一文掌握SQLite3基本用法
目录
一、基本语法
1. 常用指令
2. 数据类型
3. 创建数据库
4. 导入/导出数据库
5. 创建表
6. 查看表的详细信息
7.删除表
8. 插入数据
9. 格式化输出
10. 输出表
11. 运算符
12. where子句
13. 删除记录表中的数据
14. update语句
二、C/C++操作
1. 接口API
2. 连接数据库
3. 创建表
4. 插入数据
5. 查表操作
6. 数据删除操作
三:结语
一、基本语法
1.常用指令
.open filename --打开文件
-- 注解
.show --显示SQLite 命令提示符的默认设置
.q --退出
.databases --显示数据库(注:显示打开的数据库)
.help --帮助
.dump --导入导出数据库
.tables --查看表2.数据类型
| 存储类型 | 描述 |
| NULL | 空值 |
| int | 整形 |
| text | 一个文本字符串 |
| blob | 一个blob数据 |
| integer | 一个带符号的整数,根据值的大小存储在1、2 、3、4、6或8字节中 |
| real | 值是一个浮点值,存储为8字节的浮点数 |
| ...... | ...... |
3.创建数据库
.open test.db --没有就创建
sqlite3 DatabaseName.db
上面的命令将在当前目录下创建一个文件 testDB.db。该文件将被 SQLite 引擎用作数据库。如果您已经注意到 sqlite3 命令在成功创建数据库文件之后,将提供一个 sqlite> 提示符。
.databases 命令用于检查它是否在数据库列表中。
.open 操作

4. 导入/导出数据库
sqlite3 test.db .dump > filename --导出
sqlite3 test.db < filename --导入上面的转换流整个 testDB.db 数据库的内容到 SQLite 的语句中,并将其转储到 ASCII 文本文件 testDB.sql 中。您可以通过简单的方式从生成的 testDB.sql 恢复,如下所示 我删掉testDB.db后:
![]()
5.创建表
--注意,在打开数据库时才能操作
CREATE TABLE database_name.table_name(
column1 datatype PRIMARY KEY(one or more columns),
column2 datatype,
column3 datatype,
.....
columnN datatype,
);CREATE TABLE 是告诉数据库系统创建一个新表的关键字。CREATE TABLE 语句后跟着表的唯一的名称或标识。您也可以选择指定带有 table_name 的 database_name。
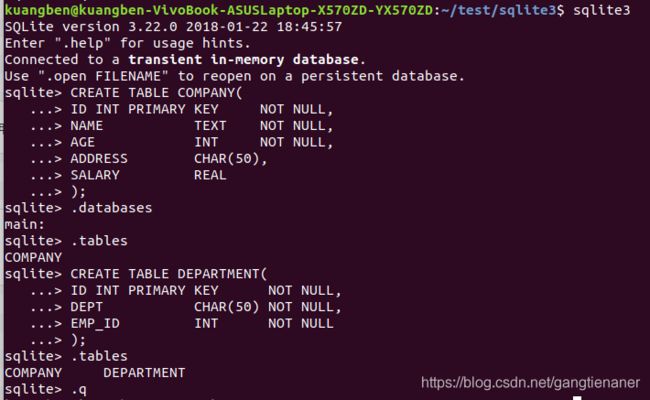
如上图所示,我们创建了COMPANY DEPARTMENT两个表。其中ID 作为主键,NOT NULL 的约束表示在表中创建纪录时这些字段不能为 NULL。
6.查看表的详细信息
.schema --注意:打开数据库时才能操作
7.删除表
DROP TABLE database_name.table_name; 如上,删除了名为DEPARTMENT的表
如上,删除了名为DEPARTMENT的表
8.插入数据
INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)]
VALUES (value1, value2, value3,...valueN);
在这里,column1, column2,...columnN 是要插入数据的表中的列的名称。
如果要为表中的所有列添加值,您也可以不需要在 SQLite 查询中指定列名称。但要确保值的顺序与列在表中的顺序一致。SQLite 的 INSERT INTO 语法如下:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);现在,我已经创建了COMPANY表,如下
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);现在,下面的语句将在 COMPANY 表中创建六个记录:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Kim', 22, 'South-Hall', 45000.00 );输出结果如下:
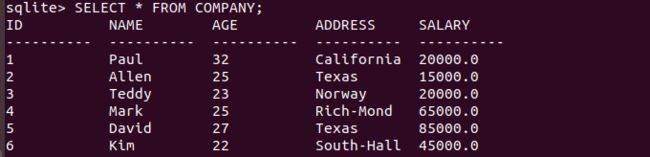
我们也可以使用第二种语法在COMPANY 表中创建一个记录,如下所示:
INSERT INTO COMPANY VALUES (7, 'James', 24, 'Houston', 10000.00 );输出结果如下:
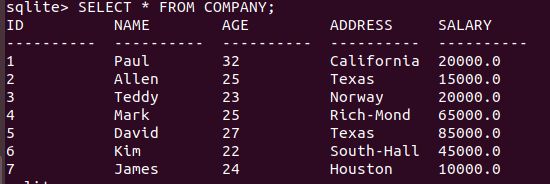
9.格式化输出
.header on
.mode column
.timer on --开启CPU定时器
SELECT * FROM table_name; --显示表table_name
非格式化输出
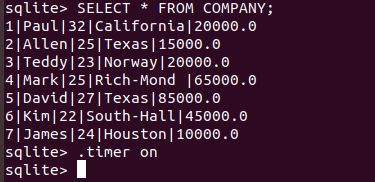
格式化输出
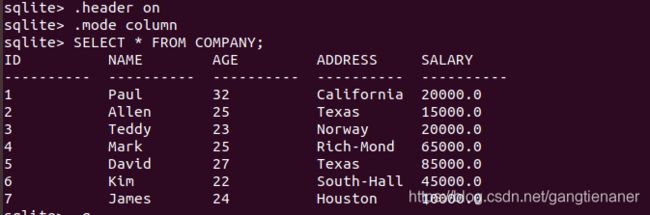
10.输出表
完整输出
.header on
.mode column
SELECT * FROM COMPANY;
输出指定列
.header on
.mode column
SELECT ID, NAME, SALARY FROM COMPANY; --只输出ID, NAME和SALARY三列

设置输出列的宽度
.width num1,num1,num3....
SELECT * FROM COMPANY;下面 .width 命令设置第一列的宽度为 10,第二列的宽度为 20,第三列的宽度为 10。输出结果如下:
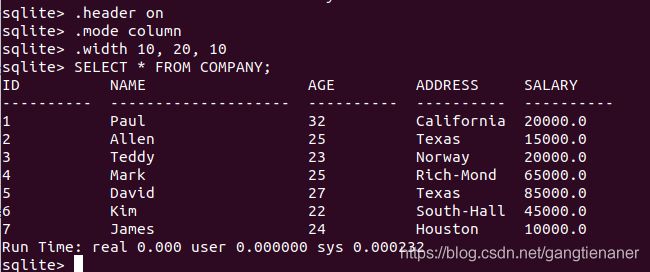
11.运算符
sqlite运算符主要用于 SQLite 语句的 WHERE 子句中执行操作,如比较和算术运算。
运算符用于指定 SQLite 语句中的条件,并在语句中连接多个条件。
算术运算符:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加法 - 把运算符两边的值相加 | a + b 将得到 30 |
| - | 减法 - 左操作数减去右操作数 | a - b 将得到 -10 |
| * | 乘法 - 把运算符两边的值相乘 | a * b 将得到 200 |
| / | 除法 - 左操作数除以右操作数 | b / a 将得到 2 |
| % | 取模 - 左操作数除以右操作数后得到的余数 | b % a will give 0 |
比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a == b) 不为真。 |
| = | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a = b) 不为真。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a != b) 为真。 |
| <> | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a <> b) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (a > b) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (a < b) 为真。 |
| >= | 检查左操作数的值是否大于等于右操作数的值,如果是则条件为真。 | (a >= b) 不为真。 |
| <= | 检查左操作数的值是否小于等于右操作数的值,如果是则条件为真。 | (a <= b) 为真。 |
| !< | 检查左操作数的值是否不小于右操作数的值,如果是则条件为真。 | (a !< b) 为假。 |
| !> | 检查左操作数的值是否不大于右操作数的值,如果是则条件为真。 | (a !> b) 为真。 |
逻辑运算符
| 运算符 | 描述 |
|---|---|
| AND | AND 运算符允许在一个 SQL 语句的 WHERE 子句中的多个条件的存在。 |
| BETWEEN | BETWEEN 运算符用于在给定最小值和最大值范围内的一系列值中搜索值。 |
| EXISTS | EXISTS 运算符用于在满足一定条件的指定表中搜索行的存在。 |
| IN | IN 运算符用于把某个值与一系列指定列表的值进行比较。 |
| NOT IN | IN 运算符的对立面,用于把某个值与不在一系列指定列表的值进行比较。 |
| LIKE | LIKE 运算符用于把某个值与使用通配符运算符的相似值进行比较。 |
| GLOB | GLOB 运算符用于把某个值与使用通配符运算符的相似值进行比较。GLOB 与 LIKE 不同之处在于,它是大小写敏感的。 |
| NOT | NOT 运算符是所用的逻辑运算符的对立面。比如 NOT EXISTS、NOT BETWEEN、NOT IN,等等。它是否定运算符。 |
| OR | OR 运算符用于结合一个 SQL 语句的 WHERE 子句中的多个条件。 |
| IS NULL | NULL 运算符用于把某个值与 NULL 值进行比较。 |
| IS | IS 运算符与 = 相似。 |
| IS NOT | IS NOT 运算符与 != 相似。 |
| || | 连接两个不同的字符串,得到一个新的字符串。 |
| UNIQUE | UNIQUE 运算符搜索指定表中的每一行,确保唯一性(无重复)。 |
位运算符
| p | q | p & q | p | q |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
下面直接上例子
我有COMPANY 表如下:
ID NAME AGE ADDRESS SALARY
---------- ---------- ---------- ---------- ----------
1 Paul 32 California 20000.0
2 Allen 25 Texas 15000.0
3 Teddy 23 Norway 20000.0
4 Mark 25 Rich-Mond 65000.0
5 David 27 Texas 85000.0
6 Kim 22 South-Hall 45000.0
7 James 24 Houston 10000.0用 SELECT列出SALARY 大于 50,000.00 的所有记录:
SELECT * FROM COMPANY WHERE SALARY > 50000;输出结果如下:

用 SELECT列出SALARY 等于的所有记录:
SELECT * FROM COMPANY WHERE SALARY = 20000;输出结果如下:

用 SELECT列出AGE 大于等于 25 且SALARY大于等于 65000.00的所有记录:
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;输出结果如下:

12.where子句
SQLite的 WHERE 子句用于指定从一个表或多个表中获取数据的条件。如果满足给定的条件,即为真(true)时,则从表中返回特定的值。您可以使用 WHERE 子句来过滤记录,只获取需要的记录。WHERE 子句不仅可用在 SELECT 语句中,它也可用在 UPDATE、DELETE 语句中,等等。用例参考运算符。
13.删除记录表中的数据
SQLite中,删除记录表数据为DELETE语句,我们可以使用带有 WHERE 子句的 DELETE。
语法如下:
DELETE FROM table_name WHERE [condition];我们有以下记录表:
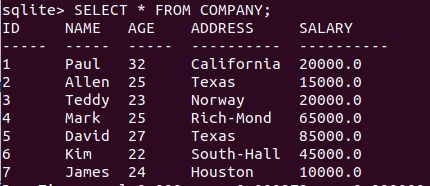
删除ID为7的列:
DELETE FROM COMPANY WHERE ID = 7;再次输出结果:
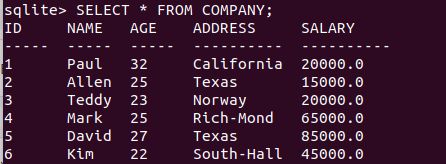
14.update语句
SQLite 的 UPDATE 查询用于修改表中已有的记录。可以使用带有 WHERE 子句的 UPDATE 查询来更新选定行,否则所有的行都会被更新。
语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];注:这三行实为同一行。
现在我有数据表如下:

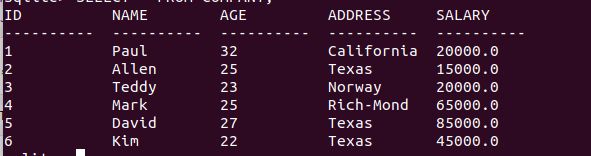
把COMPANY表中ID 为 6 的客户地址改为Texas:
UPDATE COMPANY SET ADDRESS = 'Texas' WHERE ID = 6;修改结果:
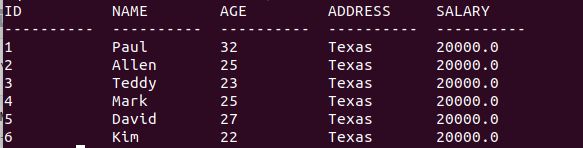
如果您想修改 COMPANY 表中 ADDRESS 和 SALARY 列的所有值,则不需要使用 WHERE 子句,UPDATE 查询如下:
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00;修改结果:
二、C/C++操作
1.接口API
下面接口能满足我们的基本需求,需要学习更多的操作,我们可以参考官方文档。
| 序号 | API & 描述 |
|---|---|
| 1 | sqlite3_open(const char *filename, sqlite3 **ppDb) 该例程打开一个指向 SQLite 数据库文件的连接,返回一个用于其他 SQLite 程序的数据库连接对象。 如果 filename 参数是 NULL 或 ':memory:',那么 sqlite3_open() 将会在 RAM 中创建一个内存数据库,这只会在 session 的有效时间内持续。 如果文件名 filename 不为 NULL,那么 sqlite3_open() 将使用这个参数值尝试打开数据库文件。如果该名称的文件不存在,sqlite3_open() 将创建一个新的命名为该名称的数据库文件并打开。 |
| 2 | sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char **errmsg) 该例程提供了一个执行 SQL 命令的快捷方式,SQL 命令由 sql 参数提供,可以由多个 SQL 命令组成。 在这里,第一个参数 sqlite3 是打开的数据库对象,sqlite_callback 是一个回调,data 作为其第一个参数,errmsg 将被返回用来获取程序生成的任何错误。 sqlite3_exec() 程序解析并执行由 sql 参数所给的每个命令,直到字符串结束或者遇到错误为止。 |
| 3 | sqlite3_close(sqlite3*) 该例程关闭之前调用 sqlite3_open() 打开的数据库连接。所有与连接相关的语句都应在连接关闭之前完成。 如果还有查询没有完成,sqlite3_close() 将返回 SQLITE_BUSY 禁止关闭的错误消息。 |
2.连接数据库
下面的 C 代码段显示了如何连接到一个现有的数据库。如果数据库不存在,那么它就会被创建,最后将返回一个数据库对象。
#include
#include
int main(int argc, char* argv[])
{
sqlite3 *db;
char *zErrMsg = 0;
int rc;
rc = sqlite3_open("test.db", &db);
if( rc ){
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}else{
fprintf(stderr, "Opened database successfully\n");
}
sqlite3_close(db);
} 编译命令
gcc lianjie.c -l sqlite3运行结果
![]()
终端输入ls -l命令发现多了个test.db文件,如图:
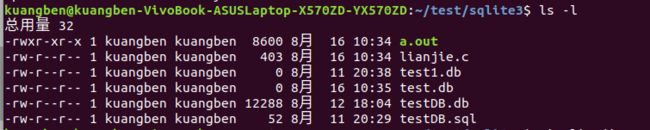
3.创建表
C语言创建表与终端创建操作差不多,只不过命令由sqlite3_exec()函数的sql参数传入。格式如下:
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
示例代码:
#include
#include
#include
static int callback(void *NotUsed, int argc, char **argv, char **azColName){
int i;
for(i=0; i 输出结果:

再次ls -l:
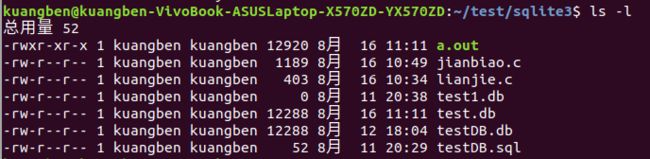
我们可以看到,test.db文件大小明显变大了。
4.插入数据
与创建表类似,sql参数设为:
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";示例代码:
#include
#include
#include
static int callback(void *NotUsed, int argc, char **argv, char **azColName){
int i;
for(i=0; i 输出结果:
![]()
5.查表操作
sqlite3_exec()给我们提供了一个回调函数,其声明如下:
typedef int (*sqlite3_callback)(
void*, /* Data provided in the 4th argument of sqlite3_exec() */
int, /* The number of columns in row */
char**, /* An array of strings representing fields in the row */
char** /* An array of strings representing column names */
);第一个参数:即第四个参数传入的数据
第二个参数:行中的列数
第三个参数:表示行中字段的字符串数组,即各行中的数据
第四个参数:表示列名的字符串数组,创建链表时设置的
执行流程:查表,是否还有符合条件数据。有,执行sqlite3_callback()函数;没有,退出
用法讲完了,下面看例子:
#include
#include
#include
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i 上面程序显示了如何从前面创建的 COMPANY 表中获取并显示记录,输出结果如下:
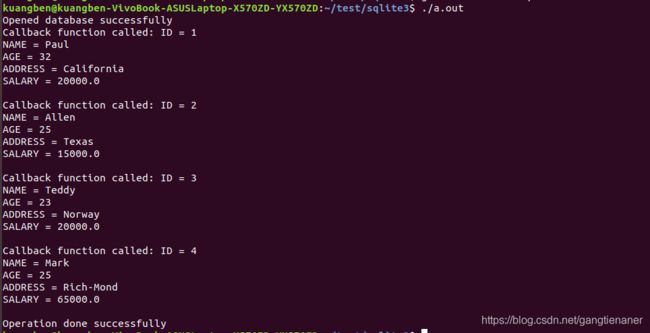
这里我没有特殊指明查询条件,表示查询全部。
6.数据删除操作
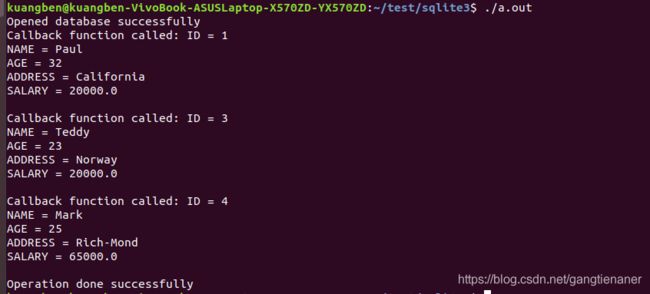
sql参数设置:
sql = "DELETE from COMPANY where ID=2; " \\删除ID等于2的行
"SELECT * from COMPANY"; \\显示表这里跟上面不同的是多了一个命令,表面sql参数可由多个命令组成。
示例代码:
#include
#include
#include
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i 输出:
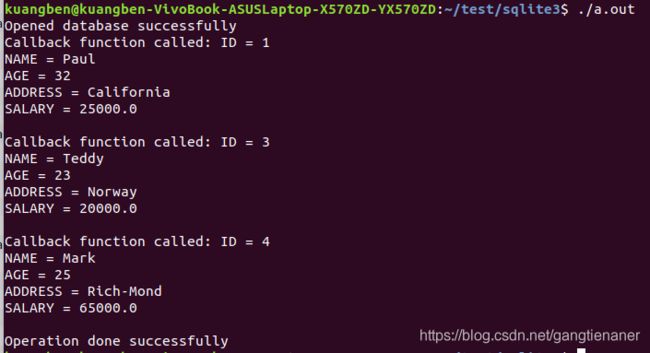
7.UPDATE 操作
操作示例:
#include
#include
#include
static int callback(void *data, int argc, char **argv, char **azColName){
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i 输出结果:
三:结语
现在,关于sqlite3的基本用法都讲完了,有不对的地方欢迎指出。