Java开发 - Elasticsearch初体验
目录
前言
什么是es?
为什么要使用es?
es查询的原理?
es需要准备什么?
es基本用法
创建工程
添加依赖
创建操作es的文件
使用ik分词插件
Spring Data
项目中引入Spring Data
添加依赖
添加配置
创建操作es的业务逻辑
创建数据模型
创建持久层
测试
自定义查询
单条件查询
多条件查询
结语
前言
接上一篇微服务,这一篇将对es进行讲解。应该没有谁的数据库就三五百条数据吧?不,三五千条也实在是不多的,如果是微服务项目,没个百万级千万级数据好意思用es?总之我是不好意思用的。很多时候,谈到微服务,总是觉得很难,实际上,微服务是由很多独立的模块组装起来的一个项目,也就是功能多了点,服务多了点,其实也没什么可怕的,如果你看完了上一篇微服务,那相信你对微服务已经基本了解了,既然是微服务项目,那怎么少的了es呢?今天的目标就是要让大家学会es的使用,那我们现在就开始吧。
什么是es?
es全称Elasticsearch,开发界简称es,如果你是做开发的,和后台接触时多多少少应该听过他们说es,redis这些不知所谓的名词,今天,你学习这部分内容就是当初不明所以的东西es。
首先声明,es不是SpringCloud的组件,也并不是Java专属的,其他的后端语言也可以使用es。由于es是一个由Java开发的软件,所以启动需要Java环境变量。
es有一个中文名字,叫全文搜索引擎,它的优点是可以从大量数据中根据指定的关键字快速的匹配出相关的内容。注意这个快速,我们使用es是为了提高查询的效率的,所以es提供了相应的控制器方法供我们调用。es也有数据库那味儿,我们搜索的数据也会进行相应的存储,而存储是放在硬盘上的,他的核心搜索功能来自于Java的一个叫Lucene的API,es在Lucene的基础上开发出了一个功能全面的开箱即用的全文搜索引擎。
和es具有相同功能的软件还有Solr和MongoDB。
为什么要使用es?
说起来,数据库并不算Java的专属,同样的es也不是。我们目前所使用的数据库,如mysql,mariaDB,oracle等,都是关系型数据库,而关系型数据库都有一个致命缺点:前模糊的模糊查询不能使用索引。这就麻烦了,如果白百万乃至千万级的数据搜索一条前模糊数据,等个10s,20s的,那谁能受的了?就说淘宝京东之流,我们搜索数据在网络没问题的情况下,从来没超过3s吧?甚至有的1s内就出来了,这就是es的能力,使用它优化后的相同查询,效率能提高100倍,可怕,所以再大型的数据查询也能控制在毫秒级别,这就相当可观了。
所以,还需要继续说下去吗?详细你已经知道es的能力,那就准备在项目里用起来吧。
es查询的原理?
吃面不吃蒜,味道少一半。知道什么是es和为什么使用es之后,我们还需要了解es的查询机制,来了解它为什么这么快?为什么呢?我们来看看。
在使用查询时,如果不使用es,选择数据库查询,若是有索引的加持,还好,但若是没有索引,或者查询的内容是开头的部分,那数据库就有些无能为力了,只能使用低效的全表查询,性能非常差。
而使用es,它可以利用添加数据库完成数据的分词倒排索引,形成一个庞大的索引库,在查询时,通过索引库就可以得到符合条件的数据,我们可以认为es是一本书,索引库就是页码,这样就大大缩小了查询的范围。
下面我们通过一个案例来说明:
数据库存储的可能会进行搜索的内容表:
| id | 内容 |
| 1 | 斗战胜佛孙悟空 |
| 2 | 齐天大圣孙悟空 |
| 3 | 花果山水帘洞美猴王孙悟空 |
| 4 | .......... |
分词库 :
| 分词id | 分词 | 对应id |
| 1 | 斗战胜佛 | 1 |
| 2 | 齐天大圣 | 2 |
| 3 | 花果山 | 3 |
| 4 | 水帘洞 | 3 |
| 5 | 美猴王 | 3 |
| 6 | 孙悟空 | 1,2,3 |
看明白了吗?分词库就是一个索引的作用,他会对应你要搜索的这个分词所对应的可能存在的所有的内容的id,这样就像是一本书了。
此处内容需要理解,若是需要了解数据库的数据结构和索引相关的内容,可以移步:
Java开发 - 数据库中的基本数据结构
Java开发 - 数据库索引的数据结构
es需要准备什么?
官网地址:下载 Elastic 产品 | Elastic
官方在c站也有自己的博客,地址:Elasticsearch 简介_Elastic 中国社区官方博客的博客-CSDN博客
内容也很多,大家也可以自己去看看里面的内容。对于es,不算是经常使用,因为很多公司,很多项目根本用不到这玩意,量级都没有达到,这才是最尴尬的事情。请大家自行下载一个7.x的版本,地址:es下载
博主这里是Mac版本,Windows版本也差不多,在bin文件夹下:
Windows双击运行elasticsearch.bat文件,Mac需要在控制台,先进入bin目录,接着输入:
./elasticsearch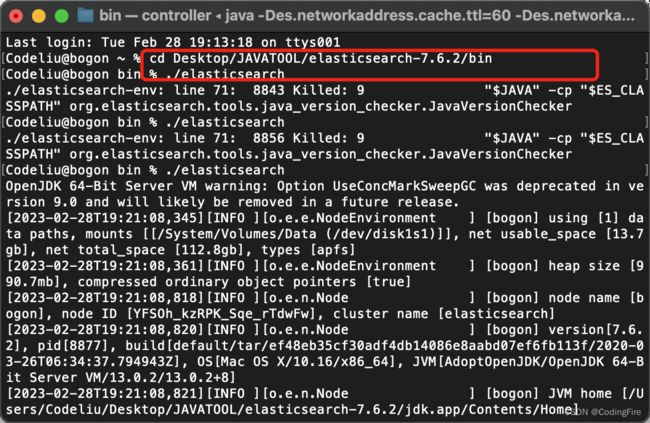
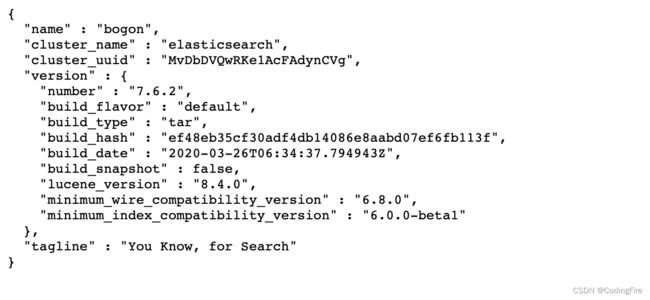
期间会多次弹出不明开发者app的提示,隐私中允许打开,启动需要花费几十秒,等看到窗口有started字样,就地阿彪启动成功了,此时可在浏览器输入以下URL判断是否启动成功:localhost:9200
浏览器返回如下数据则表示启动成功:
es基本用法
其实对于es,我是很不想讲的,它的内容很复杂,操作起来也不简单,和注册nacos这些比起来要麻烦,我也不敢说自己能玩得转es,但微服务已经讲了,箭在弦不得不发,我就献丑了。
前面我们已经启动了es,这是一个好的开头,接下来我们来学习如何使用es。这需要我们先建一个es的工程。这个工程还存在于我们上一篇的微服务的工程中,没看上一篇的同学可以选择接着看,也可以先去看微服务。
创建工程
添加依赖
在添加依赖之前,search工程也需要在主工程中父子相认:
cloud-commons cloud-bussiness cloud-cart cloud-order cloud-stock gateway search
接着search工程的pom文件夹内容如下:
4.0.0 com.codingfire cloud 0.0.1-SNAPSHOT com.codingfire search 0.0.1-SNAPSHOT search Demo project for Spring Boot org.springframework.boot spring-boot-starter
创建操作es的文件
在这里,要专门创建一个用于操作es的文件,主要是用来发送各种类型请求。下面跟着博主一起动手:
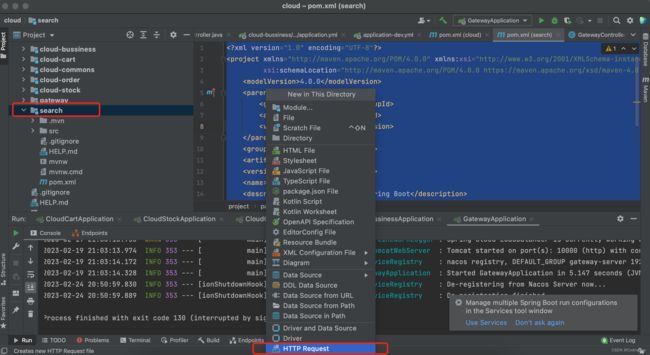
选中search,新建,最下方HTTP Request,就叫es.http,默认是http的后缀,此文件也被称为http client,client是客户端的意思,也就说这个文件可以发送请求,不局限于get和post。
创建完之后,我们来向es发送请求:
### 注释和分隔符,每次编写请求前,都要先编写3个#
GET http://localhost:9200 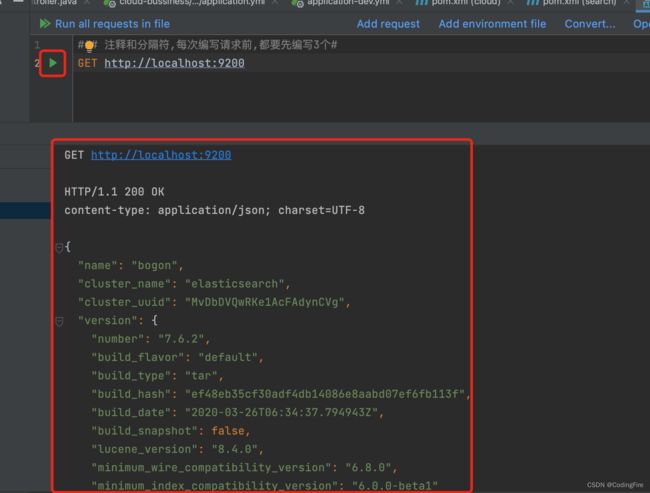
点击运行按钮,显示和浏览器内一致就就说明当前文件正常运行。
接着我们来写分词测试:
### ES分词测试 analyze(分析)
POST http://localhost:9200/_analyze
Content-Type: application/json
{
"text": "齐天大圣孙悟空",
"analyzer": "standard"
}运行测试结果,看看会将“齐天大圣孙悟空”分解成什么样的分词:
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "齐",
"start_offset": 0,
"end_offset": 1,
"type": "",
"position": 0
},
{
"token": "天",
"start_offset": 1,
"end_offset": 2,
"type": "",
"position": 1
},
{
"token": "大",
"start_offset": 2,
"end_offset": 3,
"type": "",
"position": 2
},
{
"token": "圣",
"start_offset": 3,
"end_offset": 4,
"type": "",
"position": 3
},
{
"token": "孙",
"start_offset": 4,
"end_offset": 5,
"type": "",
"position": 4
},
{
"token": "悟",
"start_offset": 5,
"end_offset": 6,
"type": "",
"position": 5
},
{
"token": "空",
"start_offset": 6,
"end_offset": 7,
"type": "",
"position": 6
}
]
}
Response code: 200 (OK); Time: 178ms; Content length: 586 bytes
我们发现,它直接将每一个字做了分词,这好像不是很友好?这是因为standard是默认分词器,规则就是按照一个字是一个词的方式,这就没有意义了。不不,不能这么说,这个分词器对英文还是很友好的,不信你可以试试。
使用ik分词插件
为了解决中文的分词问题,我们需要使用开源的分词词库IK实现中文分词,下载地址:ik
下载完成后,在es文件夹下:
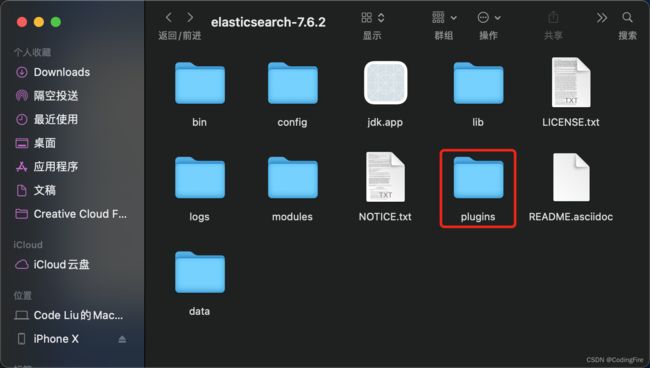
在plugins文件夹下新建一个文件名叫ik,然后将下载的ik文件夹下的所有文件复制到plugin下的ik文件下:
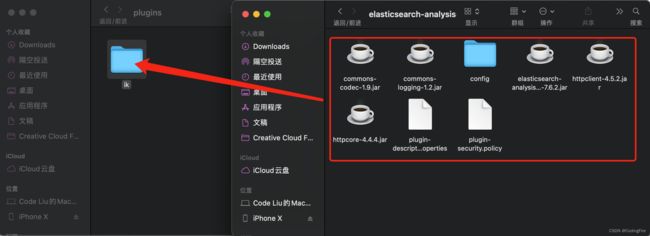
接着重启es,重启后ik插件才能生效。关闭窗口即可关闭es,然后按照上面所说的方法启动。
接着修改analyzer的值如下:
{
"text": "齐天大圣孙悟空",
"analyzer": "ik_smart"
}在此运行,我们看看中文的分词怎么样:
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "齐天大圣",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "孙悟空",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 1
}
]
}
Response code: 200 (OK); Time: 2902ms; Content length: 169 bytes
现在是我们想要的了 ,如果还想分的更细一点,该怎么办呢,修改analyzer的值如下:
{
"text": "齐天大圣孙悟空",
"analyzer": "ik_max_word"
}接着运行看看新的分词是什么样的:
POST http://localhost:9200/_analyze
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
{
"tokens": [
{
"token": "齐天大圣",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "齐天大",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "齐天",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "天大圣",
"start_offset": 1,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "天大",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 4
},
{
"token": "大圣",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "孙悟空",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "悟空",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 7
}
]
}
Response code: 200 (OK); Time: 101ms; Content length: 633 bytes
发现分词更细了,实际开发中,用户不可能按照我们想让他们使用的分词进行搜索,所以就需要将词分的的特别细一些,这也将会导致占用的存储空间比较大,所以使用中还是要按照自己的需求进行分词。
分词器不止ik,你也可以选择其他的分词器。
Spring Data
Spring Data是Spring提供的一套连接各种第三方数据源的框架集,因为在ES的原生状态下,我们java代码需要使用socket访问ES过于繁琐,SpringData框架则可以简化这一步骤。
官网:Spring Data
老外的网站嘛,英文,你懂的,就不是很友好,不过别怕,博主带你操作Spring Data。
项目中引入Spring Data
添加依赖
总是少不了这一步的,在search的工程下pom文件夹添加下面两个依赖:
org.springframework.boot spring-boot-starter-data-elasticsearch org.springframework.boot spring-boot-starter-test
上面的依赖是Spring Data操作es的依赖,下面的测试依赖则用于稍后的测试。
添加配置
接着在application.properties添加配置,此处也可修改为yml,规则大家应该都已经知道了,我就不在细说。添加如下配置:
创建操作es的业务逻辑
创建数据模型
在search下创建entity包,创建People类:
package com.codingfire.search.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
@Data
@Accessors(chain = true) // 生成和链式赋值的set方法
@AllArgsConstructor // 自动生成包含全部参数的构造方法
@NoArgsConstructor // 自动生成无参构造方法
// SpringData要求我们在"实体类"中使用特定注解标记
// @Document注解标记当前类和ES关联
// indexName指定索引名称,我们这里叫peoples,当操作这个索引时,如果索引不存在,会自动创建
@Document(indexName = "peoples")
public class People implements Serializable {
// SpingData标记这个字段为当前类主键
@Id
private Long id;
// SpringData使用@Field标记文档中属性的类型和各种特征
@Field(type = FieldType.Text,
analyzer = "ik_max_word",
searchAnalyzer = "ik_max_word")
private String name; //全名
@Field(type = FieldType.Keyword)
private String bigName; //最厉害的称号
@Field(type = FieldType.Keyword)
private String home; //家乡
@Field(type = FieldType.Double)
private Double brave; //战力
// 图片地址不会称为搜索条件,所以设置index=false
// 效果是imgPath字段不会生成索引库,节省空间
@Field(type = FieldType.Keyword,index = false)
private String imgPath; //画像
// Text和Keyword都是字符串类型,只是Text会分词,而Keyword不会!
}
创建持久层
在search下创建repository包,在包中创建接口PeopleRepository接口类 :
package com.codingfire.search.repository;
import com.codingfire.search.entity.People;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
// Spring 家族下持久层名称都叫repository,mybatis我们都叫mapper
@Repository
public interface PeopleRepository extends ElasticsearchRepository {
} 当前接口继承ElasticsearchRepository父接口后会自动在类中生成基本的增删改查方法,可直接使用。 它自动识别或自动生成的规则,是我们定义的两个泛型ElasticsearchRepository<[实体类名],[主键类型]>。
测试
刚刚已经引入了测试的依赖,下面我们就在测试类SearchApplicationTests内进行测试。
package com.codingfire.search;
import com.codingfire.search.entity.People;
import com.codingfire.search.repository.PeopleRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class SearchApplicationTests {
// 注入SpringData操作Es的持久层对象
@Autowired
private PeopleRepository peopleRepository;
//单增
@Test
void addOne() {
People item=new People()
.setId(1L)
.setName("花果山水帘洞齐天大圣孙悟空")
.setBigName("斗战胜佛")
.setHome("花果山")
.setBrave(10000.0)
.setImgPath("/s.jpg");
// 利用自动生成的方法将item新增到ES,索引不存在会自动创建
peopleRepository.save(item);
System.out.println("ok");
}
}
先新增一个对象到es,运行测试方法:
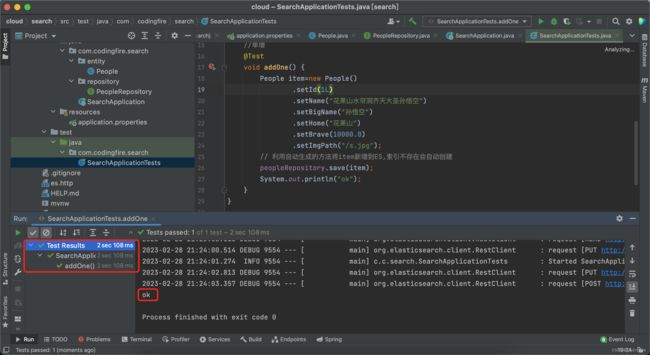
测试成功。接着我们去查询新增的对象:
// 按id查询
@Test
void getOne(){
// SpringData框架自带的按id查询的方法
// Optional是一个类似包装类的概念,查询的结果封装到了这个类型中
Optional optional=peopleRepository.findById(1L);
// 需要使用查询内容时使用optional.get()即可
System.out.println(optional.get());
} 运行代码,看看是否能输出我们新增加的对象信息:
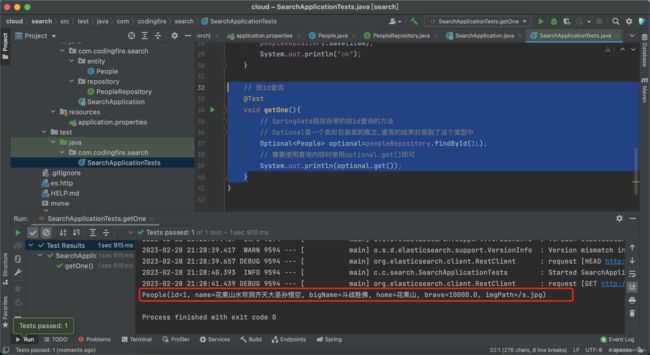
可以看到人物信息已经返回。测试成功。
有时候我们可能需要批量增加到es中,这时候就涉及到批量增和一次性全查:
@Test
void addList(){
// 实例化一个List集合
List list=new ArrayList<>();
// 将要新增的Item对象保存到这个List中
list.add(new People(2L,"大唐三藏法师唐三藏","旃檀功德佛",
"大唐",0.0,"/t.jpg"));
list.add(new People(3L,"天蓬元帅猪八戒","净坛使者",
"高老庄",5000.0,"/z.jpg"));
list.add(new People(4L,"卷帘大将沙和尚","金身罗汉",
"流沙河",3000.0,"/s.jpg"));
// 下面使用SpringData提供的方法执行批量新增
peopleRepository.saveAll(list);
System.out.println("ok");
}
// 全查
@Test
void getAll(){
// 利用SpringData的方法从ES中查询所有数据
Iterable items=peopleRepository.findAll();
items.forEach(item -> System.out.println(item));
} 分别运行批量增和批量查询方法,博主这里是成功的,不知道你那里成功了吗?
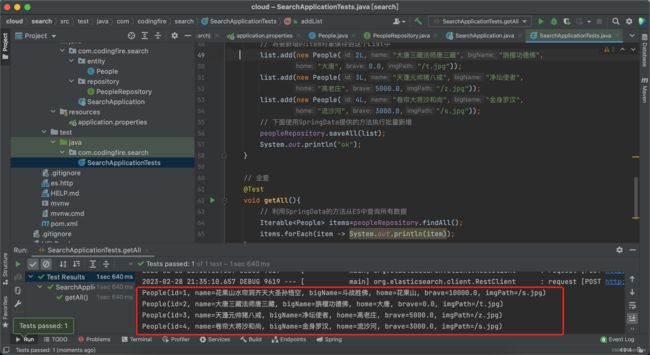
如果你是按照博主的代码复制的,到此你应该是成功了,如有问题,可查看是否和博主的配置和目录一样。
自定义查询
了解了固定的查询套路,那么我们不想按照上面的方式做,该怎么办呢?这时候就要用到自定义查询了,毕竟没有哪家公司的需求是完全相同的,自定义查询时一定会用的,接下来就来说说自己怎么来定义es的查询。
和数据库查询一样,es查询也分为多条件查询和单条件查询,下面一起来看看吧。
单条件查询
如果是数据库查询,我们查询name中包含“佛”的对象有谁:
select * from xxxxxx where big_name like '%佛'
使用es,实际就是使用es.http文档中编写的查询语句,而在Spring Data的加持下,编写查询语句更为简单。
在PeopleRepository接口中添加如下代码:
// SpringData自定义查询
// 遵循SpringData框架规定的格式的前提下,编写方法名会自动生成查询逻辑
// query: 表示当前方法是一个查询功能,类似sql中的select
// Item\Items: 表示查询结果的实体类,带s的返回集合
// By:标识开始设置条件,类似sql的where
// bigName: 要查询的字段名称
// Matches: 是要执行的查询操作,这里是分词查询,类似sql的like
Iterable queryItemsByBigNameMatches(String bigName); 这段代码是有固定格式的,写的时候要格外注意了,当然,里面有提示,所以一般不会写错。
等下,这样查很可能查不到,因为只有一个字,为了效果,我们在所有的name前都加上“西游”俩字,接着修改查询方法如下:
Iterable queryItemsByNameMatches(String name);
接着在测试类中测试上面这段代码即可:
//单条件自定义查询
@Test
void queryOne(){
// 查询 ES中title字段包含"西游"分词的数据
Iterable items=peopleRepository.queryItemsByNameMatches("西游");
items.forEach(item -> System.out.println(item));
} 修改完后记得重新运行添加方法,接着再运行此查询方法,我们查name中有西游俩字的人的信息:
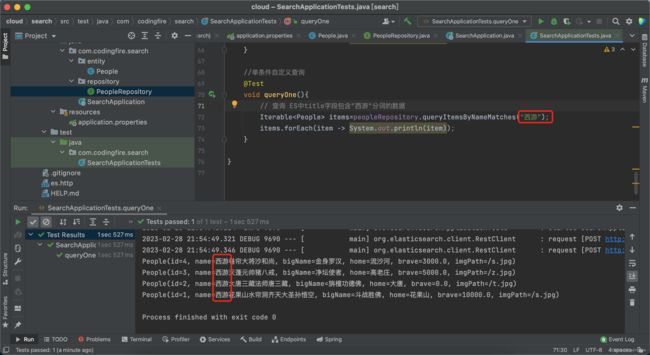
很好,查询成功。
单条件底层查询语句:
### 单条件搜索
POST http://localhost:9200/peoples/_search
Content-Type: application/json
{
"query": {"match": { "name": "西游" }}
}可以贴入http文件进行验证。
多条件查询
但有时候,我们为了精准的找到目标,可能会采用多条件查询的方式,我们添加多条件查询的方法如下:
// 多条件查询
// 两个或多个条件之间直接编写And或Or表示查询逻辑
// 参数名称实际上没有要求必须和字段名称匹配,底层代码是按照参数顺序赋值的
Iterable queryItemsByNameMatchesAndBigNameMatches(String name,String bigName); 多条件用And或Or来连接。
接着,我们在测试方法中进行测试:
// 多条件自定义查询
@Test
void queryTwo(){
Iterable items=peopleRepository
.queryItemsByNameMatchesAndBigNameMatches("西游","斗战胜佛");
items.forEach(item -> System.out.println(item));
} 运行测试代码查看结果:
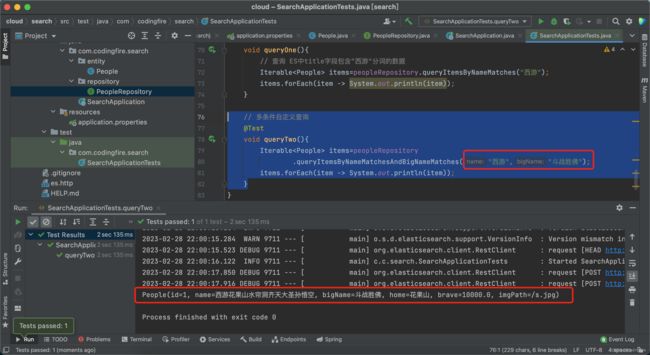
这就是我们存入的数据,测试成功。
多条件底层查询语句:
### 多字段搜索
POST http://localhost:9200/peoples/_search
Content-Type: application/json
{
"query": {
"bool": {
"must": [
{ "match": { "name": "西游"}},
{ "match": { "bigName": "斗战胜佛"}}
]
}
}
}可以贴入http文件进行验证。
对了,还需注意一点,当查询条件为And时,查询语句关键字为must;当查询条件为Or时,查询语句关键字为should。
结语
以上的操作,请务必保证es是运行状态。写到这里,本篇es相关内容就要跟大家说再见了,整体内容我个人还算是满意,基本算是讲清楚了es的使用,即使是在真实项目中用法也不过就是如此,但是关于一些配置啊,服务器方面,还是要看各公司自己的情况来决定,业务相关的部分,这里的代码足以应付,那么,你学会了吗?码文不易,且行且珍惜,觉得有用,就收藏点赞+评论吧。