是三个组成部分:
-
拼接:将正常输入和上一层的输入拼接成一个张量
-
全连接层:与神经网络的全连接一致
-
激活函数:tanh() 将神经网络的输出压缩至[-1,1]之间
优势:
-
内部结构简单 参数量比较少 在短序列任务上性能和效果都比较好
缺点:
-
在解决长序列问题时,传统RNN模型表现较差,主要是因为在进行反向传播时过长的序列导致梯度的计算异常,发生梯度消失或爆炸(权重无法更新 导致权重更新失败)
代码实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
# 初始化隐状态 (隐藏层数,批量大小,隐藏单元数)
state = torch.zeros((1, batch_size, num_hiddens))
print(state.shape) # torch.Size([1, 32, 256])
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
print(Y.shape) # torch.Size([35, 32, 256]) 时间,批量大小,输出
print(state_new.shape) # torch.Size([1, 32, 256])
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# torch中的RNN模型值包含了隐藏层,没有输出层 所以得自己定义输出层
if not self.rnn.bidirectional:
self.num_directions = 1
# 输出层
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层将Y的形状改成(时间步数*批量大小,隐藏单元数)
# 输出形状为(时间步数*批量大小,词表大小)
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
return torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)(2)LSTM模型
概念及模型:
Long Short-Term Memory 长短时记忆结构
是传统RNN的变体,与经典的RNN相比能够有效找到长序列之间的语义关联,缓解梯度消失或者爆炸现象。(比RNN结构更复杂一点,参数更多)
主要有四个部分:
-
遗忘门
-
输入门
-
细胞状态
-
输出门
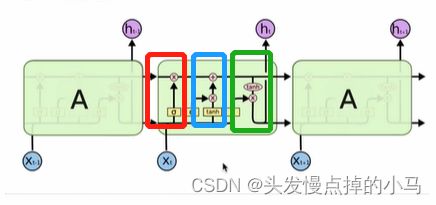
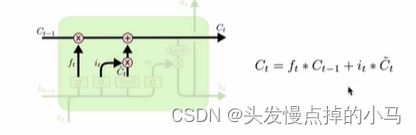
遗忘门:
红色框对应的结构 代表遗忘过去多少信息
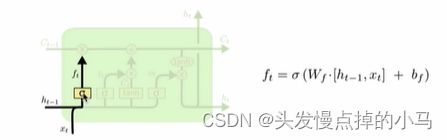
将上层的输出和原始输入拼接后进行全连接后经过sigmiod函数(将函数的值压缩到(0,1)之间)输出f(t)
输入门:
蓝色框代表的结构 两个分支然后合成一个
i(t)相当于一个门值
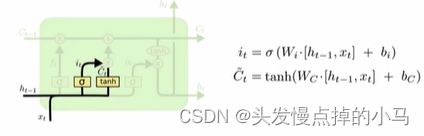
Ct更新公式:i(t)*c(t)就是很明显的门值作用 有三个参数
输出门:
绿色框代表的结构
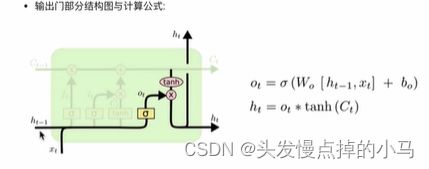
优势:
-
长序列比较好
-
缓解了梯度消失或者爆炸
缺点:
-
算法较复杂,需要算力较强
代码实现:
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)Bi-LSTM:
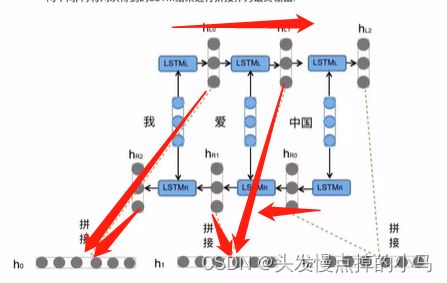
将输入序列进行“从左向右”和“从右向左”两次的LSTM处理,将得到的结果张量进行拼接作为最终输出
(捕捉到了一些特置的前置或者后置特征 增强了语义关联)计算复杂度也增加了
(3)GRU模型
概念及模型:
Gated Recurrent Unit 门控循环单元结构 也是传统RNN变形,跟LSTM一样能获取长序列之间的语义关联,但是结构比LSTM模型更简单一点(参数少一点)
主要是:可以选择看哪些序列比较重要,对重要的序列多看一下
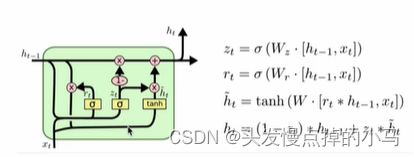
内部结构:
-
更新门(能被关注的机制)
-
重置门(能遗忘的机制)
输入:当前正常输入x和上一步的输出h(t-1)
z(t)更新门 r(t)重置门
代码实现:
from torch import nn from torch.nn import functional as F from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu() num_epochs, lr = 500, 1 num_inputs = vocab_size gru_layer = nn.GRU(num_inputs, num_hiddens) model = d2l.RNNModel(gru_layer, len(vocab)) model = model.to(device) d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
Bi-GRU:
与Bi-LSTM一致 从左到右输入一次,从右到左输入一次
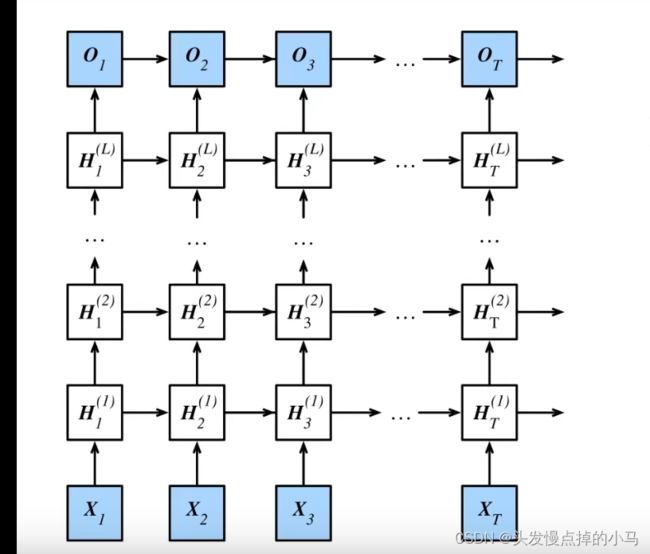
(4)深度循环神经网络
概念:
输入层和输出层之间有多个隐藏层
代码实现:
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过num_layers来指定隐藏层层数
vocab_size, num_hiddens, device,num_layers = len(vocab), 256, d2l.try_gpu(),2
num_epochs, lr = 500, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs,num_hiddens,num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)(5)双向RNN
概念:
又考虑“从前往后实现”,又考虑“从后往前实现”。
不能做预测,可以做句子的特征提取,在机器翻译时从前往后和从后往前都考虑
主要有:
-
Bi-LSTM
-
Bi-GRU