大数据平台实时数仓从0到1搭建之 - 12 Maxwell
大数据平台实时数仓从0到1搭建之 - 12 Maxwell
- 概述
- Maxwell
- quickstart
- 修改MariaDB配置
- Maxwell docker 下载
- maxwell测试
-
- stdout:输出控制台
- kafka
- 后续
- 附客户端代码
概述
今天学习下Mysql数据库的实时数据采集,看着网上比较流行的有阿里的
Canal和Maxwell,看着GitHub上还是用Canal的的人多一点,可能是因为阿里的开源项目。不过,工具不在乎背景,适合自己的才是最好的。
初次认识到这两个工具,先从实践来看下两个工具的相似和不同。
阿里Canal的地址:https://github.com/alibaba/canal
Maxwell
Maxwell 是一个旧金山的小哥写的用于读取Mysql Binlog的程序,本来只是为了写入kafka,后来又支持了Kinesis、Nats、Google Cloud Pub/Sub、RabbitMQ、Redis、SNS。
官网:Maxwell官网地址
GitHub:https://github.com/zendesk/maxwell
quickstart
Maxwell的介绍及配置只有两页,讲了如何使用,以及所有的配置,具体可以参考官网。
修改MariaDB配置
修改
/etc/my.cnf.d/server.cnf,在[server]下添加代码才可以。
尝试了修改/etc/my.cnf,不好使
修改配置
[root@server111 software]# vim /etc/my.cnf.d/server.cnf
[server]
server_id=1
log-bin=master
binlog_format=row
[root@server111 maxwell-1.34.1]# systemctl stop mariadb
[root@server111 maxwell-1.34.1]# systemctl start mariadb
添加maxwell用户,并授权
[root@server111 maxwell-1.34.1]# mysql -uroot -proot
MariaDB [(none)]> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
MariaDB [(none)]> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
MariaDB [(none)]> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
Maxwell docker 下载
尝试了下载安装包的形式安装,结果报错了,发现Maxwell需要的是jdk1.8以上版本,跟我本地环境不太兼容,所以就干脆使用docker安装。关于docker的安装配置见上一篇
jdk1.8无法启动Maxwell
[root@server113 ~]# docker pull zendesk/maxwell
maxwell测试
stdout:输出控制台
[root@server113 ~]# docker run -it --rm zendesk/maxwell bin/maxwell --user='maxwell' --password='maxwell' --host='192.168.1.111' --producer=stdout --filter="include:test.test"
命令:
-it :docker 的参数,分配伪终端,以交互式运行
--rm:docker的参数,结束后删除容器
zendesk/maxwell:docker 的参数,使用这个镜像创建容器
bin/maxwell:docker 的参数,创建容器后,执行这个命令
--user:maxwell的参数,mysql master的账户
--password:maxwell的参数,mysql master的密码
--host:maxwell的参数,mysql master的主机地址
--producer=stdout:maxwell的参数,输出到控制台
--filter:maxwell的参数,过滤器。include:test.test:只包含test库下的test表
创建test库,test表
create table test(
id int,
name varchar(255)
);
#执行如下sql
insert into test values(1,'hello world');
insert into test values(2,'hello maxwell');
执行上面两个insert,控制台输出如下信息,还有其他日志信息,就不展示了
{"database":"test","table":"test","type":"insert","ts":1633519433,"xid":6773,"commit":true,"data":{"id":1,"name":"hello world"}}
{"database":"test","table":"test","type":"insert","ts":1633519504,"xid":6866,"commit":true,"data":{"id":2,"name":"hello maxwell"}}
kafka
来来来,报错了,执行如下命令,默认日志级别没有任何报错,kafka消费者也没有任何输出
[root@server113 ~]# docker run -it --rm zendesk/maxwell bin/maxwell --user='maxwell' --password='maxwell' --host='192.168.1.111' --producer=kafka --kafka.bootstrap.servers='192.168.1.112:9092' --kafka_topic=maxwell --filter="include:test.test"
还以为是kafka的问题,最后调整日志级别为debug,发现错误信息,看到报错都懵逼了,新下的docker镜像,命令里也没有用到hostname,报错居然是hostname无法解析?
日志级别:--log_level=debug
[root@server113 ~]# docker run -it --rm zendesk/maxwell bin/maxwell --user='maxwell' --password='maxwell' --host='192.168.1.111' --producer=kafka --kafka.bootstrap.servers='192.168.1.112:9092' --kafka_topic=maxwell --filter="include:test.test" --log_level=debug
java.io.IOException: Can't resolve address: server111:9092
java.io.IOException: Can't resolve address: server110:9092
java.io.IOException: Can't resolve address: server112:9092
..
Caused by: java.nio.channels.UnresolvedAddressException
知道问题所在,就好解决了,在docker参数里加了-v,挂载本地hosts到容器中,即可解决问题
[root@server113 opt]# docker run -v /etc/hosts:/etc/hosts \
-it --rm zendesk/maxwell bin/maxwell \
--host=192.168.1.111 --user=maxwell --password=maxwell \
--producer=kafka \
--kafka.bootstrap.servers=192.168.1.110:9092 --kafka_topic maxwell
#执行sql
insert into test values(2,'hello maxwell');
insert into test values(3,'hello kafka');
delete from test where id=2;
shell消费者输出结果

idea消费者输出结果

delete出现了两条记录,后期再说,从数据上看,筛选commit那条就行,有待测试。
后续
关于ip变hostname的问题,我再看下源码,我以为很容易找到,还是年轻了,文章先发出来了,我再接着看下源码,希望路过的大神有知道的可以告知下。
//后续//
错怪maxwell了,我看了源码里就是直接获取的配置内容,没有经过加工。
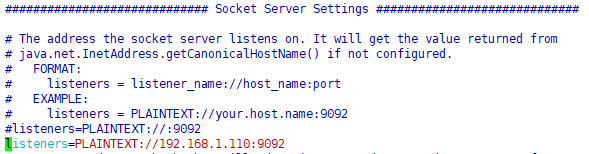
最后发现是kafka配置有问题,外网监听,如果不配置的话,默认走的getCanonicalHostName(),返回主机名,
修改三个节点上机器/opt/modules/kafka_2.11-2.4.1/config/server.properties,修改对应的listeners,解决问题,不需要映射hosts。
附客户端代码
package com.z
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import java.util.Properties
/**
* @author wenzheng.ma
* @date 2021-10-06 17:23
* @desc
*/
object MaxwellDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度1
env.setParallelism(1)
//topic
val topic = "maxwell"
//kafka的配置信息
val prop = new Properties()
prop.setProperty("bootstrap.servers", "server110:9092,server111:9092,server112:9092")
prop.setProperty("group.id", "test-group")
//创建kafka数据源
val kafka = new FlinkKafkaConsumer[String](topic, new SimpleStringSchema(), prop)
//添加kafka数据源
val inputStream = env.addSource(kafka)
//打印结果
inputStream.print()
//阻塞进程,一直等待数据
env.execute()
}
}