【C++入门第二期】引用 和 内联函数 的使用方法及注意事项
- 前言
- 引用的概念
- 初识引用
-
-
- 区分引用和取地址
-
- 引用与对象的关系
- 引用的特性
- 引用的使用场景
- 传值和引用性能比较
- 引用和指针的区别
- 内联函数
- 内联函数的概念
- 内联函数的特性
前言
本文主要学习的是引用 及 内联含函数,其中的引用在实际使用中会异常舒适。
引用的概念
概念:引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
打个比方:你的名字叫张小三,你妈叫你小张,同学叫你小三,公司员工叫你张总。如上所述虽然你名字叫张小三,但大家却叫着你不一样的别名(小张/小三/张总)且你也知道他们是在叫你。
初识引用
使用方法:
类型& 引用变量名(引用对象别名) = 引用对象;
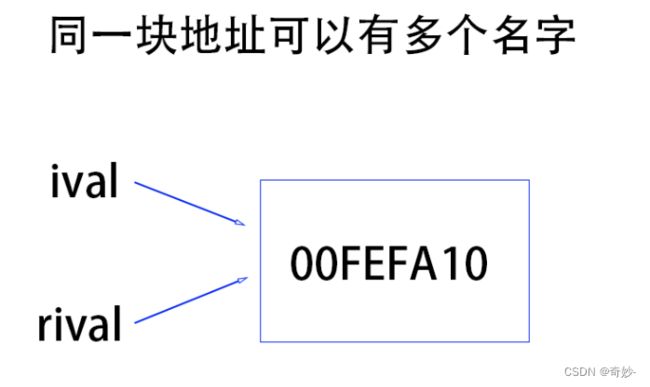
如下变量 rival 引用了 ival

区分引用和取地址
注意:& 即可 取地址 也能 引用
区分方法:&左边 “为类型名”则为引用 ,&左边“不是类型名”则为取地址 (先记住后面会解释为什么)

引用与对象的关系
如下:rival 引用了对象vial ,打印出 rival 和 ivil 的值一致。

但仅仅只是值一样吗?
下面我打印出 rival 和 ivil 的地址,两者地址也一致。

经实践得出以下两个点:
1:引用和被引用对象存储的内容一致
2:引用和被引用对象的地址一致
总结:地址都一样所以他们访问的是同一块内存
再举个栗子:一开始我们给 00FEFA10( 开始的4字节)这块地址取名(变量名)为ival ,后面我们又给 00FEFA10( 开始的4字节)这块地址取个新名字 rval,且新老名字均可用。
提出问题:既然引用是给和被引用对象访问的是同一块内存,那其功能是否一致呢?
下图依然是 rival 引用了对象vial ,rival改变时 rvial 也改变 ,ival改变时 rvial 也改变。
这是肯定的因为两者地址都一样

引用的特性
-
引用在定义时必须初始化
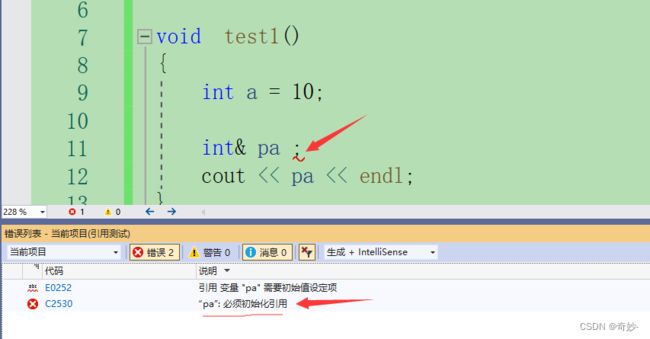
引用等于是给某个变量取别名,所以必须明确(初始化)这个别名给谁 -
一个变量可以有多个引用

还是上面那个例子:你的名字叫张小三,你妈叫你小张,同学叫你小三,公司员工叫你张总。
虽然这几个名字有所不宜但都是你 -
引用一旦引用一个实体,再不能引用其他实体

可以看到当 pa 初始化为 a 的引用后,pa = b 时 b 只是把值赋值给了 pa
pa 和 a 的地址仍然一样,只是值发生了变化。由此可见 , 引用一旦初始化则引用对象就不会发生改变
4:当引用对象为const修饰对象时,引用也应为 const 修饰
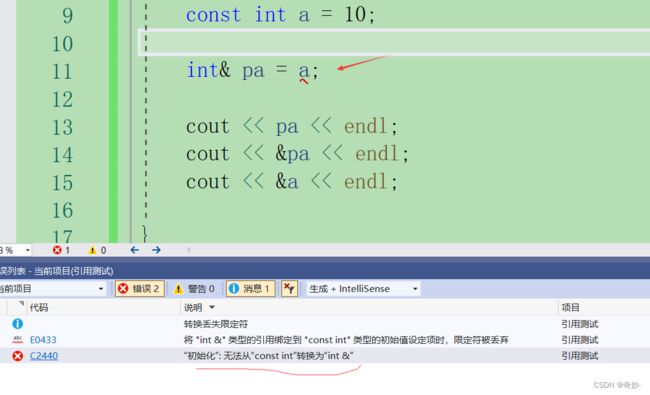
当 a 为 const int 类型时,用 int 类型的 pa 引用 a 时会报错。原因是两者类型不匹配当int类型对象引用const int 对象时存在权力放大,这是不被编译器允许的,语法本身也不允许。
因为int 类型是变量 ,而 const int 是具有常量属性的。所以引用对象也应为 const int 类型 ;如下

4.1 但是如果被引用对象为 int 类型 ,引用可以为const int 类型
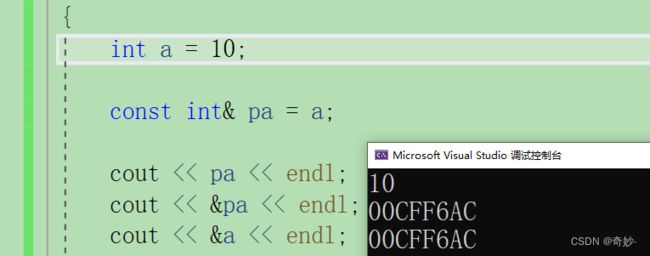
如上图被引用对象为 int 类型 ,引用可以为const int 类型,这种现象叫做权力缩小, 权力缩小是被编译器及语法所允许的。
就如下图,在C语言中当我们不想让指针通过解引用改变变量时,就会在类型前加const,这也是一种权力缩小

总结:
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实体
4. 引用时权力只能同等(int 和 int )或 缩小,不能放大。但引用的权力缩小并不影响被引用对象
引用的使用场景
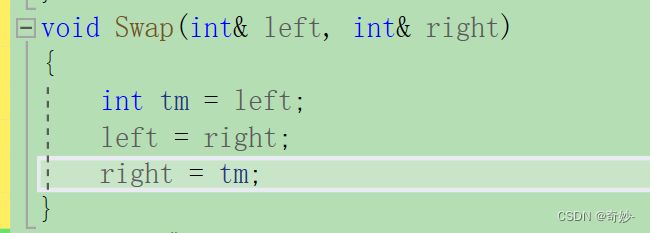
- 做参数
对比使用指针做参数使用起来更简单哦
- 做返回值

但是注意:返回的引用对象出了其函数作用域必须还存在,接收其返回值的对象将能接收到,如果返回对象出了函数作用域就被销毁了只能用传值返回
传值和引用性能比较
在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此大量用值作为参数或者返回值类型,效率是比较低的,尤其是当参数或者返回值类型非常大时,效率就更低。
如下是传值调用和传引用调用的测试代码
#include 经测试当我们传的是 A 这样的结构体分别循环100000次时,传值调用和传引用调用相差巨大分别是759和2,两者相差300多倍

如下是传值和引用返回测试代码
#include 经测试当我们返回的是 A 这样类型的结构体分别循环100000次时,值返回和引用返回相差巨大分别是1549和2,两者相差700多倍

通过上述代码的比较,发现传值和引用在作为传参以及返回值类型上效率相差很大
我给定的测试数据量都比较大,方便让大家看出差距,具体可用上述代码自行测试哦;
引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间

在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。同时我们来看下引用和指针的汇编代码对比
如下图可以看到,引用和指针的汇编代码一致

引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何
一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
内联函数
引出:
当我们某个函数需频繁调用时,函数栈帧建立会异常频繁导致代码效率下降
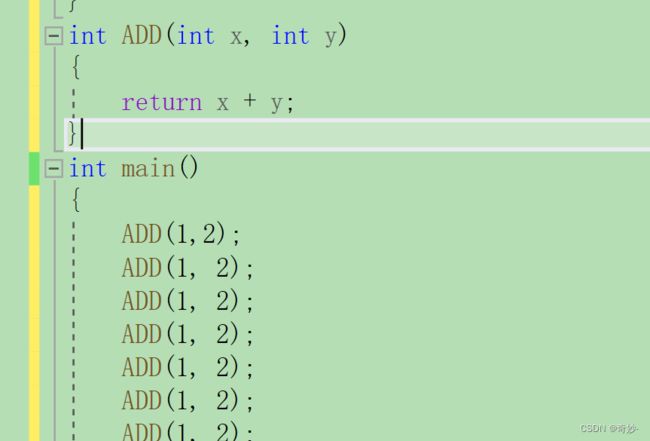
以前我们会把一些短小的函数写成宏来解决这一问题比如下图

但是宏也有缺点:
1.不能调试
2.没有类型安全的检查
3.有些场景下非常复杂
而 C++ 针对这一问题设计出了内联函数 ,内联函数的关键字为 inline
inline int ADD(int x, int y)
{
int ch = x + y;
return ch;
}
int main()
{
ADD(1,2);
ADD(1, 2);
return 0;
}
内联函数的概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
查看设置
在 release 版本下,inline 内联函数会直接在调用部分展开但是 release 版本下其他版本优化的太多,不太好观察
debug 版本则需要自己设置一下编译器才能查看,否则不会展开因为debug不做代码优化
(vs2019)首先打开解决方案资源管理器,右击项目名称,选中属性并打开点击常规->调试信息格式,选择程序数据库
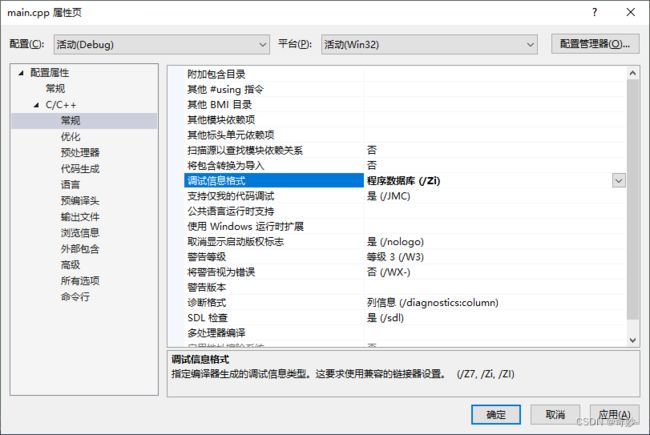
在 C/C++ 优化一栏,将内联函数扩展部分选中 ->只适用于 __inline (/Ob1)

设置完成点击应用
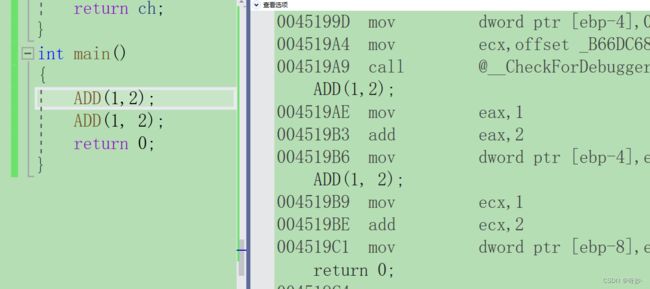
设置前汇编代码,可以看到需要调用ADD函数
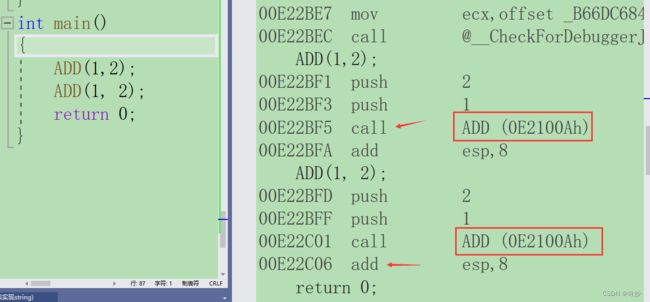
设置后汇编代码可以看到,call ADD不见了,call 是函数调用的指令,没有说明代码没有进行函数调用,内联函数直接在局部展开了。
内联函数的特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运
行效率。 - inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为《C++prime》第五版关于inline的建议:

- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
结论:函数内容较短,且频繁调用的函数建议定义成 inline 可节省函数栈帧的消耗