java-爬虫2
WebMagic-爬虫框架
1. WebMagic
1.1 WebMagic介绍
WebMagic是一个基于HttpClient和Jsoup的简单灵活的Java爬虫框架。具有简单的API,可快速上手;模块化的结构,可轻松扩展;提供多线程和分布式支持的特性。
WebMagic由四个组件(Downloader、PageProcessor、Scheduler、Pipeline)构成,核心代码非常简单,主要是将这些组件结合并完成多线程的任务。
1.2 总体架构
WebMagic总体架构图如下:

WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。
- Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
- PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
- Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
- Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
1.3 用于数据流转的对象
Request,Page,ResultItems为三个用于数据流转的对象。
- Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
- Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
- ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。
通俗的来讲就是:Request就是请求的地址(爬取的地址),Page为返回的数据,ResultItems为解析Page所得到的结果。
2. 环境搭建
2.1 导入依赖
pom.xml
<dependencies>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.4version>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.4version>
dependency>
dependencies>
2.2 配置文件
log4j.properties
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.3 测试环境
爬取西安石油大学相关页面地址信息如下图所示:

测试代码:
package com.xmx.webmagic.test;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @Author Xumx
* @Date 2021/3/18 22:05
* @Version 1.0
*/
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
//解析返回的数据page,并且把解析的结果放到ResultItems中
page.putField("div",page.getHtml().css("#line_u12_0 a").all());
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
//主函数,执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor())
.addUrl("http://www.xsyu.edu.cn/xwzx/jcdt.htm") //设置爬取数据的页面
.run();
}
}
输出如下:

3. 编写基本的爬虫
3.1 页面元素的抽取
WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。另外,对于JSON格式的内容,可使用JsonPath进行解析。
- XPath,是用于XML中获取元素的一种查询语言,但是用于Html也是比较方便的。例如:
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()")
它的意思是“查找所有class属性为’entry-title public’的h1元素,并找到他的strong子节点的a子节点,并提取a节点的文本信息”。
- CSS选择器,是与XPath类似的语言,$(‘h1.entry-title’)这种写法。它比XPath写起来要简单一些,但是如果写复杂一点的抽取规则,就相对要麻烦一点。
- 正则表达式,则是一种通用的文本抽取语言。
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
它表示匹配所有"https://github.com/code4craft/webmagic"这样的链接。
- JsonPath,JsonPath是于XPath很类似的一个语言,它用于从Json中快速定位一条内容。
3.2 抽取部分API
Selectable相关的抽取元素链式API是WebMagic的一个核心功能。使用Selectable接口,可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。

3.3 获取结果的API
当链式调用结束时,拿到一个字符串类型的结果。这时候就需要用到获取结果的API。无论是XPath、CSS选择器或者正则表达式,总有可能抽取到多条元素。WebMagic对这些进行了统一,可以通过不同的API获取到一个或者多个元素。
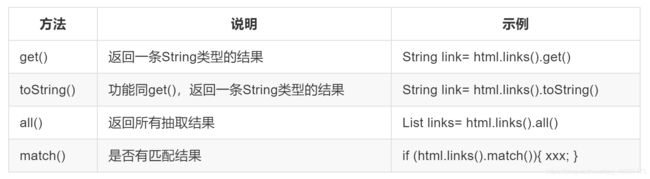
演示代码:
//css选择器
page.putField("div",page.getHtml().css("#line_u12_0 a").all());
//XPath
page.putField("div2",page.getHtml().xpath("//li[@id=line_u12_0]/a"));
//正则表达式
page.putField("div3",page.getHtml().css("ul.pieces-news li").regex(".*计算机学院.*").all());
//处理结果API
page.putField("div4",page.getHtml().css("ul.pieces-news li").regex(".*计算机学院.*").get());
page.putField("div5",page.getHtml().css("ul.pieces-news li").regex(".*计算机学院.*").toString());
演示结果:
D:\soft\Java\jdk-9.0.4\bin\java.exe "-javaagent:D:\soft\JetBrains\IntelliJ IDEA 2020.3.2\lib\idea_rt.jar=54331:D:\soft\JetBrains\IntelliJ IDEA 2020.3.2\bin" -Dfile.encoding=UTF-8 -classpath D:\code\java\code\heima\crawler\crawler_webmagic\target\classes;D:\code\java\maven_repository\us\codecraft\webmagic-core\0.7.4\webmagic-core-0.7.4.jar;D:\code\java\maven_repository\org\apache\httpcomponents\httpclient\4.5.13\httpclient-4.5.13.jar;D:\code\java\maven_repository\org\apache\httpcomponents\httpcore\4.4.13\httpcore-4.4.13.jar;D:\code\java\maven_repository\commons-logging\commons-logging\1.2\commons-logging-1.2.jar;D:\code\java\maven_repository\commons-codec\commons-codec\1.11\commons-codec-1.11.jar;D:\code\java\maven_repository\org\apache\commons\commons-lang3\3.10\commons-lang3-3.10.jar;D:\code\java\maven_repository\us\codecraft\xsoup\0.3.1\xsoup-0.3.1.jar;D:\code\java\maven_repository\org\assertj\assertj-core\1.5.0\assertj-core-1.5.0.jar;D:\code\java\maven_repository\org\slf4j\slf4j-api\1.7.30\slf4j-api-1.7.30.jar;D:\code\java\maven_repository\commons-collections\commons-collections\3.2.2\commons-collections-3.2.2.jar;D:\code\java\maven_repository\org\jsoup\jsoup\1.10.3\jsoup-1.10.3.jar;D:\code\java\maven_repository\commons-io\commons-io\2.7\commons-io-2.7.jar;D:\code\java\maven_repository\com\jayway\jsonpath\json-path\2.4.0\json-path-2.4.0.jar;D:\code\java\maven_repository\net\minidev\json-smart\2.3\json-smart-2.3.jar;D:\code\java\maven_repository\net\minidev\accessors-smart\1.2\accessors-smart-1.2.jar;D:\code\java\maven_repository\org\ow2\asm\asm\5.0.4\asm-5.0.4.jar;D:\code\java\maven_repository\com\alibaba\fastjson\1.2.69\fastjson-1.2.69.jar;D:\code\java\maven_repository\us\codecraft\webmagic-extension\0.7.4\webmagic-extension-0.7.4.jar;D:\code\java\maven_repository\redis\clients\jedis\2.9.3\jedis-2.9.3.jar;D:\code\java\maven_repository\org\apache\commons\commons-pool2\2.4.3\commons-pool2-2.4.3.jar com.xmx.webmagic.test.JobProcessor
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
get page: http://www.xsyu.edu.cn/xwzx/jcdt.htm
div: [<a href="../info/1073/23065.htm" target="_blank" title="计算机学院召开2021届毕业生考研复试、调剂交流会">计算机学院召开2021届毕业生考研复试、调剂交流会</a>]
div2: <a href="../info/1073/23065.htm" target="_blank" title="计算机学院召开2021届毕业生考研复试、调剂交流会">计算机学院召开2021届毕业生考研复试、调剂交流会</a>
div3: [<li id="line_u12_0"><span>2021-03-18</span><a href="../info/1073/23065.htm" target="_blank" title="计算机学院召开2021届毕业生考研复试、调剂交流会">计算机学院召开2021届毕业生考研复试、调剂交流会</a></li>, <li id="line_u12_6"><span>2021-03-17</span><a href="../info/1073/23056.htm" target="_blank" title="计算机学院举办2019级本科生班级建设交流会">计算机学院举办2019级本科生班级建设交流会</a></li>]
div4: <li id="line_u12_0"><span>2021-03-18</span><a href="../info/1073/23065.htm" target="_blank" title="计算机学院召开2021届毕业生考研复试、调剂交流会">计算机学院召开2021届毕业生考研复试、调剂交流会</a></li>
div5: <li id="line_u12_0"><span>2021-03-18</span><a href="../info/1073/23065.htm" target="_blank" title="计算机学院召开2021届毕业生考研复试、调剂交流会">计算机学院召开2021届毕业生考研复试、调剂交流会</a></li>
Process finished with exit code 0
上述演示代码已上传至码云:crawler_webmagic
3.4 获取链接
一个站点的页面是很多的,一开始我们不可能全部列举出来,于是如何发现后续的链接,是一个爬虫不可缺少的一部分。
page.addTargetRequests()则将这些链接加入到待抓取的队列中去,page.getHtml().links().regex("(https://github\.com/\w+/\w+)").all()用于获取所有满足"(https:/ /github.com/\w+/\w+)"这个正则表达式的链接。
//获取链接
page.addTargetRequests(page.getHtml().css("#line_u12_0").links().all());
page.putField("url",page.getHtml().css("h1.news_title").all());
3.5 使用Pipeline保存结果
WebMagic用于保存结果的组件叫做Pipeline。“控制台输出结果”也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。
//主函数,执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor())
.addUrl("http://www.xsyu.edu.cn/xwzx/jcdt.htm") //设置爬取数据的页面
.addPipeline(new FilePipeline("D:\\code\\java\\code\\heima\\crawler\\crawler_webmagic\\src\\main\\resources\\result"))
.thread(5) //设置有5个线程处理
.run(); //执行爬虫
}
3.6 爬虫的配置、启动和终止
Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。

对站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置。

private Site site = Site.me()
.setCharset("utf8") //设置编码
.setTimeOut(10000) //设置超时时间,单位是ms毫秒
.setRetrySleepTime(3000) //设置重试间隔时间,
.setSleepTime(3) //设置重试次数
;
4. 组件使用与定制
4.1 使用和定制Pipeline
Pileline是抽取结束后,进行处理的部分,它主要用于抽取结果的保存,也可以定制Pileline可以实现一些通用的功能。WebMagic中已经提供了将结果输出到控制台、保存到文件和JSON格式保存的几个Pipeline:

4.2 使用和定制Scheduler
Scheduler是WebMagic中进行URL管理的组件。一般来说,Scheduler包括两个作用:
- 对待抓取的URL队列进行管理。
- 对已抓取的URL进行去重。
WebMagic内置了几个常用的Scheduler。如果你只是在本地执行规模比较小的爬虫,那么基本无需定制Scheduler,但是了解一下已经提供的几个Scheduler还是有意义的。

Scheduler的内部实现进行了重构,去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。

所有默认的Scheduler都使用HashSetDuplicateRemover来进行去重,(除开RedisScheduler是使用Redis的set进行去重)。如果你的URL较多,使用HashSetDuplicateRemover会比较占用内存,所以也可以尝试以下BloomFilterDuplicateRemover1,使用方式:
spider.setScheduler(new QueueScheduler()
.setDuplicateRemover(new BloomFilterDuplicateRemover(10000000)) //10000000是估计的页面数量
)
4.3 使用和定制Downloader
5. 案例
5.1 环境准备
- 导入依赖
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.2.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.3version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>16.0version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
dependency>
dependencies>
- 配置文件
application.properties
#DB Configuration:
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/crawler
spring.datasource.username=root
spring.datasource.password=root
#JPA Configuration:
spring.jpa.database=MySQL
spring.jpa.show-sql=true
log4j.properties
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
5.2 基础类
- com.xmx.job.pojo.JobInfo
package com.xmx.job.pojo;
/**
* @Author Xumx
* @Date 2021/3/19 13:20
* @Version 1.0
*/
@Entity
public class JobInfo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String companyName;
private String companyAddr;
private String companyInfo;
private String jobName;
private String jobAddr;
private String jobInfo;
private Integer salaryMin;
private Integer salaryMax;
private String url;
private String time;
@Override
public String toString() {
return "JobInfo{" +
"id=" + id +
", companyName='" + companyName + '\'' +
", companyAddr='" + companyAddr + '\'' +
", companyInfo='" + companyInfo + '\'' +
", jobName='" + jobName + '\'' +
", jobAddr='" + jobAddr + '\'' +
", jobInfo='" + jobInfo + '\'' +
", salaryMin=" + salaryMin +
", salaryMax=" + salaryMax +
", url='" + url + '\'' +
", time='" + time + '\'' +
'}';
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getCompanyAddr() {
return companyAddr;
}
public void setCompanyAddr(String companyAddr) {
this.companyAddr = companyAddr;
}
public String getCompanyInfo() {
return companyInfo;
}
public void setCompanyInfo(String companyInfo) {
this.companyInfo = companyInfo;
}
public String getJobName() {
return jobName;
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
public String getJobAddr() {
return jobAddr;
}
public void setJobAddr(String jobAddr) {
this.jobAddr = jobAddr;
}
public String getJobInfo() {
return jobInfo;
}
public void setJobInfo(String jobInfo) {
this.jobInfo = jobInfo;
}
public Integer getSalaryMin() {
return salaryMin;
}
public void setSalaryMin(Integer salaryMin) {
this.salaryMin = salaryMin;
}
public Integer getSalaryMax() {
return salaryMax;
}
public void setSalaryMax(Integer salaryMax) {
this.salaryMax = salaryMax;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
}
- com.xmx.job.dao.JobInfoDao
package com.xmx.job.dao;
/**
* @Author Xumx
* @Date 2021/3/19 13:25
* @Version 1.0
*/
public interface JobInfoDao extends JpaRepository<JobInfo,Long> {
}
- com.xmx.service.JobInfoService
package com.xmx.job.service;
/**
* @Author Xumx
* @Date 2021/3/19 13:27
* @Version 1.0
*/
public interface JobInfoService {
/*
* 保存工作信息
* */
public void save(JobInfo jobInfo);
/*
* 根据条件查询工作信息
* */
public List<JobInfo> findJobInfo(JobInfo jobInfo);
}
- com.xmx.service.impl.JobInfoServiceImpl
package com.xmx.job.service.impl;
/**
* @Author Xumx
* @Date 2021/3/19 13:30
* @Version 1.0
*/
@Service
public class JobInfoServiceImpl implements JobInfoService {
@Autowired
private JobInfoDao jobInfoDao;
@Override
@Transactional
public void save(JobInfo jobInfo) {
//根据url和发布时间查询数据
JobInfo param = new JobInfo();
param.setUrl(jobInfo.getUrl());
param.setTime(jobInfo.getTime());
//执行查询
List<JobInfo> list = this.findJobInfo(param);
//判断查询数据是否为空
if(list.size() == 0){
//如果查询数据为空,表示招聘信息数据不存在,或者已经更新了,需要新增或者更新数据库
this.jobInfoDao.saveAndFlush(jobInfo);
}
}
@Override
public List<JobInfo> findJobInfo(JobInfo jobInfo) {
//设置查询条件
Example example = Example.of(jobInfo);
//执行查询
List list = this.jobInfoDao.findAll(example);
return list;
}
}
5.3 编写引导类
package com.xmx.job;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
/**
* @Author Xumx
* @Date 2021/3/19 13:57
* @Version 1.0
*/
@SpringBootApplication
@EnableScheduling //开启定时任务
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
5.4 编写url解析功能
package com.xmx.job.task;
/**
* @Author Xumx
* @Date 2021/3/19 14:01
* @Version 1.0
*/
@Component
public class JobProcessor implements PageProcessor {
private String url = "http://www.xsyu.edu.cn/xwzx/ssfc.htm";
@Override
public void process(Page page) {
//解析页面,获取招聘信息详情的url地址
//Html html1 = page.getHtml();
List<Selectable> list = page.getHtml().css("div.whole-news ul.pieces-news li").nodes();
//判断获取到的集合是否为空
if (list.size()==0){
//如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
this.saveJobInfo(page);
}else {
//如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中
for (Selectable selectable : list) {
//获取url地址
String jobInfoUrl = selectable.links().toString();
//System.out.println(jobInfoUrl);
page.addTargetRequest(jobInfoUrl);
}
//获取下一页的url
String s = page.getHtml().css("div.joi a").nodes().get(0).links().toString();
//System.out.println(s);
//把url放到任务队列中
page.addTargetRequest(s);
}
String html = page.getHtml().toString();
System.out.println("爬取完成");
}
//解析页面,获取招聘详情信息,保存数据
private void saveJobInfo(Page page) {
//创建招聘详情对象
JobInfo jobInfo = new JobInfo();
//解析页面
Html html = page.getHtml();
//获取数据,封装到对象中
jobInfo.setCompanyName(html.css("div.rbox h1","text").toString());
jobInfo.setCompanyAddr(html.css("div.rbox div.time","text").toString());
jobInfo.setCompanyInfo(html.css("div.rbox div.time","text").toString());
jobInfo.setJobName(html.css("div.rbox div.time","text").toString());
jobInfo.setJobAddr(html.css("div.rbox div.time","text").toString());
jobInfo.setJobInfo(html.css("div.rbox div.time","text").toString());
jobInfo.setUrl(page.getUrl().toString());
jobInfo.setSalaryMin(1000);
jobInfo.setSalaryMax(5000);
jobInfo.setTime("123");
//把结果保存起来
page.putField("jobInfo",jobInfo);
}
private Site site = Site.me()
.setCharset("utf8") //设置编码
.setTimeOut(10*1000) //设置超时时间
.setRetrySleepTime(3000) //设置重试发间隔时间
.setRetryTimes(3); //设置重试的次数
@Override
public Site getSite() {
return site;
}
@Autowired
private SpringDataPipeline springDataPipeline;
//initialDelay当任务启动后,等待多久执行方法
//fixedDelay每隔多久执行方法
@Scheduled(initialDelay = 1000,fixedDelay = 100*1000)
public void process(){
Spider.create(new JobProcessor())
.addUrl(url)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(10)
.addPipeline(this.springDataPipeline)
.run();
}
}
5.5 使用定制Pipeline
package com.xmx.job.task;
/**
* @Author Xumx
* @Date 2021/3/19 18:15
* @Version 1.0
*/
@Component
public class SpringDataPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的招聘详情对象
JobInfo jobInfo = resultItems.get("jobInfo");
//判断数据是否不为空
if (jobInfo != null){
//如果不为空把数据保存到数据库中
this.jobInfoService.save(jobInfo);
}
}
}
案例结果:

上述案例代码已传至码云:crawler_job