flink-on-k8s-operator部署安装及alink集成
flink-on-k8s-operator、Alink集成部署安装
[[Google官方参考文档]]: (Google_README.md)
1. 获取源码
## 下载源码
git clone https://github.com/leihongyang/flink-on-k8s-operator.git
git checkout pinnet
2. 准备镜像
从海外构建的镜像有:
FROM gcr.io/flink-operator/flink-operator:latest
## 和
FROM gcr.io/flink-operator/deployer:webhook-cert
pull到本地后,进行相应更名并上传harbor,参考spark-operator部署中的镜像获取方式
## flink-operator,管理flink任务生命周期
docker tag gcr.io/flink-operator/flink-operator:latest xxxxx:8000/spark-operator/flink-operator:latest
## 一键部署时需要,暂不了解用途 TODO
docker tag gcr.io/flink-operator/deployer:webhook-cert xxxxx:8000/spark-operator/deployer:webhook-cert
另外额外需要flink和hdfs镜像,可直接docker pull
## 这是flink基础镜像,后面集成alink需要基于这个镜像进行二次加工
docker pull flink:1.12.2-scala_2.12-java8
## 这是在flink集群中和hdfs进行文件获取所用
docker pull gchq/hdfs:3.2 && docker tag gchq/hdfs:3.2 xxxxx:8000/spark-operator/hdfs:3.2
3. 安装及Demo
1) 方式1
cd flink-on-k8s-operator
cd helm-chart/flink-operator
## 执行更新脚本
./update_template.sh
## 修改templates/flink-operator.yaml中的镜像为本地镜像
image: xxxxx/kubesphere/kube-rbac-proxy:v0.4.1
## 设置本地镜像及namespace
export IMG=xxxxx:8000/spark-operator/flink-operator:latest
export NS=flink-operator-system
## 创建crd
kubectl apply -k ../../config/crd
## 将chart中crd文件移除,因为有bug,无法自动安装crd,应该是版本问题,google官方给的文档是基于k8s-1.17的版本
mv templates/flink-cluster-crd.yaml templates/flink-cluster-crd.yaml.bak
## 尝试安装flink-operator-chart
helm install flink-operator . --set operatorImage.name=xxxxx:8000/spark-operator/flink-operator:latest,flinkOperatorNamespace.name=flink-operator-system,flinkOperatorNamespace.create=false
- 方式2
## 部署operator
## 修改Makefile中 IMG 参数,其他参数默认即可
cp kustomize /usr/bin/
make deploy
## flink集群有两种运行模式,一种session集群,一种jobcluster。
## session模式:
## 预先创建集群,多个任务共享集群资源,资源隔离性差,但是提交任务快,适合测试任务以及对隔离性要求不高的任务
## jobcluster模式:
## 每次提交任务都会新建一个集群,资源隔离性最高,但是创建集群耗时较长,不适合小任务执行
## 部署session模式
## 修改config/samples/flinkoperator_v1beta1_flinksessioncluster.yaml中镜像为本地镜像
kubectl apply -f config/samples/flinkoperator_v1beta1_flinksessioncluster.yaml
## 验证session模式
kubectl get pod
NAME READY STATUS RESTARTS AGE
pod/flinksessioncluster-sample-jobmanager-0 1/1 Running 0 35m
pod/flinksessioncluster-sample-taskmanager-0 2/2 Running 0 35m
## 运行示例
cat <<EOF | kubectl apply --filename -
apiVersion: batch/v1
kind: Job
metadata:
name: my-job-submitter
spec:
template:
spec:
containers:
- name: wordcount
image: flink:1.9.3
args:
- /opt/flink/bin/flink
- run
- -m
- flinksessioncluster-sample-jobmanager:8081
- /opt/flink/examples/batch/WordCount.jar
- --input
- /opt/flink/README.txt
restartPolicy: Never
EOF
## jobcluster模式
## 该模式在operator部署完成后,让k8s可以直接理解flink语言,无需像session一样部署集群,直接编写任务yaml即可
## 官方已经提供了demo,只需要修改image参数即可,修改为本地镜像
kubectl apply -f config/samples/flinkoperator_v1beta1_flinkjobcluster.yaml
## tips:
## 由于google官方的operator对flink的稳定支持尚处于flink<=1.9.3版本,对>=1.10的版本支持不太成熟,按上述步骤进行运行的时有可能发生## OOM错误,在yaml中添加如下参数(带注释部分)即可:
flinkProperties:
taskmanager.numberOfTaskSlots: "1"
jobmanager.heap.size: "" # set empty value (only for Flink version 1.11 or above)
jobmanager.memory.process.size: 600mb # job manager memory limit (only for Flink version 1.11 or above)
taskmanager.heap.size: "" # set empty value
taskmanager.memory.process.size: 1gb # task manager memory limit
4. Alink集成
Alink集成其实就是将alink相关的jar放入flink基础镜像中,但是alibaba对新版本hadoop及hive支持不及时,需要在其源码上手动修改相关依赖版本, vim pom.xml
- 2.11
- 2.11.11
+ 2.12
+ 2.12.2
...
- 0.11.2
+ 0.13
## 打包依赖
cd Alink && mvn -Dmaven.test.skip=true clean package shade:shade
## 下载额外依赖
## 临时容器
docker run -itd --name flink flink:1.12.2-scala_2.12-java8 bash
docker exec -it flink bash
## 在容器中下载依赖文件
apt update && apt install -y python3.7 python3-pip --fix-missing && \
ln -s /usr/bin/python3.7 /usr/bin/python && ln -s /usr/bin/pip3 /usr/bin/pip && \
pip install pyalink && download_pyalink_dep_jars -d
## 退出容器并将依赖文件拷贝到外面
mkdir alink && cd alink
docker cp flink:/usr/local/lib/python3.7/dist-packages/pyalink/lib lib
## 删除s3和oss相关依赖,会导致bug
rm -rf lib/plugins/flink-1.12/o*
rm -rf lib/plugins/flink-1.12/s3*
## 删除alink_core_flink依赖
rm -rf lib/alink_core_flink-1.12_2.11-1.3.2.jar
## 复制之前Alink编译的内核依赖到此lib目录
cp ../core/target/alink_core_flink-1.12_2.12-1.3-SNAPSHOT.jar lib/
## 下载监控相关依赖
wget https://repo1.maven.org/maven2/org/apache/flink/flink-metrics-prometheus_2.12/1.12.2/flink-metrics-prometheus_2.12-1.12.2.jar
mv flink-metrics-prometheus_2.12-1.12.2.jar lib/
## 编写Dockerfile文件, 添加以下内容
================
FROM flink:1.12.2-scala_2.12-java8
ADD lib/* lib/
RUN echo "classloader.resolve-order: parent-first" >> conf/flink-conf.yaml
================
## 编译镜像并上传
docker build -t xxxxx:8000/spark-operator/alink:1.12.2 .
docker push xxxxx:8000/spark-operator/alink:1.12.2
5. 运行示例
## 编写算法任务yaml文件,内容如下
apiVersion: flinkoperator.k8s.io/v1beta1
kind: FlinkCluster
metadata:
name: alink12
spec:
image:
name: xxxxx:8000/spark-operator/alink:1.12.2
jobManager:
ports:
ui: 18081
resources:
limits:
memory: "1024Mi"
cpu: "200m"
taskManager:
replicas: 2
resources:
limits:
memory: "1024Mi"
cpu: "200m"
job:
jarFile: /cache/this.jar
className: com.alibaba.alink.ALSExample
# args: ["--input", "./README.txt"]
parallelism: 2
volumes:
- name: cache-volume
emptyDir: {}
volumeMounts:
- mountPath: /cache
name: cache-volume
initContainers:
- name: hdfs-client
image: xxxxx:8000/spark-operator/hdfs:3.2
command: ["hdfs"]
args:
- "dfs"
- "-copyToLocal"
- "hdfs://10.10.12.141:9000/tmp/demo2/original-alink_examples_flink-1.12_2.12-1.3-SNAPSHOT.jar"
- "/cache/this.jar"
flinkProperties:
taskmanager.numberOfTaskSlots: "1"
jobmanager.heap.size: "" # set empty value (only for Flink version 1.11 or above)
jobmanager.memory.process.size: 600mb # job manager memory limit (only for Flink version 1.11 or above)
taskmanager.heap.size: "" # set empty value
taskmanager.memory.process.size: 1gb # task manager memory limit
## 运行上述文件
kubectl apply -f demo.yaml

验证结果:
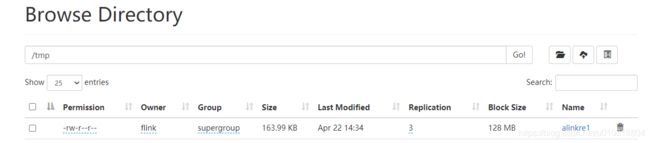
6. 带有监控指标数据的运行示例
apiVersion: flinkoperator.k8s.io/v1beta1
kind: FlinkCluster
metadata:
name: alink12
spec:
image:
name: xxxxx:8000/spark-operator/alink:1.12.2
pullPolicy: Always
# Activate metric exporter
envVars:
- name: HADOOP_CLASSPATH
value: /opt/flink/lib/flink-metrics-prometheus_2.12-1.12.2.jar
jobManager:
extraPorts:
- name: prom
containerPort: 9249
ports:
ui: 8081
resources:
limits:
memory: "1024Mi"
cpu: "200m"
taskManager:
extraPorts:
- name: prom
containerPort: 9249
replicas: 2
resources:
limits:
memory: "1024Mi"
cpu: "200m"
job:
jarFile: /cache/this.jar
className: com.alibaba.alink.ALSExample
# args: ["--input", "./README.txt"]
parallelism: 2
volumes:
- name: cache-volume
emptyDir: {}
volumeMounts:
- mountPath: /cache
name: cache-volume
initContainers:
- name: hdfs-client
image: xxxxx:8000/spark-operator/hdfs:3.2
command: ["hdfs"]
args:
- "dfs"
- "-copyToLocal"
- "hdfs://10.10.12.141:9000/tmp/demo2/original-alink_examples_flink-1.12_2.12-1.3-SNAPSHOT.jar"
- "/cache/this.jar"
flinkProperties:
taskmanager.numberOfTaskSlots: "1"
jobmanager.heap.size: "" # set empty value (only for Flink version 1.11 or above)
jobmanager.memory.process.size: 600mb # job manager memory limit (only for Flink version 1.11 or above)
taskmanager.heap.size: "" # set empty value
taskmanager.memory.process.size: 1gb # task manager memory limit
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
mory.process.size: 600mb # job manager memory limit (only for Flink version 1.11 or above)
taskmanager.heap.size: “” # set empty value
taskmanager.memory.process.size: 1gb # task manager memory limit
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter