YOLO v5 代码解读及训练、测试实操
YOLO v5 代码解读及训练、测试实操
带你了解YOLO v5代码,尽可能做的详细一点
文章目录
- YOLO v5 代码解读及训练、测试实操
- 前言
- 一、模型训练前期准备
- 二、正式训练
-
- 1.输入参数
- 2.正式训练
- 3、推理、检测
- 代码中涉及技术原理
前言
YOLO v4和v5几乎差不多时间出世,有人觉得Ultralytics装了波逼,v5称不上v4的下一个版本,但当你仔细研读一下代码,并且亲自尝试一下后会发现代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴,而且作为工业落地应用有很大的借鉴性。综合对比v4和v5,v5的性能会比v4偏低点,但在灵活性与速度上远强于YOLO V4,在模型的快速部署上具有极强优势。
下面开始正式解读一下吧
一、模型训练前期准备
第一步肯定是数据集的准备,正常的图像标注软件(labelimg、labelme、精灵)都可,生成xml文件,但xml文件并不是最终喂入模型的数据,需要转换成适合的txt文件(具体代码见博主之前的博文:https://blog.csdn.net/weixin_43337201/article/details/109102429),最终模型需要的两部分:images、labels,我们放到两个文件夹下,同时你可以分为训练集和测试集。

第二步,准备一下你的yaml文件,参照coco.yaml进行改造的score.yaml:
#训练集/测试集路径
train: yolov5/dataset/images/train/
test: yolov5/dataset/images/test/
# number of classes
nc: 20
# class names
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
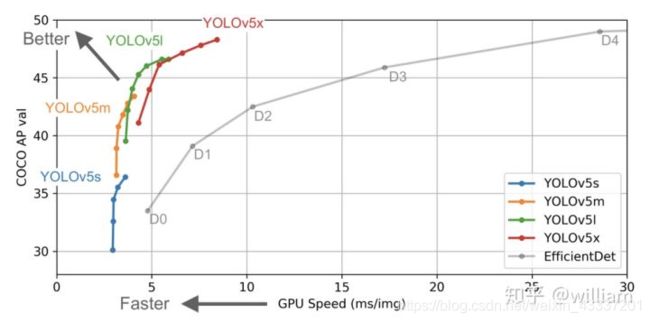
第三步,由于YOLO v5分为x/l/m/s四个模型,相应地就存在四个预训练的权重文件,从下图可以看出来,从x到s,性能越来好,但速度越来越慢。确定选定那个模型后记得去起对应的yaml文件下改一下nc的值成你自定义数据的类别数即可,yaml文件的位置是models/yolov5x.yaml,
二、正式训练
1.输入参数
参数传入部分:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5x.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5x.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/score.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--logdir', type=str, default='runs/', help='logging directory')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
opt = parser.parse_args()
这里面其实只有几个地方需要注意一下:--weights指的训练所需的预权重,在weights/download_weights.sh提供了下载途径,直接sh weights/download_weights.sh即可下载;--cfg就是我们之前改过的yolov5x.yaml文件,--data指的我们要喂入的数据,在score.yaml中指定了训练集、测试集的位置、分类的类别数及各类别名称,其他的像epochs等参数可以直接默认设置,--device设置是使用cpu还是gpu进行训练,default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu'
2.正式训练
pip -r install requirment.txt装好依赖库以后,再装好torch以后就直接训练即可
python train.py
ps:装依赖的时候正常肯定是conda搞个虚拟环境,其实在docker上装库运行啥的更好。
训练会打印实时的训练日志,跑完所有epochs以后你会得到你需要的权重文件作为后续测试或者推理的模型依据。

3、推理、检测
detect.py提供推理函数,稍加修改可以实现单张图片、批量图片、视频的检测,可以可视化地看到模型的性能。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5/runs/exp0/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.7, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='0,1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
opt = parser.parse_args()
--weights指的通过训练得到的权重文件best.pt,--source指的需要推理的图片的文件夹位置,--output是推理完的图片并画上目标框以后的图片文件夹位置,--conf-thres设置阈值,当score大于conf-thres,才会呈现目标框,--iou-thres表示iou的阈值,其余参数默认即可,--device设置是使用cpu还是gpu进行训练,default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu'
代码中涉及技术原理
参照博主之前博客:yolov5代码解读中遇到的原理性问题解决
未完待续,有其他疑问请在评论区提出