redis实现分布式锁
分布式锁
1.分布式锁解决的问题
解决分布式环境中由于高并发操作导致的数据一致性问题。

2.应用场景
常见场景:分布式环境中抢优惠券、商品秒杀、抽奖等
3.分布式锁实现方法
3.1使用Redis实现分布式锁
3.1.1环境准备:
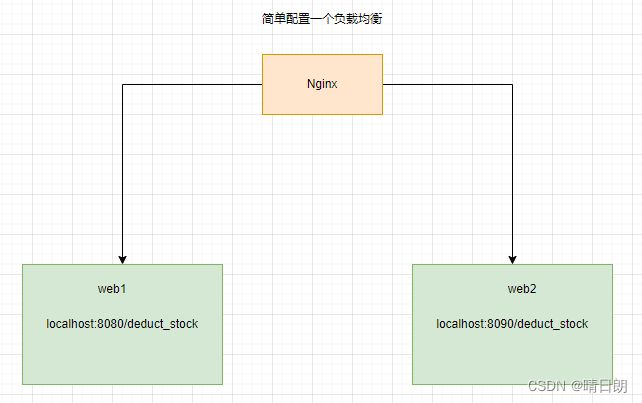
①模拟两个tomcat:本地启动两个springboot搭建的web服务。
②简单配置一个nginx,进行请求的负载。
③使用高并发压测模拟工具jmeter,模拟请求并发量200,并发时间为0:标识瞬间并发200个请求,循环次数设置为4,表示会压测4轮,那就是800个请求。
jmeter使用:(具体的使用另一篇文章记录,客官请移步)
创建一个请求:
设置线组:

3.1.2实现分布式锁及问题记录:
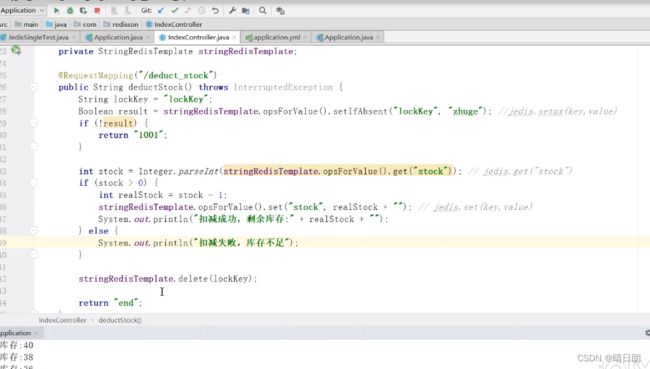
问题所在1:没有释放锁
锁没有正确释放,当扣减库存那部分的业务代码出现异常的时候不能正产释放锁。
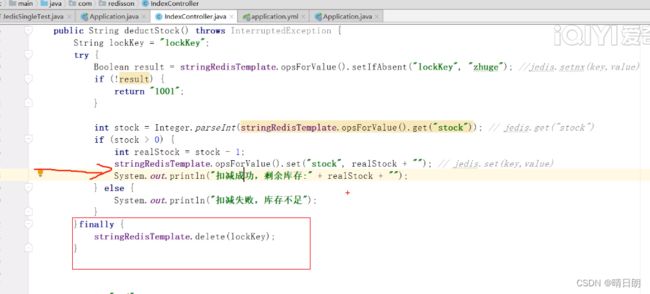
代码优化1:
finally,进行资源最终释放。
问题所在2:没有正确释放锁
以上这段代码正在执行,如果此时机器宕机或者运维正在kill发包,会导致锁也不能正常释放。
代码优化2:
设置锁的有效时间。
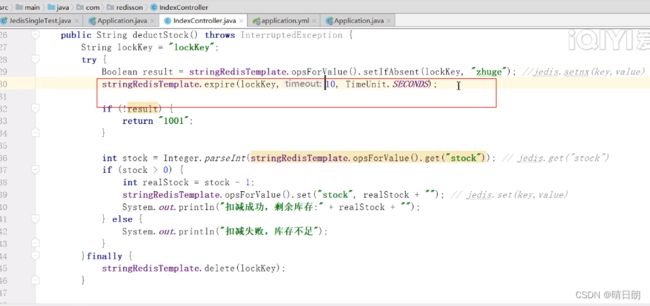
问题所在3:设置锁和锁过期时间设置两个操作非原子操作导致锁不能正常释放
以上这段代码正在执行,setIfAbsent(…)和expire(…)不是一个原子操作,一单宕机操作在这两者之间,那么还是会出现问题2。
代码优化3:
使用另外一个API,set和expire操作是一个原子操作。
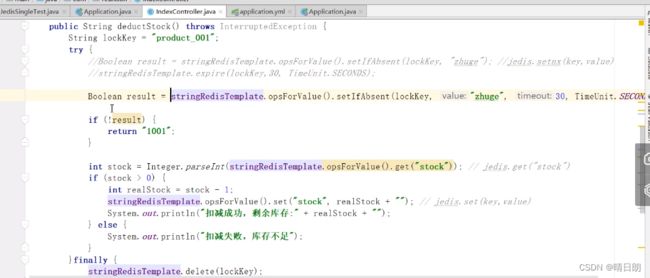
问题所在4:线程只能删除自己锁。
①线程A执行完业务时间需要15s,锁的过期时间为10s,那么就会出现:还没执行完业务逻辑,但是由于超时时间到了,锁被删除了,导致了锁的失效问题。
②此时,高并发下,线程A由于①的原因释放了锁(线程A还在执行业务,假设执行到了10s的位置),线程B能成功获取了锁,正在开始执行业务,假设线程B执行完整个业务需要8s,此时过了5s,线程B还没执行完整个业务,但是由于此时线程A已经执行完了业务逻辑,执行了锁的释放动作,这就会造成线程A把线程B的锁给删除了。下一个线程进来还会如此,一直导致锁失效。
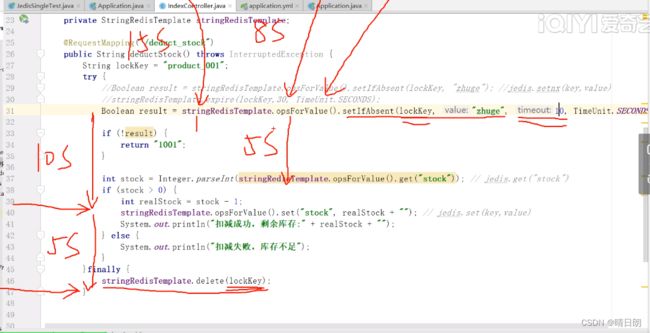
代码优化4:
线程只能释放自己的锁。
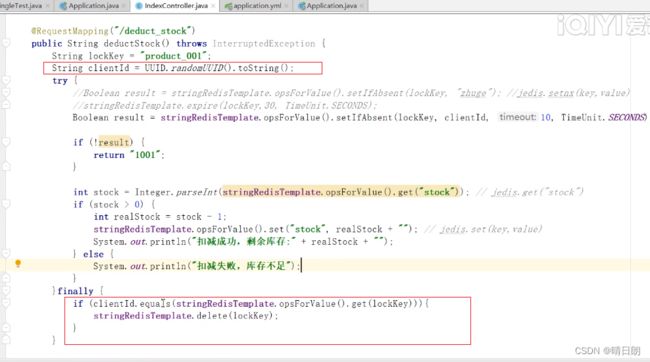
查询clientId和delete(lockKey)两个动作不是原子动作,程序崩溃可能会导致锁没能正常释放。但是此时就算程序挂在了查询clientId和delete(lockKey)之间导致没能正常释放锁,也会有超时时间护航,到了超时时间就自动释放。或者使用Lua脚本操作,Lua脚本是一个原子操作 。
3.1.3redisson实现分布式锁
问题所在5:锁失效-锁续命
到此,一把分布式锁已经实现得差不多了。
但是还是会有比如业务逻辑执行的时候会超过有效时间这种问题,这种问题需要怎么解决呢?
而且,按照我们代码优化4实现的代码,自己实现的分布式锁还是比较复杂的,也还会出现些锁失效问题,所以我们引入开源框架redission来实现分布式锁,redission实现分布式锁非常方便,就不用按照我们之前的方式实现了,前面的就当作是慢慢的理解吧…。
代码优化5:
锁续命。
简单的实现逻辑:假设锁的过期时间是10s,业务逻辑的执行时间需要15s。设计一个timer定时器,每隔8s去扫描一下该任务是否已经执行完毕,该线程是否已经释放锁,否,则将锁的有效时间再延长10s。
redission开源框架实现。
1.引入依赖

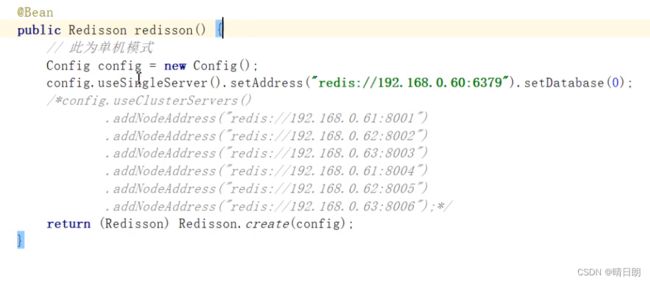
2.初始化-单机模式、主从模式、哨兵模式、集群模式
3.注入使用

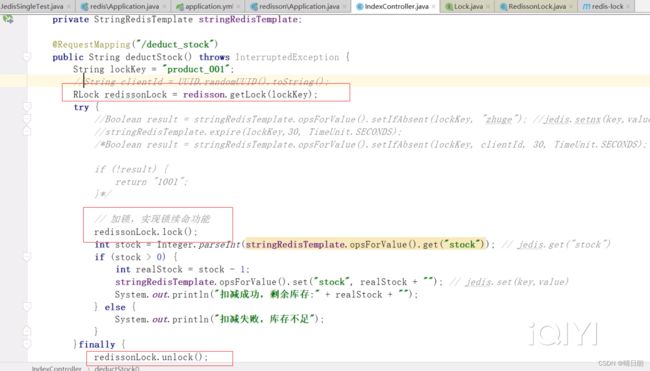
底层原理:
看门狗机制,默认是10s续命一次,每次续命的有效时间默认是30s。使用了大量的Lua脚本。
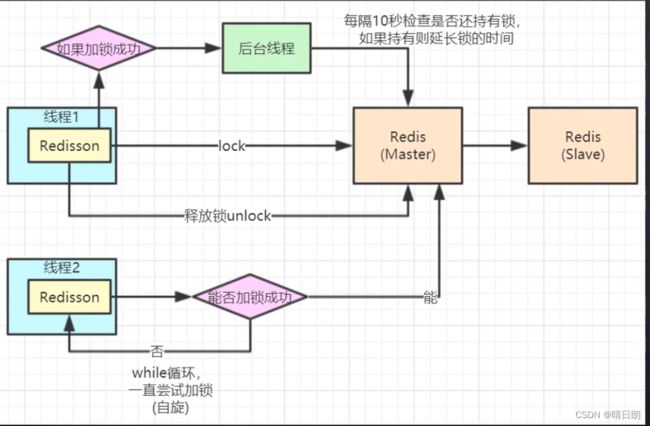
只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用watch dog解决了**「锁过期释放,业务没执行完」**问题。
3.1.4Redlock+Redisson实现分布式锁
问题所在6:

如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
解决方法:
①使用zookeeper实现分布式锁。
但是zookeeper属于强一致性架构,zk实现的分布式锁没有redis实现的分布式锁性能高。
②使用RedLock+Redission实现分布式锁。解决了主从同步导致的锁失效问题,但是可能会有未知的BUG。
底层原理:
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
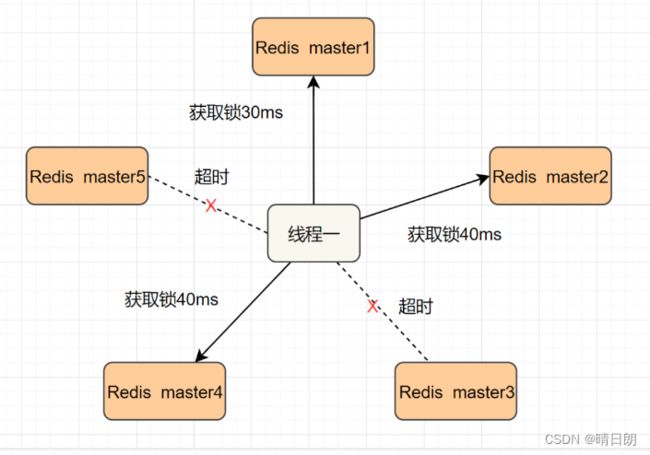
RedLock的实现步骤:如下
1.获取当前时间,以毫秒为单位。
2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
如果获取锁失败(没有在至少N/2+1个master实例取到锁,又或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
实现代码:
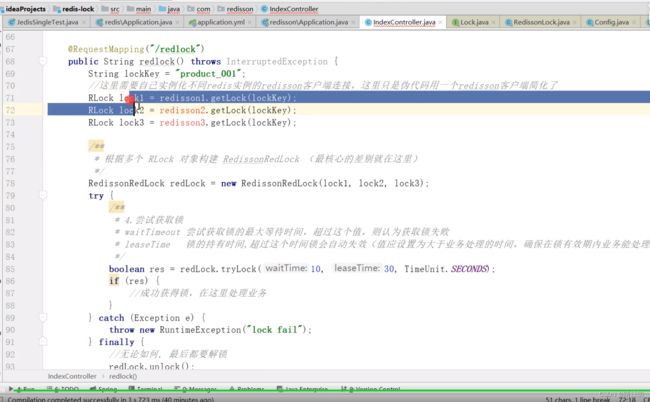
小结:
不建议使用redLock,现在互联网大厂都没怎么选择这种技术。
性能问题:需要多个redis的反馈。
数据问题:网络异常,redis数据是否需要回滚等,某个redis宕机出现问题等,目前业界没有绝对的结论。
4.性能优化方案
4.1需求案例:
商品抢购时,redisssion实现的分布式锁,针对这一块,如何提升10倍的并发能力?
4.2解决方法:
①cluster:多线程抢购不同商品,商品可以分布加载在不同redis上,并发压力负载,充分利用集群缓存的优势,可以提升高并发能力。
②如果是抢购同一商品,那么按道理来说这个商品只会存在一个redis上,如何提升高并发能力呢?
解决方法:分段锁,将该库存分段。
001_1=100;
001_2=100;
001_3=100;
…
001_10=100;
比如:商品001 数量1000
想要提升10倍并发能力,商品库存在redis集群上进行分段存储,分成10段。不同段位的数据通过分段规则定义的key,通过hash(key)落到不同的cluster节点redis上去,充分利用了redis,这不就是水平扩容了吗。这个思路类似于concurrentHashMap的分段锁源码。要想实现,代码量可不少哦。目前GitHub好像有相关的开源框架。
5.Redisson读写锁
这个就不记录在这了,后期性能优化或者再单独记录读写锁。
-end-