我与ModelArts的不解之缘
我们常把机器学习描述为一种使用数据模式标记事物的神奇技术,也是我等程序猿在自身进阶路上比较难攀的高峰。光是看随机森林、贝叶斯网络等算法名字,就让人感到很是艰涩。
一个偶然的机会,去年12月份,我得知华为云发布ModelArts公测的消息,在了解华为云ModelArts的功能之后,我同期报名参加了一场基于华为云ModelArts完成图像识别的小规模比赛:在用不到两个小时的时间内,分别完成面包识别和华为云吉祥物“元宝”识别两项任务。在比赛的过程中,我发现通过华为云ModelArts的自动学习功能,那些不懂ML算法、仅具备鼠标拖拽技能的同学,就可以训练出自己的图像或者声音识别模型,这让我不得不感叹华为云ModelaArts真是降低机器学习小白上手门槛的高(jian)级(dan)利器。
如今,我有幸第二次参与华为云ModelArts的体验活动,相比上一次的比赛,这一次的体验,应该是说轻车熟路了。下面我将结合我的实际操作,为大家揭开华为云ModelArts的真实面目。
使用ModelArts过程中的感受:简单与不简单
这次体验我个人使用了如下两个场景:
第一个场景是华为云公测比赛时候的考题: 无人面包店中,用户将选中的面包放到指定位置,系统通过摄像头自动识别面包种类,然后进行结算。再次做这个试验的目的,通过几个月前的记忆,走一遍机器学习的流程: 准备数据à数据标注à模型训练à模型部署。过程中使用华为云一站式搞定所有,将训练数据全部上传到OBS目录上,在ModelAtrs中创建项目并关联到对应目录,就可以对上传的图片数据进行标注了,这些环节很简单,属于体力活,但是也要注意标注环节勾选面包物体的精准,会影响后面的模型准确度,我第一次勾选的时候很大条,训练出来89%的准确率。不过也没有关系,返回数据标注环节,对已经标注的数据重新微调也是非常方便,然后重新进行模型训练。 尽管是自动学习,ModelArts还是给我们留出了一些选择的权利,用户是可以自定义训练和推理时间,这样后台会去自动选择对应最优复杂度的算法,在训练时间和模型准确度上做一个平衡。
下面配图及说明用来解释关键步骤:

图1,数据标注环节,在这里看到所有图片数据的标注进度

图2,标注过程中,用鼠标框选住目标区域,上面有两个按钮:显示标注和隐藏标注,对于标注叠加的目标物体很有用
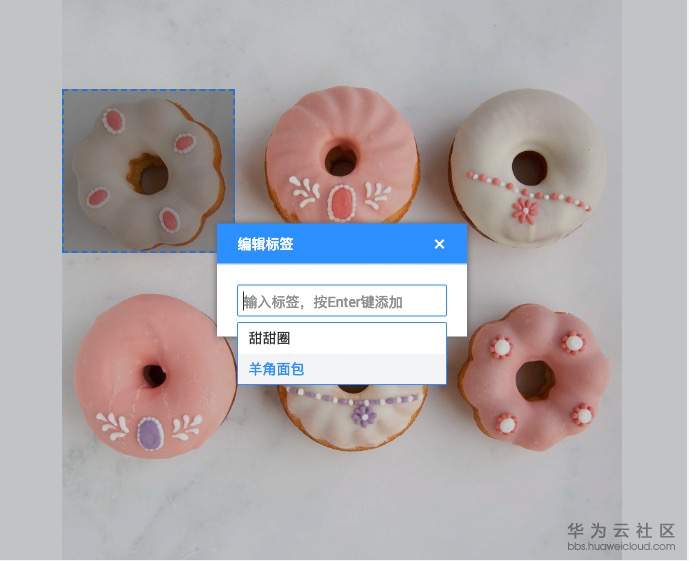
图3,编辑标签很方便,鼠标框选完成,自动弹出标签选择窗口,同时对历史标签进行了缓存

图4,标注的越仔细,训练的效果越好

图5,训练过程中,如果准确率不符合预期,返回”数据标注”环节进行微调物体框选和参数

图6,一键部署模型
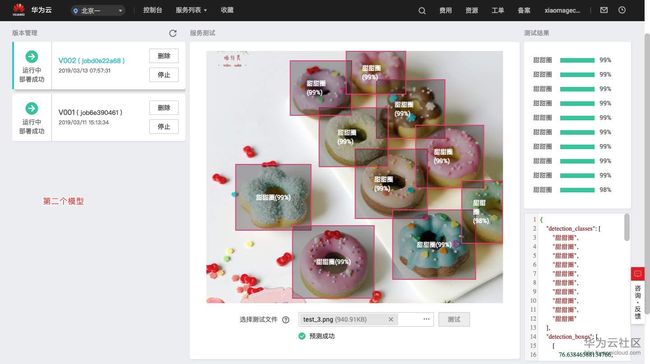
图7,对部署好的模型进行测试,查看识别效果

图8,有多少人工就有多少智能:标注环节标注的种类详细,预测也会相对准确
第二个场景,模拟海燕系统检测车型。使用的功能是ModelArts的图片分类功能,目的为了测试功能的易用性,我只设置了两个分类,识别SUV和普通轿车。流程和场景一几乎一样,上传训练数据到OBS,只是数据标注环节换做了给机器指定数据分类,比标注更简单。记得在2017年人工智能大会一个分论坛上,看到某公司已经能根据摄像头拍摄的图片分析出汽车品牌车型,以及车子年代,我准备慢慢探索使用ModelArts进一步挖掘图片识别方向的功能。
如下配图说明和场景一不同的地方:

图9,这里的数据标注环节相对简单,仅仅是选择图片并为其打上标签
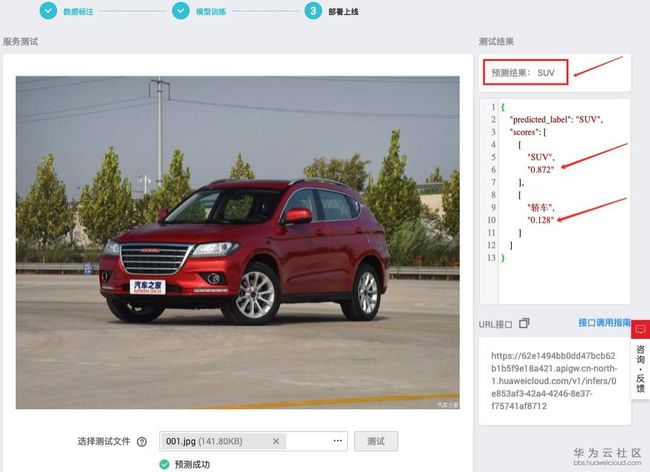
图10,测试识别效果

图11,测试识别效果
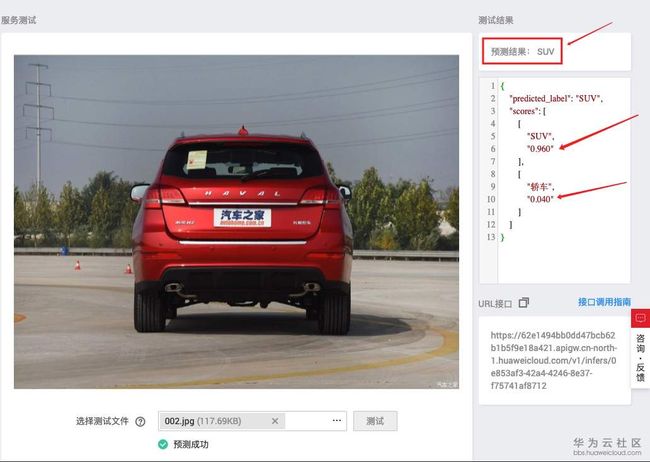
图12,测试识别效果
总体来说,通过两个场景试验,ModelArts降低了我们做机器学习模型的台阶,让整个模型训练对于我们操作者变得透明,简单,高效。即使算法积累不够的项目组,通过这个平台也可以先拿出一个堪用的模型,用于支撑上线进一步迭代。
尽管操作过程很简单,并不意味着ModelArts仅仅可以做这么多,作为用户,我们有很多的选择权,首先就是数据集,如果用户自己没有充足的数据,可以去华为云的市场上购买数据;其次,训练模型环节,ModelArts预制了算法,给熟悉算法的用户自定义的空间;并且,华为云要做的是一个生态,未来要开发者可以分享自己的算法模型到市场,有需求的用户直接购买其他分享者的算法继续自己产品开发。所以华为云给用户充分简单的工具,要打造的却一个不简单的生态系统。
期待ModelArts会更好
作为一个具有专业态度的体验官,不仅要写出最真实的用户体验,更应该及时发现问题并反映问题。
例如在标注环节中,图像标注框定物体,在用户已经标注了一部分的前提下,可以对后续大量的图片进行一个预标注,这样标注员只对其进行简单的微调,可以大大提高标注效率。
当然,或许问题微不足道,但是希望华为云ModelArts可以更加注重细节的升级,帮助开发者更好地学习机器学习,同时也欢迎更多人一起体验华为云ModelArts。
购买华为云请点击立即购买