浏览器渲染原理
浏览器渲染原理
- 浏览器渲染原理
-
- 1. 进程和线程
- 2. 浏览器中的5个进程
- 3. HTTP 请求流程
-
- 3.1 浏览器发送 HTTP 请求的流程
- 3.2 服务端处理 HTTP 请求的流程
- 3.3 为什么很多站点第二次打开会很快
- 4. 输入url地址到浏览器显示页面发生了什么
- 5. 浏览器渲染流程
-
- 5.1 构建 DOM 树
- 5.2 样式计算
-
- 5.2.1 把CSS转换为浏览器内容理解的结构
- 5.2.2 转换样式表中的属性值,使其标准化
- 5.2.3 计算出DOM树中每一个节点的具体样式
- 5.3 布局阶段
-
- 5.3.1 创建布局树
- 5.3.2 布局计算
- 5.4 分层 (图层树)
- 5.5 图层的绘制
- 5.6 栅格化操作
- 5.7 合成和显示
- 5.8 总结
- 6. 相关概念
-
- 6.1 更新元素的几何属性(重排)
- 6.2 更新元素的绘制属性(重绘)
- 6.3 直接合成阶段
- 7. 优化方案
浏览器渲染原理
1. 进程和线程
进程 : 进程是操作系统资源分配的基本单位,进程中包含线程。简而言之,就是正在进行中的应用程序。
线程:线程是由进程所管理的。是进程内的一个独立执行的单位,是CPU调度的最小单位。
- 线程是进程的基本单位,一个进程由一个或者多个线程组成,搞清楚这个关系之后,我们可以明确线程就是程序执行的最小单元。
- 线程和进程一样,也是动态概念,有创建有销毁,存在只是暂时的,不是永久性的。
- 进程与线程的区别在于进程在运行时拥有独立的内存空间,也就是说每个进程所占用的内存都是独立的。
- 例如:微信运行时,系统会给它一个运行内存。
- 多个线程是共享内存空间的,但是每个线程的执行是相互独立的,线程必须依赖于进程才能执行,单独的线程是无法执行的,由进程来控制多个线程的执行,没有进程就不存在线程。
- 例如:我先开启一个发送消息的线程,那么同时还能由一个接收消息的线程。两个线程之间完全独立。
为了提升浏览器的稳定性和安全性,浏览器采取了多进程模型。
2. 浏览器中的5个进程
目前最新的Chrome进程架构图
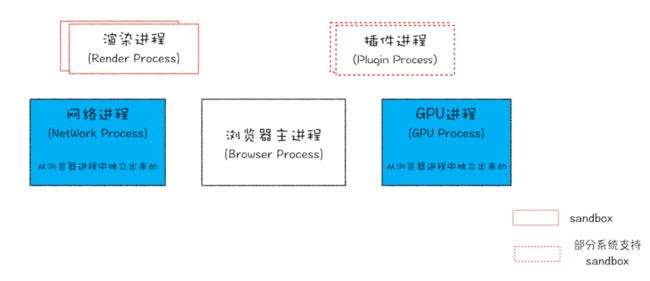
浏览器设置的时候是一个多进程模型,这样能确保浏览的安全性和稳定性。如果一个页面有问题,不影响其他页面的运行。
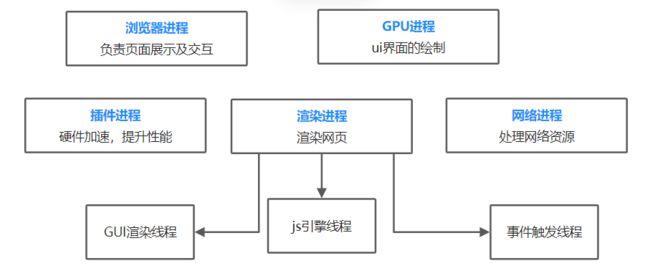
- 浏览器进程。主要负责界面显示、用户交互、子进程管理、同时提供存储等功能。
- 渲染进程。 核心任务是将
HTML、CSS和JavaScript转换为用户可以与之交互的网页,排版引擎Blink和JavaScript引擎V8都运行在该进程中,默认情况下,Chrome为每一个Tab标签页创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下的。 - **GPU进程。**GPU图形处理器(英语:graphics processing unit,缩写:GPU),负责3D CSS效果,网页,Chrome ui的绘制。
- 网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立处理,成为单独一个进程。
- 插件进程。主要负责插件的运行,因为插件易崩溃,所以通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。每一种类型的插件对应一个进程,仅当使用该插件时才创建。
所以我们开启一个页面,至少会启动4个进程。
3. HTTP 请求流程
HTTP是一种允许浏览器向服务器获取资源的协议,是Web的基础。通常由浏览器发起请求,用来获取不同类型的文件,例如HTML,CSS,JavaScript、图片、视频等。此外,HTTP也是浏览器使用最广的协议。规定了客户端请求,和服务器端响应数据格式的协议。
接下来简单介绍一下 浏览器发送HTTP 请求的大致流程:
3.1 浏览器发送 HTTP 请求的流程
- 构造请求
首先,浏览器构造请求行,构建好之后,浏览器准备发起网络请求
- 查找缓存
在正在发起网络请求之前,浏览器会现在浏览器缓存中查询是否有请求的文件,其实浏览器缓存是一种本地保存的资源副本,以供下次请求时直接使用的技术。
当浏览器发现请求的资源已经在浏览器缓存中存有副本,它会拦截请求,返回该资源的副本,并直接结束请求。而不会再去源服务器中重新下载。这样可以缓解服务的压力,提升性能。如果缓存查找失败,则进入网络请求。
- 准备IP地址和端口
HTTP和TCP的关系,因为浏览器使用HTTP协议作为应用层协议**,用来封装请求的文本信息**;并使用TCP/IP作传输层协议将它发到网络上,所以在HTTP工作开始之前,浏览器需要TCP与服务器建立连接。也就是说HTTP的内容是通过TCP的传输数据阶段来实现的。
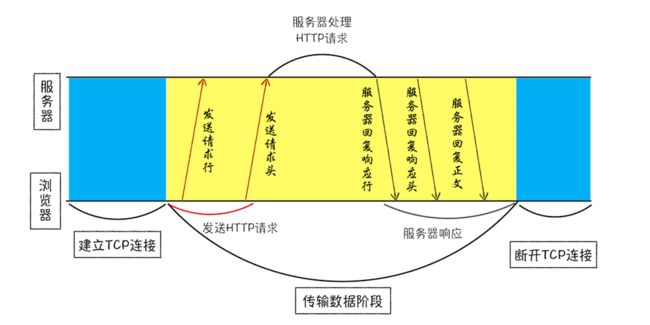
数据包是通过IP地址传输给接收方的。由于IP地址是数字标识的,难以记忆,使用一个域名例如www.baidu.com就容易记忆了,所以基于这个需求又出现了一个服务,负责把域名和IP地址做–映射关系。这套域名映射为IP的系统叫做"域名系统",简称DNS。
第一步浏览器会请求 DNS 返回域名对应的 IP。当然浏览器还提供了 DNS 数据缓存服务,如果某个域名已经解析过了,那么浏览器会缓存解析的结果,以供下次查询时直接使用,这样也会减少一次网络请求。
- 等待TCP队列
IP地址和端口已经准备好了,是不是可以马上建立TCP连接。
不行,因为Chrome有个机制,同一个域名同时最多只能建立6个TCP连接。如果请求书少于6个,直接进入下一步,建立TCP连接。
- 建立TCP连接
排队等待结束后,建立TCP连接
- 发送HTTP请求
3.2 服务端处理 HTTP 请求的流程
历经千辛万苦,HTTP 的请求信息终于被送达了服务器。接下来,服务器会根据浏览器的请求信息来准备相应的内容:
-
返回请求
-
断开连接
通常情况下,一旦服务器向客户端返回了请求数据,它就要关闭TCP连接。不过如果在浏览器或服务器在其头部信息加入Connection:Keep-Alive那么TCP连接在发送后将仍然保持打开状态,这样浏览器可以继续通过同一个TCP连接发送请求。
保持TCP连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。比如一个Web页面中内嵌图片来自于同一个web站点,如果初始化长连接,就不需要重复建立新的TCP连接。
3.3 为什么很多站点第二次打开会很快
因为第一次加载页面的过程中,缓存了一些耗时的数据。
那么,哪些数据会被缓存呢?DNS缓存和页面资源缓存这两块数据是会被浏览器缓存的。
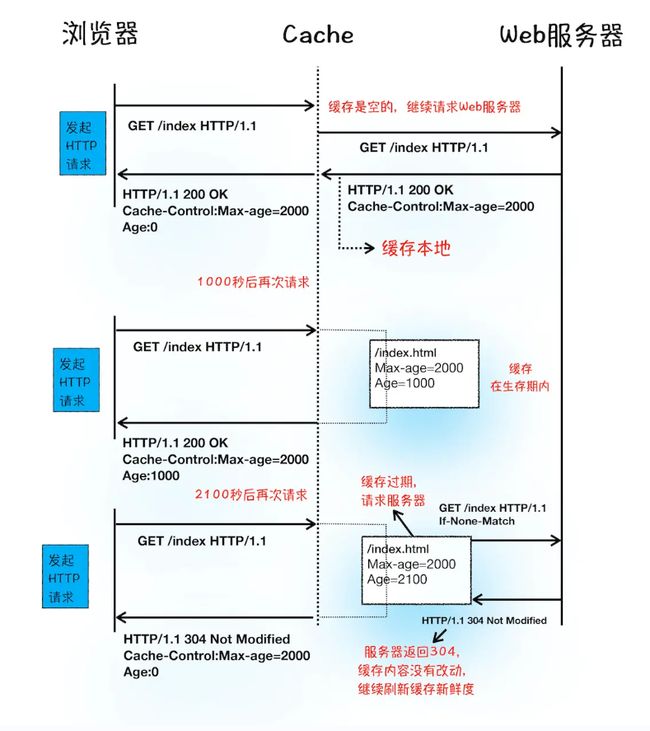
通过上图第一次请求可以看出,当服务器返回HTTP响应头给浏览器时,浏览器通过响应头的Cache-Control字段来设置是否缓存该资源。
Cache-Control:Max-age=2000 //缓存过期时间是2000
这也就意味着,在该缓存资源还没有过期的情况下,如果再次发送请求该资源,会之间返回缓存中的资源给浏览器。
但如果缓存过期了,浏览器则会继续发送网络请求,并且在HTTP请求头中带上:
If-None-Match:"4f80f-13c-3a1xb12a"
简要来说,很多网站第二次访问能够秒开,是因为这些网站把很多资源都缓存在了本地,浏览器缓存直接使用本地副本来回应请求,而不会产生真实的网络请求,从而节省了时间。同时,DNS 数据也被浏览器缓存了,这又省去了 DNS 查询环节。
4. 输入url地址到浏览器显示页面发生了什么
接下来我们从进程角度讨论一下:从浏览器里,输入URL地址,到页面显示,这中间发生了什么?
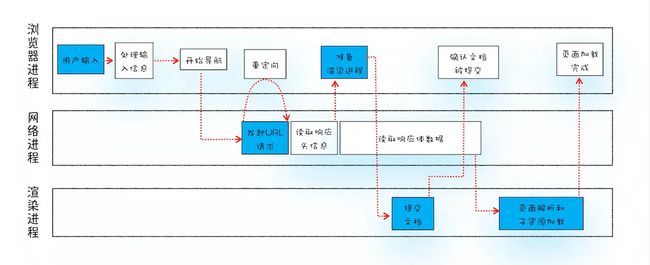
从上图可以看到,整个过程需要各个进程之间的配合,我们结合上图我们从进程的角度,描述一下
1、浏览器进程接收到用户输入的URL请求,浏览器进程便将URL转发给网络进程。
2、网络进程中发起真正的URL请求。
3、网络进程接收到响应头数据,便解析响应头数据,并将数据转发给浏览器进程。
4、浏览器进程接收到网络进程的响应头数据之后,发送"提交文档"消息到渲染进程。
5、渲染进程接收到"提交文档"的消息之后,便开始准备接收HTML数据,接收数据的方式是直接和网络进程建立数据管道。
6、等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。
7、浏览器进程接收到渲染进程"确认提交"的消息之后,便开始移除之前旧的文档,然后更新浏览器进程中的页面状态。
所谓提交文档,就是浏览器主进程,将网络进程接收到的HTML数据提交给渲染进程。
5. 浏览器渲染流程
接下来我们从一个简单的html页面来谈浏览器的渲染流程:
5.1 构建 DOM 树
DOM解析的特点,是不会被阻塞的。因为浏览器无法直接理解和使用HTML,所以需要将HTML转化为浏览器能够理解的结构—DOM树。树结构很像我们现实生活中的"树",其中的每一个点我们称为**节点,**相连的节点称为父子节点。在浏览器渲染中,我们使用的就是树结构。
DOM树描述了文档的内容。元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点。DOM节点的数量越多,构建DOM树所需的时间就越长。
HTML内容转换为浏览器DOM树结构的过程:字节 → 字符 → 令牌 → 节点 → 对象模型。
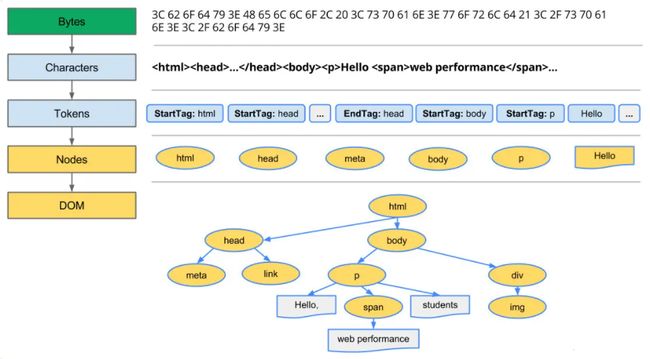
- 转换: 浏览器从磁盘或网络读取 HTML 的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符。
- 令牌化: 浏览器将字符串转换成 W3C HTML5 标准规定的各种令牌,例如,“”、“”,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则。
- 词法分析: 发出的令牌转换成定义其属性和规则的“对象”。
- DOM 构建: 最后,由于 HTML 标记定义不同标记之间的关系(一些标记包含在其他标记内),创建的对象链接在一个树数据结构内,此结构也会捕获原始标记中定义的父项-子项关系: HTML 对象是 body 对象的父项,body 是 paragraph 对象的父项,依此类推。
当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个CSS文件时,解析也可以继续进行,但是对于