维度建模详解
文章目录
- 1 维度设计
-
- 1.1 代理键(太复杂,不推荐)
- 1.2 稳定维度
- 1.3 缓慢渐变维 => 拉链表
- 1.4 维度表的拆分、合并
- 2 事实表设计
-
- 2.1 明细事实表(dwd)
-
- 2.1.2 案例:
- 2.1.3 存储方案
- 2.1.4 事实拉链表示例:
- 2.2 聚合事实表(dws)
-
- 2.2.1 分类
- 2.2.2 案例
- 3 数据集市
- 4 业务数据案例
-
- 4.1 数据采集
- 4.2 数仓设计
- 5 流量数据相关场景
-
- 5.1 区分流量来源
- 5.2 页面访问轨迹
- 5.3 跳出率 断点处
- 5.4 设备信息用途
- 6 数据应用
星座模型只是星型模型的维度公用,类似这种

实际开发中,针对某一主题可以有明确的星型模型,星座模型啥的。但是众多主题间也存在维度公用的情况,这样交织在一起形成一张大网,很难说是啥模型吧。
1 维度设计
1.1 代理键(太复杂,不推荐)
维度表主键,关联事实表

解决办法:自创一个自增的id,取代source+id这种判断方法
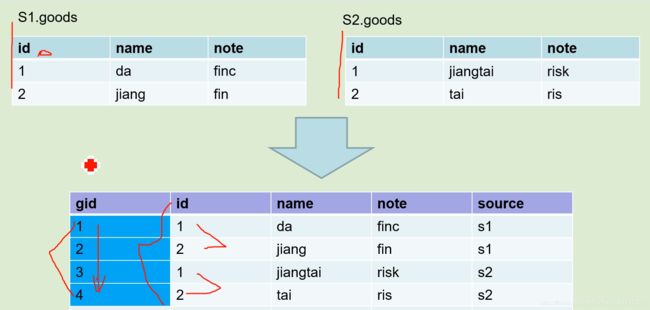
所以有了代理键这个东西:

实现方法:前一天gid的max+新增数据的行号,就是增量的gid了。

1.2 稳定维度

1.3 缓慢渐变维 => 拉链表

这样这个id就不唯一了,跟事实表关联的话就要再弄一个代理键才行

这样按部门统计有两个,按客户统计有一个就解决问题了,没有代理键的话,就乱了。
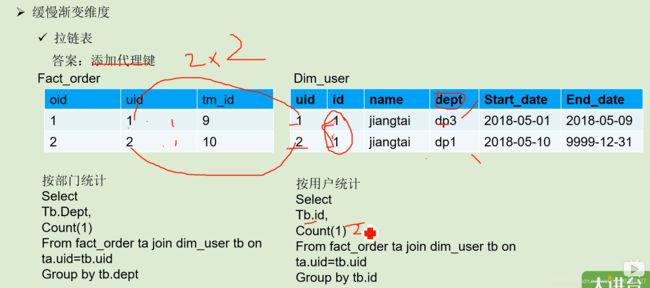
mysql的业务数据=>事实表的时候,就要把代理键给弄进去

具体操作方法:
不管全量增量,先把今天发生的事情选出来,再去关联。
第一种是给普通数据库用的,hive不能用非等值连接,就只能先join再where了

但是这样很麻烦,一般用的不多,有时候可以用全量快照。

1.4 维度表的拆分、合并
横向拆分:销售员工、技术员工等
纵向拆分:不同员工关注不同的字段

弄一张大宽表,没有对应的属性字段就空着,谁要啥信息就从里面弄一张子表用,
没啥特殊情况就用这个就行,空间换时间。

也可以弄一个基础信息表,不同的表在这个基础上加上自己想要的相关属性字段
2 事实表设计
2.1 明细事实表(dwd)

降维就是把外面关联的维度信息弄进事实表,统计的时候减少关联操作用的
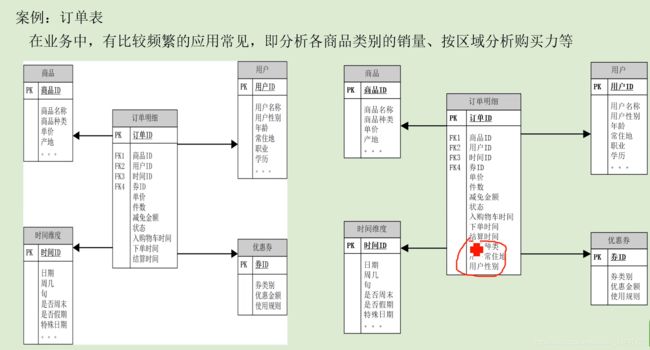
有时候事实表里面没有度量,比如这个审核表

多个动作的事实表啥设计?
多事实表
单事实表,不断更新

2.1.2 案例:

方案一:每个动作都做表。分析起来很灵活,但是业务侧自己可能也不会做的这么细,有需求只能采集他们的日志啥的。

第二种就是一个订单完整流程一张表整合到一张宽表上

总结:第二种常用,好维护,第一种在某些特殊分析场景下可以搞定,而第二种不行。

2.1.3 存储方案
没状态变化的就增量存储
有变化的可以每天快照,如果嫌站空间可以只保存近一年的数据,再之前的保存每月底分区就行了。
如果变化的数据占比小,可以考虑拉链表,变化多了还是快照比较好。

2.1.4 事实拉链表示例:

旧数据结束日期改掉,新数据插进去


如果是快照表,要做拉链的话:用MD5判断是否新增变化数据

2.2 聚合事实表(dws)
2.2.1 分类
按照是否可累加:
不可累加事实(xx率,去重客户数)就拆开存,比如xx率就分子分母一起存

按照统计周期:


2.2.2 案例
2.1 案例的dws设计:
通用汇总层:
按照不同粒度的每日汇总,以及历史汇总
对于历史汇总数据,不用每天都去算全量数据,可以只计算当天新增数据,再与前一天的历史汇总数据关联,就能出来整个的历史汇总了。
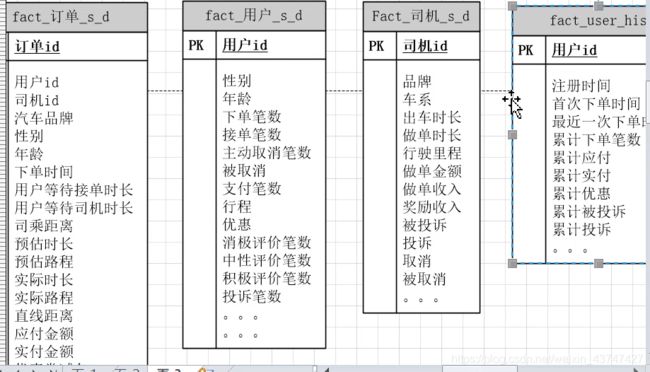
周期汇总层:
日粒度的交易日报,以及周粒度的用户汇总
这个周粒度的汇总有些结果可以直接从每日汇总用户表累加得到,尽量减少计算工作量。

3 数据集市
基于大数据的架构下的数仓,集市概念很弱,相当于一个应用层,梳理基于各个主题的汇总数据。
不像传统行业,比如银行,集市就是从各个源系统拉明细数据,自己用啥就加工啥,有点像自己在做一个小数仓一样。
4 业务数据案例

1 梳理业务流程
2 梳理数据流转
认证项里面有好多:身份证号、借记卡、授权通讯公司密码可以调取通话记录 等等

题外话:还有可能是芝麻信用,其他收费三方接口
有的像这种并行的效率就高一些,可能几秒就有额度;想节约成本可能判定黑名单了,就不会去花钱调接口继续查了,串行的多的可能要几个小时才有额度。

3 数据类型、存储介质、最好有样例数据
4 需求:功能性的、非功能性的需求(性能、时效性)
4.1 数据采集
线上数据 (ER模型)

关注下表的数据量、每日增量、是否有唯一自增主键、createtime和updatetime这些。
sqoop导入的时候会指定 --split-by xx字段
如果主键id不均匀,就数据倾斜了,这时候可以考虑用updatetime来split
采集方案:
根据数据量、是否状态变化

全量采集 user_info

增量采集订单表,先把变化的数据弄进临时库stage,避免数据倾斜用updated_time切分map

4.2 数仓设计
先把公用的维度表定了
然后做事实表,根据可能的分析角度来进行信息整合,维度退化,虽然有些事实表信息冗余,但是分析简单。
像额度管理表就可以做成拉链表
dwd:
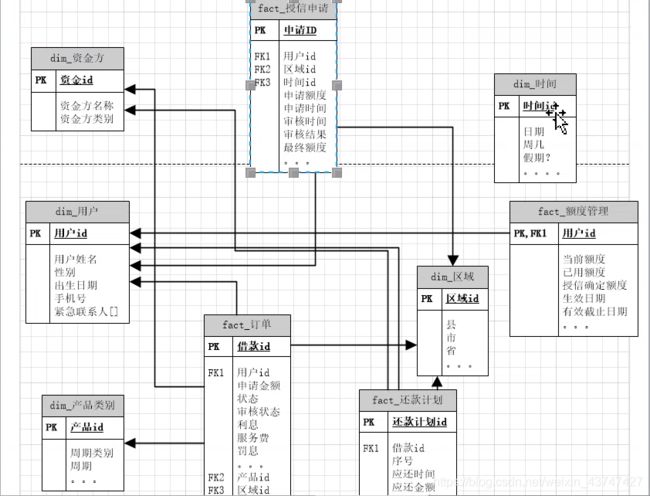

dws:
如果dws表太宽了不方便,可以根据业务、常用与否、计算范围来拆个辅助模型出来。
比如这张订单表,尽可能覆盖全面,把还款情况聚合过来


5 流量数据相关场景
5.1 区分流量来源
内部标签有他自己的标签id,外面进来的就看url参数

5.2 页面访问轨迹
区分会话方法:
=>只有uid和时间戳的就用超时时间来判断
=>有reffer可以用reffer为空来判断,也可以加上超时时间条件
=>有sessionid reffer 那就好弄了

5.3 跳出率 断点处
跳出前最后一次的页面

5.4 设备信息用途

6 数据应用
BI(报表),运营效果评估 算是最快最容易变现的数据应用了
但是AB客群的划分,也可以通过标签系统来搞定,这也算个应用吧。
整体的,标签系统->划分客群->点击转化分析 这个大系统。比如之前见到的golfer平台。这个对营销、运营帮助还挺大的。
