注意力机制详解系列(三):空间注意力机制

作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。
专栏推荐: 目前在写CV方向专栏,更新不限于目标检测、OCR、图像分类、图像分割等方向,目前活动仅19.9,虽然付费但会长期更新,感兴趣的小伙伴可以关注下➡️专栏地址
学习者福利: 强烈推荐一个优秀AI学习网站,包括机器学习、深度学习等理论与实战教程,非常适合AI学习者。➡️网站链接。
技术控福利:程序员兼职社区招募,靠谱!覆盖技术范围广,深度学习CV、NLP均可,Pyhton、matlab各类编程语言, 有意向的同学➡️访问地址。
导读:本篇为注意力机制系列第三篇,主要介绍注意力机制中的空间注意力机制,对空间注意力机制方法进行详细讲解,会对重点论文会进行标注 * ,并配上论文地址和对应代码。
注意力机制详解系列目录:
1️⃣注意力机制详解系列(一):注意力机制概述
2️⃣注意力机制详解系列(二):通道注意力机制
3️⃣注意力机制详解系列(三):空间注意力机制
4️⃣注意力机制详解系列(四):混合与时域注意力机制(待更新)
5️⃣注意力机制详解系列(五):注意力机制总结(待更新)
1.空间注意力机制
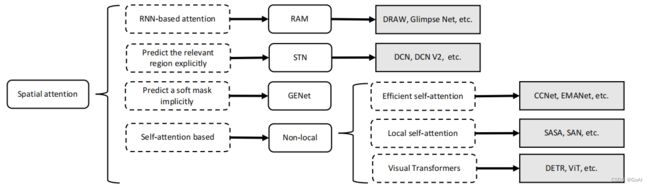
空间注意力机制分类:
空间注意力可以看作是一种自适应的空间区域选择机制:关注哪里。RAM、STN 、GENet 和 Non-Local代表了不同种类的空间注意方法。 RAM 代表基于 RNN 的方法。 STN 代表那些使用子网络来明确预测相关区域的人。 GENet 代表那些隐式使用子网络来预测软掩码以选择重要区域的方法。 Non-Local 表示自注意力相关的方法。
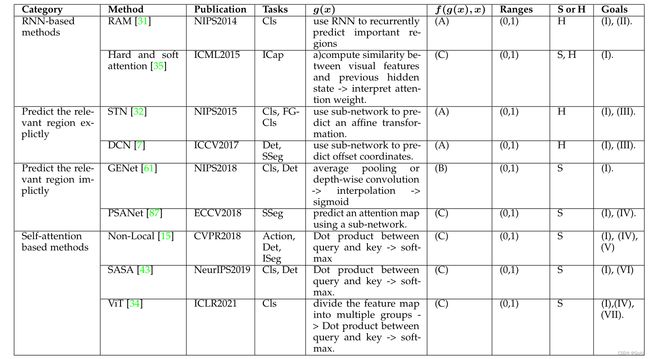
总结:空间注意力机制主要包括RNN为基础的注意力机制、预测相关区域的注意力机制、预测潜在mask的注意力机制以及自注意力机制。 RAM为用于cv领域,backbone为RNN的注意力机制,DRAW,Glimps Net 是基于此的拓展和延申;STN为最早关注相关区域的注意力机制,DCN,DCN V2 也是此后研究关注相关区域的注意力;GENet为预测潜在mask的注意力机制;在自注意力机制上,一开始提出是Non-local ,后续有提高效率的自注意力:CCNet,EMANet; 有关注局部的自注意力:SASA,SAN;从transformer 进入cv后,又有基于transformer改进的自注意力:ViT,DETR等。
RAM
论文: https://arxiv.org/abs/1406.6247
github: https://github.com/jlindsey15/RAM
RAM是谷歌在14年基于RNN提出的注意力机制,用于图像分类,在14年卷积网络刚提出时,受限于硬件资源等因素,对计算量敏感,而当时减少计算量的方法主要有两个:一是减少窗口数量、二是引入注意力。
于是作者将注意力问题看作目标驱动的序列决策问题,使用了一个代理(agent)实现与环境的可视交互。代理每次只会用有限波长宽度的sensor来检测图像中的环境,但不会是全部图像。由于环境也都只是被部分检测到,因此后面还需要agent整合所有信息。在每一步,代理都会得到一个奖励,目的是要最大化代理得到奖励,一种强化学习的机制,因此该模型是典型的硬性注意力模型。
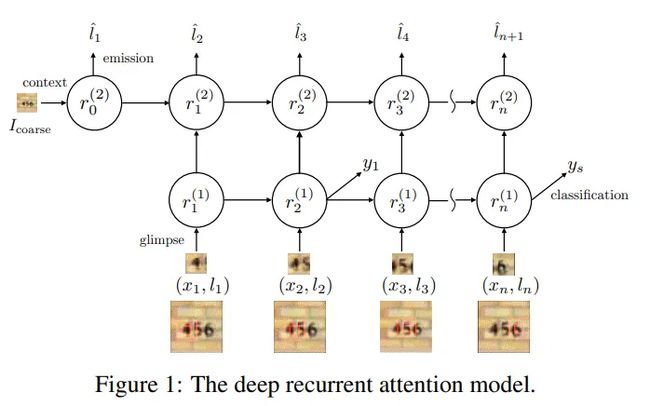
RAM 具有三个关键元素:(A)a glimpse 传感器,(B)a glimpse 网络和(C)一个 RNN 模型。
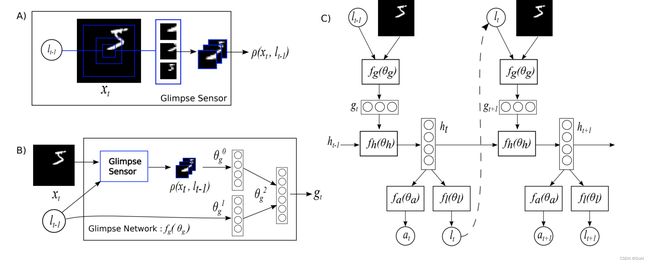
RAM中的注意力过程。 (A):a glimpse传感器将图像和中心坐标作为输入并输出多个分辨率补丁。 (B):a glimpse网络包括a glimpse传感器,以图像和中心坐标作为输入并输出特征向量。 © 整个网络循环使用一个 glimpse 网络,输出预测结果以及下一个中心坐标。
该模型利用RNN结构,并结合LSTM,按照序列决策(sequential decision)的思路,从图像或者视频中以自适应方式不断挑选重要区域并对其进行高分辨率处理,而这些所谓的“重要区域”即为那些能够为视觉任务带来决定性影响的注意力投射区域。
这种网络的优势在于:(1)参数量和计算量都能够通过输入图像的尺寸进行控制(2)RAM能够忽略杂乱图像中的噪声部分(3)能够方便的进行扩展(4)网络对输入图像采样的尺度能够控制,使它可用于不同尺寸的图像。可以将网络集中在关键区域,从而减少网络执行的计算次数,特别是对于大输入,同时改善图像分类结果。
DRAW
论文:https://arxiv.org/pdf/1502.04623.pdf
github: https://github.com/ericjang/draw
DRAW是15年Google Deepmind 发表在ICML上的一篇文章,用于图像生成领域,该网络用于模仿人眼视觉偏好性的空间注意力机制,基于变分自动编码器(Variational AutoEncoder VAEs),对图像自动生成。
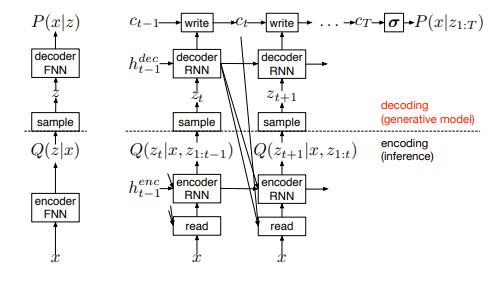
相对于上图左侧一般的变分编码器,右侧会基于前一次的解码器的输出来选取重点区域关注,参与这次的编码过程,解码器的结果也是之前结果的累加。
Glimpse Net
论文:https://arxiv.org/pdf/1412.7755.pdf
github: https://github.com/sai19/Multiple-object-recognition-with-visual-attention
Glimpse Net是15年Google Deepmind 发表在ICRL上《Multiple Object Recognition With Visual Attention》文章中提到的一个网络,
STN-Net
论文地址:https://arxiv.org/pdf/1506.02025.pdf
参考代码:
tf: https://github.com/kevinzakka/spatial-transformer-network
pytorch: https://github.com/qassemoquab/stnbhwd
STN-Net《Spatial Transformer Networks》是15年NIPS上的文章,提出了空间变换器的概念,STN-Net认为传统的卷积网络如果没有pooling层会要求输入数据空间固定,而pooling的方法过于暴力,可能会导致关键信息无法识别,所以提出了一个空间转换器(Spatial Transformer)的模块,主要作用是找到图片中需要被关注的区域,并对其旋转、缩放,提取出固定大小的区域。

空间采样器的实现主要分成三个部分:1)局部网络(Localisation Network);2)参数化网格采样( Parameterised Sampling Grid);3)差分图像采样(Differentiable Image Sampling)。
在理解采样器前需要大家对图像的仿射变化、旋转、平移等图像处理有先验知识,会发现对图像做旋转等变换时,实际上即是通过矩阵则可达到:
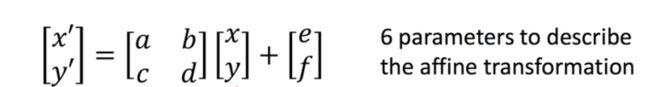
局部网络是将图像提出特征的feature map作为输入,通过本地网络(卷积,FC等)训练出来的参数θ,在图像类一般是个[2,3]大小的6维变换参数;
参数化网格采样则是将训练的参数将输入的特征图进行变换,这决定了变换前后图像之间的坐标映射关系。
差分图像采样是根据第二步产生的坐标映射关系将输入图像U像素点变换成输出图片V的像素点。这里需要注意的是,提取到输出特征图对应到输入特征的位置可能不一定是整数点,非整数坐标的像素点需要通过双向线性插值提取。
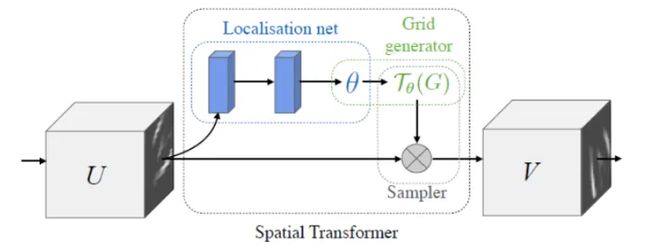
因以上三个网络均为可微的,因此它可以插入到正常的网络中,通过反向传播更新参数,且无需额外的监督信息。
DCN v1/v2
v1::https://arxiv.org/pdf/1703.06211.pdf
github: https://github.com/ msracver/Deformable-ConvNets
v2:: https://arxiv.org/pdf/1811.11168.pdf
github: https://github.com/CharlesShang/DCNv2
其核心思想在于,它不认为卷积核应该是规规整整的矩形,其可以是任意形状的,如下图:
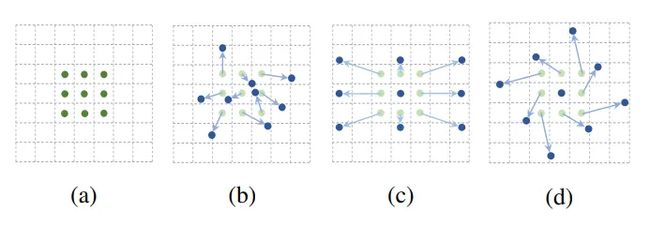
图a标准3x3卷积,b,c,d是给普通卷积加上偏移量的卷积核,蓝色是新的卷积点,箭头是位移方向。
首先普通卷积的操作可以参见这里,对于每个输出y(p0),都要从x上采样9个位置,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角:
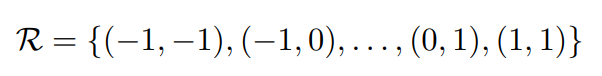
对于传统卷积,公式如下:
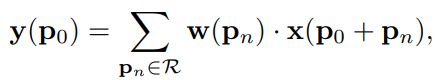
对于可变形卷积,卷积的映射是由下式表示的:
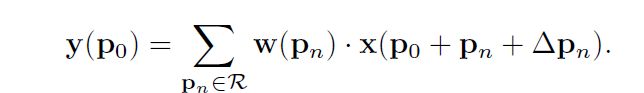
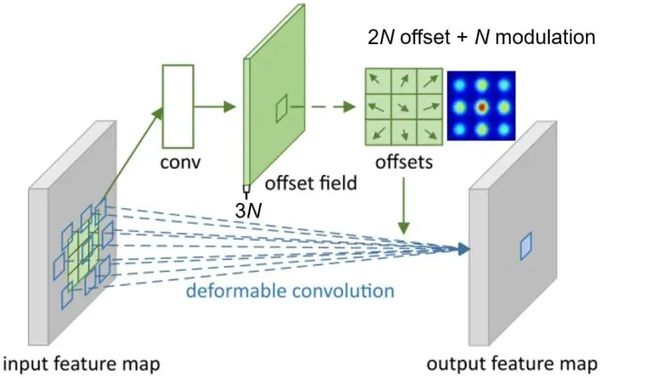
对于左图来说,传统的卷积并不能完整的表示羊的特征,右图采用可变形卷积,充分获取羊的特征。这个偏移量是位置的偏移量,比如卷积核某个点一开始位于(-1,-1)这个位置,有了偏移量后,可能在(-1,2)的位置,另外偏移量可能是个浮点型,所以上式中的x这个特征值需要通过双线性插值的方法来计算。如何获得这个偏移量呢?通过训练学习得到,如下图。
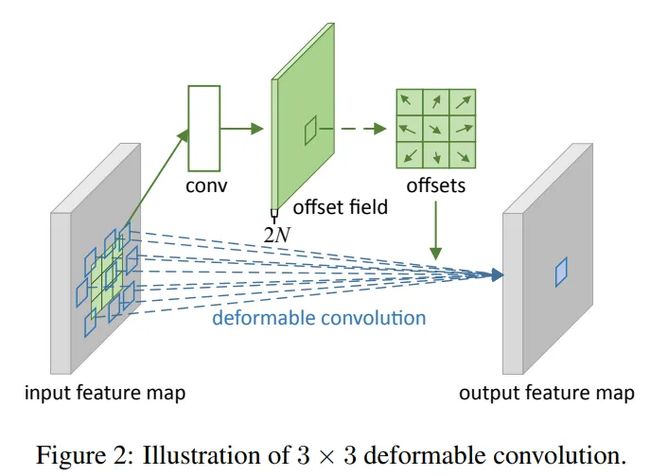
对于输入一张5x5x3的feature map,假设原来的卷积是3x3,inchanel 和outchannel均是3,输出维度仍是5x5x3,现在我们为了学习偏移量,需要重新定义一个3x3的卷积,如上图, 这里inchannel仍是3,但是输出的outchannel需要是2倍,即6,因为他需要输出x和y两个方向的偏移量,获得每个点偏移量后,即获得△Pn, 因为△Pn不一定是整数,所以需要基于输入的特征值双线性插值获得x(p0+pn+△Pn)值,后面和普通的卷积一样,权值相乘后相加。以上可变形卷积可以自适应的学习感受野,学习与目标区域感兴趣的区域。
DCN v2 作者可视化了DCNv1的结果:

图中发现可变形卷积会引入无用的上下文信息,其感受野容易超出目标范围,干扰特征提取,为此作者提出了DCNv2解决此问题:
-
使用更多的可变形卷积;
-
在DCNv1的基础上添加每个采样点的权重;
-
针对可变形卷积的训练,为了让其更好的学习,通过RCNN指导Faster RCNN做知识蒸馏。
DCN v1 给普通卷积的采样点增加偏移,v2在此基础上还允许调节每个采样位置或者bin的特征的权值,就是给这个点的特征乘以个系数,位于(0,1)之间,如果系数为0,就表示这部分区域的特征对输出没有影响,这个系数也是通过训练学习得到,这样在可变形卷积的输出通道由之前的2N增加到3N:
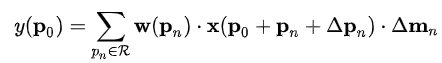
GENet
论文:https://arxiv.org/abs/1810.12348
github: *https://github.com/hujie-frank/GENet*.
受 SENet 启发,Hu 等人设计 GENet 通过在空间域中提供重新校准功能来捕获远程空间上下文信息。GENet 结合了部分收集和激发操作。
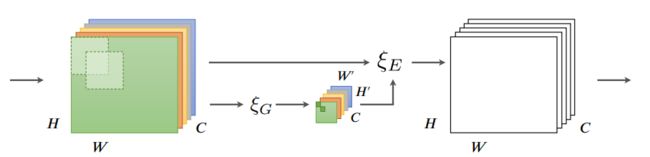
第一步,它聚合大邻域的输入特征,并对不同空间位置之间的关系进行建模。在第二步中,它首先使用插值生成与输入特征图大小相同的注意力图。然后通过乘以注意力图中的相应元素来缩放输入特征图中的每个位置。这个过程可以描述为:
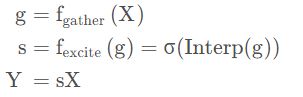
在这里,fgather(X)可以采用任何捕捉空间相关性的形式,例如全局平均池化或一系列深度卷积;Interp ( ⋅ ) (\cdot)(⋅)表示插值。
Gather-excite 模块是轻量级的,可以像 SE 块一样插入到每个残差单元中。它在抑制噪音的同时强调重要特征。
*Non-local Neural Networks
论文:https://arxiv.org/abs/1711.07971
github: https://github.com/facebookresearch/video-nonlocal-net
Non-local Neural networks 是CVPR2018提出的一个自注意力模型,普通的卷积即局部注意力,是3*3的卷积核,然后在整个图片上移动,non-local是综合一个比较大的搜索范围,并进行加权。作者基于图片滤波中的non-local means 的思想,提出的一个非局部操作算子,非局部操作可以直接计算图片空间中两个位置之间的关系,忽略其空间位置的影响,具体计算公式如下:
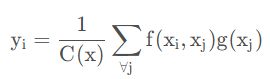
其中x为输入信号,在cv中为feature map; i为输出位置,输出位置响应等于所有枚举j对i的响应计算得到;f计算i与j之间的相似度;g计算feature map在j位置上的表示;y通过c(x)进行标准化处理后得到;
具体在cv上的计算示例图如下:
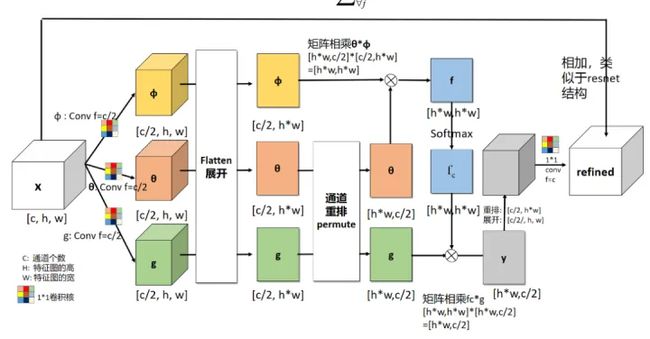
简化版如下:
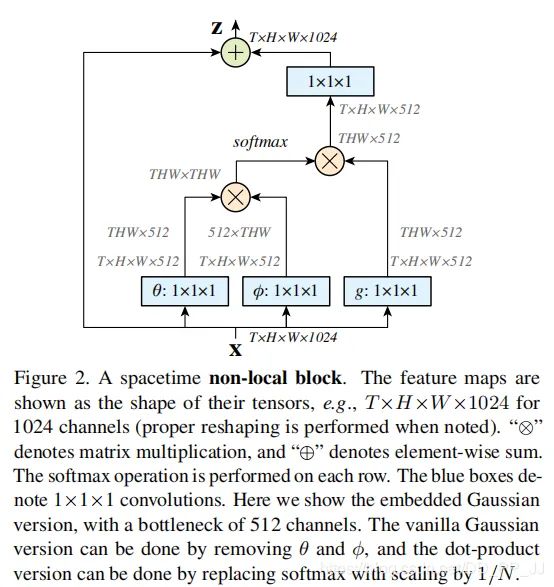
文中谈到有多种实现方式,本文中介绍其中一种简单的:
-
首先在输入的特征图进行线性映射(通过1*1的卷积,压缩通道数),得到θ,φ,g 特征;
-
通过reshape操作,强行合并上述三个特征除通道外了其他维度,对θ和φ进行举证点乘操作,用于计算特征中的自相关性,得到每个像素对其他像素的关系;
-
通过对自相关特征进行softmax操作,得到[0,1]的权重,即自注意力系数;
-
将自注意力系数乘回矩阵g中,并通过1*1卷积,拓展通道数,与输入的特征图相加,得到non-local 模块的输出。
non-local 模块保证了输入和输出尺寸不变,容易嵌入网络架构中,通过直接融合全局信息,计算量和参数量均有一定的增加。non-local 因为时间原因也有一定的局限性:1. 没有考虑到通道注意力;2. 如果特征图很大,则会很耗内存和计算量。
CCNet
论文:https://arxiv.org/pdf/1811.11721.pdf
github: https://github.com/speedinghzl/CCNet
Non-local可以看成是注意力机制下的密集连接的GNN,虽然能够捕获全局的上下文信息,但是其计算复杂度为O(N^2),为了解决复杂度问题,CCNet提出一个更高效的注意力机制——交叉注意力模块,用于语义分割领域,其与Non-local的对比见图1:
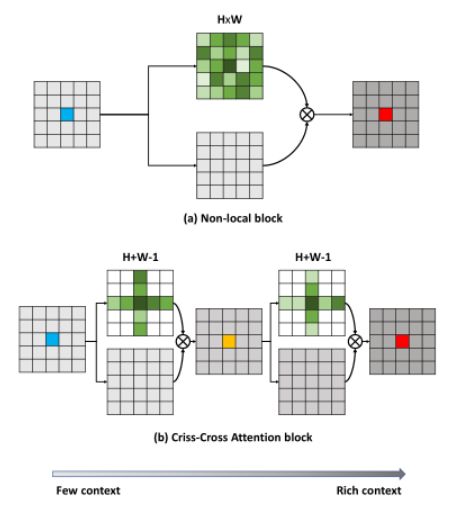
如上图可知,与Non-local相比,criss-cross attention module生成attention map只利用了十字交叉路径上的特征,这种操作大大降低了计算复杂度。交叉注意力模块的结构如下图,但是单次的criss-cross attention module只能捕获十字交叉路径上的特征,为了同时用上其他位置特征,作者用了两次criss-cross attention module,第一次相关性计算会将当前像素的信息传递到同行同列的所有位置,第二次计算时之前接受到信息的每个像素又会将再次将信息传递到自己的同行同列。如下二图所示,称为RCCA模块:
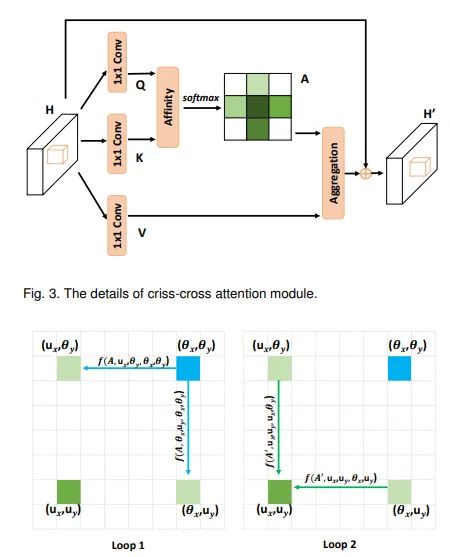
这样通过RCCA模块,即可获得全局信息,与Non-local达到相同的目的,但是其复杂度从O(N2)*变成*O(N(3/2)).
EMANet
论文: https://arxiv.org/pdf/1907.13426.pdf
代码: https://github.com/XiaLiPKU/EMANet
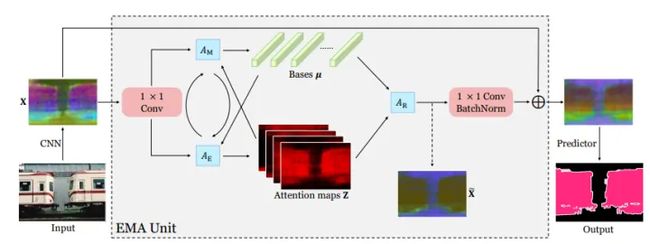
EMANet的提出也是为了解决Non local带来的计算量过于庞大的问题,该论文将注意力机制表述为一种期望最大化方式,并自动估计出一组更紧凑的基,在此基础上计算注意力图。通过对这些基的加权求和,得到的表示是低秩的,并且有效消除来自输入的噪声信息。所提出的期望最大化注意力(EMA)模块对输入方差具有鲁棒性,并且在内存和计算方面也很友好。
SASA
论文:https://arxiv.org/pdf/1906.05909.pdf
github: https://github.com/leaderj1001/Stand-Alone-Self-Attention
主要的贡献是提出使用 “自注意力操作”代替一般的空间卷积操作,以弥补空间卷积无法有效捕捉长距离信息间的关系的不足,同时使用的计算量和参数量更少.目前的self attention平等对待中心像素邻近的其他像素点,没有利用位置信息,因此文中进一步通过用嵌入向量来表示相对位置,把位置信息也添加到了自注意力操作中。
这里作者通过实验也说明了 相对位置信息> 绝对位置信息 > 没有位置信息.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D3iYCZ4l-1677209355776)(null)]正在上传…重新上传取消转存失败重新上传取消
SAN
论文:https://arxiv.org/abs/2004.13621
github: https://github.com/hszhao/SAN
这篇文章发表在CVPR2020。作者提出一种将self-attention机制应用到图像识别领域的方法。作者认为,使用卷积网络进行图像识别任务实际上在实现两个函数:
-
特征聚集(feature aggregation): 即通过卷积核在特征图上进行卷积来融合特征的过程。
-
特征变换(feature transformation): 在卷积完成后进行的一系列线性和非线性变换(比如全连接和激活函数。这一部分通过感知机就能很好地完成。
在以上观点的基础上,作者提出使用self-attention机制来替代卷积作为特征聚集方法。为此,作者考虑两种self-attention形式:pairwise self-attention和patchwise self-attention。用这两种形式的self-attention机制作为网络的basic block提出SAN网络结构。与经典卷积网络ResNet进行对比,SAN网络具有更少参数和运算量,同时在ImageNet数据集上的分类精确度有较大提升。
ViT/DETR
VIT: 论文:https://arxiv.org/pdf/2010.11929.pdf
github: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/vision_transformer.py
DETR:论文:https://arxiv.org/pdf/2005.12872.pdf
github: https://github.com/facebookresearch/detr
vision transformer 中的注意力机制为transformer在encode时的多头注意力机制,因为vision transformer 是将transformer从nlp中用于cv中,尽量少的变动transformer ,所以文中提出(key,query, value)三元组捕捉长距离依赖的建模方式同nlp中的self-attention,如下图所示,key和query通过点乘的方式获得相应的注意力权重,最后把得到的权重和value做点乘得到最终的输出。公式如下:
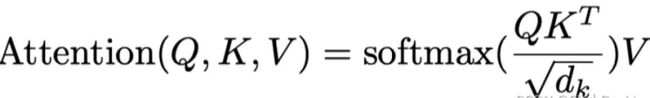
process=image/format,png)
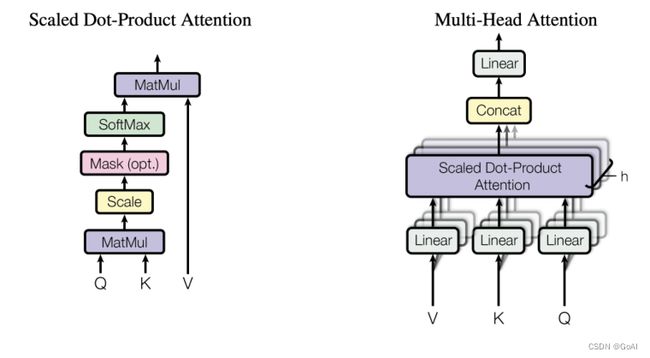
整体的vision transformer 网络架构如下图:
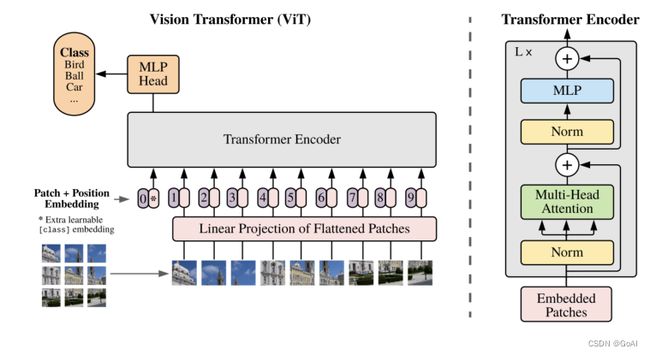
视觉Transformer。左:架构。视觉Transformer首先将图像分割成不同的块并将它们投影到特征空间中,在特征空间中,Transformer编码器对其进行处理以产生最终结果。右图:具有多头注意力核心的基本视觉Transformer模块。
DETR是Facebook在2020年提出,是transformer在目标检测任务上的应用,利用Transformer中attention机制能够有效建模图像中的长程关系(long range dependency),简化目标检测的pipeline,构建端到端的目标检测器。
空间注意力机制论文下载
Spatial attention
- Recurrent models of visual attention (NeurIPS 2014), pdf
- Show, attend and tell: Neural image caption generation with visual attention (PMLR 2015) pdf
- Draw: A recurrent neural network for image generation (ICML 2015) pdf
- Spatial transformer networks (NeurIPS 2015) pdf
- Multiple object recognition with visual attention (ICLR 2015) pdf
- Action recognition using visual attention (arXiv 2015) pdf
- Videolstm convolves, attends and flows for action recognition (arXiv 2016) pdf
- Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition (CVPR 2017) pdf
- Learning multi-attention convolutional neural network for fine-grained image recognition (ICCV 2017) pdf
- Diversified visual attention networks for fine-grained object classification (TMM 2017) pdf
- High-Order Attention Models for Visual Question Answering (NeurIPS 2017) pdf
- Attentional pooling for action recognition (NeurIPS 2017) pdf
- Non-local neural networks (CVPR 2018) pdf
- Attentional shapecontextnet for point cloud recognition (CVPR 2018) pdf
- Relation networks for object detection (CVPR 2018) pdf
- a2-nets: Double attention networks (NeurIPS 2018) pdf
- Attention-aware compositional network for person re-identification (CVPR 2018) pdf
- Tell me where to look: Guided attention inference network (CVPR 2018) pdf
- Pedestrian alignment network for large-scale person re-identification (TCSVT 2018) pdf
- Learn to pay attention (ICLR 2018) pdf
- Attention U-Net: Learning Where to Look for the Pancreas (MIDL 2018) pdf
- Psanet: Point-wise spatial attention network for scene parsing (ECCV 2018) pdf
- Self attention generative adversarial networks (ICML 2019) pdf
- Attentional pointnet for 3d-object detection in point clouds (CVPRW 2019) pdf
- Co-occurrent features in semantic segmentation (CVPR 2019) pdf
- Factor Graph Attention (CVPR 2019) pdf
- Attention augmented convolutional networks (ICCV 2019) pdf
- Local relation networks for image recognition (ICCV 2019) pdf
- Latentgnn: Learning efficient nonlocal relations for visual recognition(ICML 2019) pdf
- Graph-based global reasoning networks (CVPR 2019) pdf
- Gcnet: Non-local networks meet squeeze-excitation networks and beyond (ICCVW 2019) pdf
- Asymmetric non-local neural networks for semantic segmentation (ICCV 2019) pdf
- Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition (CVPR 2019) pdf
- Second-order non-local attention networks for person re-identification (ICCV 2019) pdf
- End-to-end comparative attention networks for person re-identification (ICCV 2019) pdf
- Modeling point clouds with self-attention and gumbel subset sampling (CVPR 2019) pdf
- Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification (arXiv 2019) pdf
- L2g autoencoder: Understanding point clouds by local-to-global reconstruction with hierarchical self-attention (arXiv 2019) pdf
- Generative pretraining from pixels (PMLR 2020) pdf
- Exploring self-attention for image recognition (CVPR 2020) pdf
- Cf-sis: Semantic-instance segmentation of 3d point clouds by context fusion with self attention (ACM MM 20) pdf
- Disentangled non-local neural networks (ECCV 2020) pdf
- Relation-aware global attention for person re-identification (CVPR 2020) pdf
- Segmentation transformer: Object-contextual representations for semantic segmentation (ECCV 2020) pdf
- Spatial pyramid based graph reasoning for semantic segmentation (CVPR 2020) pdf
- Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (CVPR 2020) pdf
- End-to-end object detection with transformers (ECCV 2020) pdf
- Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling (CVPR 2020) pdf
- Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers (CVPR 2021) pdf
- An image is worth 16x16 words: Transformers for image recognition at scale (ICLR 2021) pdf
- Is Attention Better Than Matrix Decomposition? (ICLR 2021) pdf
- An empirical study of training selfsupervised vision transformers (CVPR 2021) pdf
- Ocnet: Object context network for scene parsing (IJCV 2021) pdf
- Point transformer (ICCV 2021) pdf
- PCT: Point Cloud Transformer (CVMJ 2021) pdf
- Pre-trained image processing transformer (CVPR 2021) pdf
- An empirical study of training self-supervised vision transformers (ICCV 2021) pdf
- Segformer: Simple and efficient design for semantic segmentation with transformers (arxiv 2021) pdf
- Beit: Bert pre-training of image transformers (arxiv 2021) pdf
- Beyond Self-attention: External attention using two linear layers for visual tasks (arxiv 2021) pdf
- Query2label: A simple transformer way to multi-label classification (arxiv 2021) pdf
总结
本篇主要对空间注意力机制进行介绍,着重详解DCN、Non-local、ViT、DETR等模型,下一篇将对混合注意力机制和时域注意力机制进行讲解。
本文参考:https://blog.csdn.net/wl1780852311/article/details/124525739