银行客户流失分析预测
客户流失意味着客户终止了和银行的各项业务,毫无疑问,一定量的客户流失会给银行带来巨大损失。考虑到避免一位客户流失的成本很可能远低于挖掘一位新客户,因此对客户流失情况的分析预测至关重要。本文分析了某银行10000条客户信息,含14个字段,接下来我们将从这些数据中探索客户流失特征和原因,推测目前客户管理、业务等方面可能存在的问题,建立预测模型预警客户流失情况,为制定挽留策略提供依据。
1. 探索性分析
1.1 认识字段
首先,初步了解下这些数据。
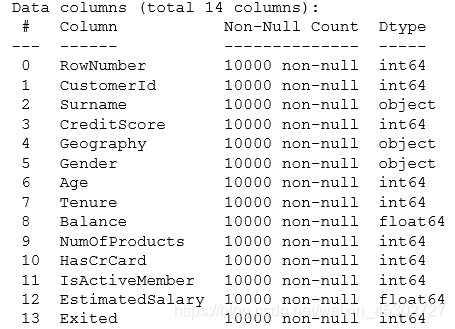
字段依次表示行号、客户Id、姓氏、信用积分、地理位置、性别、年龄、开户时长、账户余额、产品数量、有无信用卡、是否活跃、收入估计、是否流失(即目标变量)。为了便于后续处理,对字段重新排列,将目标变量放在首列,并去除无用字段。显然其中行号、客户Id、姓氏对流失情况的分析预测意义不大,可以忽略,其余字段可分为分类变量和数值变量,在数据处理环节再做变换等操作。另外,剔除少量异常数据。
1.2 流失率与分类变量
从数据中不难得知流失率为20.4%,接下来先对分类变量做初步探索,为了便于观察流失占比,这里采用饼图,饼图大小代表用户数量,橙、蓝分别代表流失、留存用户:
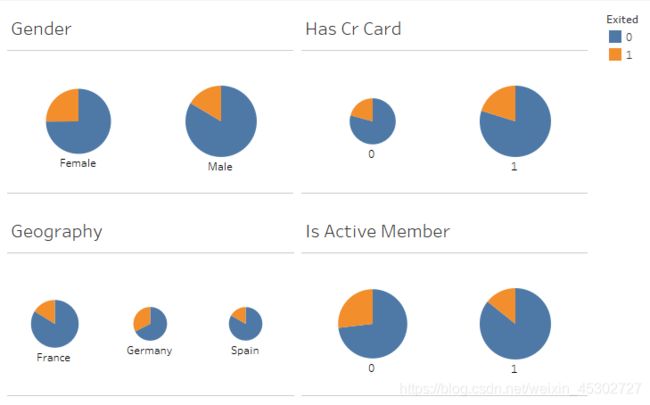
按性别分,女性用户少于男性用户数量,但流失率更高。建议银行提升女性的用户体验,考虑到女性消费能力很强,可以考虑和商家联手推出倾向女性顾客的优惠活动。按有无信用卡分,有信用卡者明显居多,有信用卡的两类群体中流失率略低。按国家分,法国用户数量最多,德国用户与西班牙用户数量相近,但德国用户流失率远高于其他两国,建议对德国的客户管理情况做进一步深入调研。按照活跃度分,不活跃用户流失率远高于活跃用户,因此活跃度是个需要重点关注和提升的指标。
1.3 流失率与数值变量
下面继续观察下数值变量的分布情况,如图:
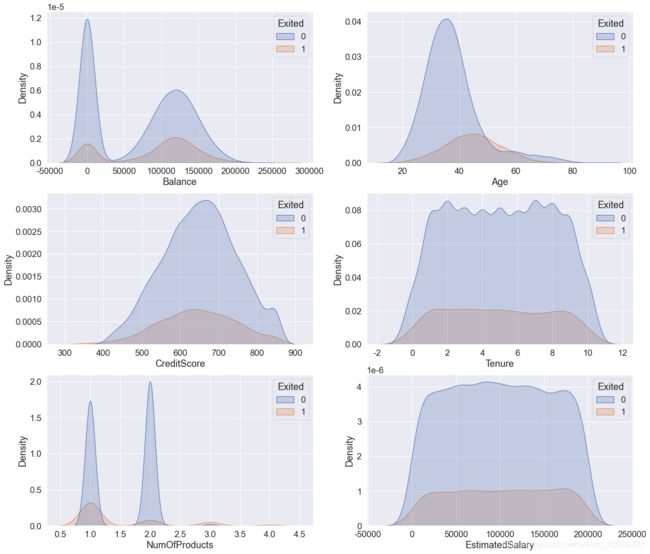
从账户余额看,余额在10万-15万之间的较高余额用户流失率很高,这势必会对银行业务造成不小损失,值得重点关注。从年龄看,用户多分布在年龄在25-50岁之间,年龄较长的客户(45-65岁)流失率非常高,因而在采取挽留策略时需要视不同的年龄划分而定。从信用积分看,信用积分分布在600-700分之间的客户最多,流失的客户数量也最多。从开户时长看,用户的开户时长主要为1-9年,且开户1-9年的这些客户开户时长频数分布比较均匀,流失率没有明显差异;然而开户时间短于1年或者高于9年的用户有更高的流失风险,可以考虑优化新客户的开发和挽留策略。从产品数量看,拥有产品数为1、2的客户数量最多,且有2个产品的用户流失率低于拥有1个产品的用户,可以考虑提升产品的吸引力,增强用户黏度。从收入看,用户收入多在2万-18万间,且用户数量和流失率在此区间分布较为均匀,事实上社会中人群的收入分布并不是如此均匀,这表明有大量的潜在客户可以开发。
2.数据处理
2.1 删除字段
前文已提到行号、客户Id、姓氏可以忽略,这里我们将这三个字段剔除。
2.2 新增字段
除了存款和收入,客户将多少比例的收入存到银行同样是个重要的考量参数,因此新增一个特征:存款收入比,即存款/收入。所有客户的存款收入比均大于零,且存款收入比越高,越容易流失。
2.3 处理缺失值、异常值
数据无需处理缺失值,省略。至于异常值不止一两个,且对流失情况预测可能有一定意义,选择暂不处理。
2.4 转换分类变量
分类变量的种类较少,可直接选用独热编码来处理性别和国家,所用函数为pd. get_dummies()。
2.5 归一化数值变量
在归一化数值变量前先随机将80%数据划分为训练集,余下20%为测试集。然后对数值变量分别归一化,变换方法如下:
df_train[col1] = (df_train[col1]-col1_min)/(col1_max-col1_min)
顺便提下,在模型训练时,测试集属于外来数据,应该和训练集完全分开,如果直接对所有数据进行归一化,测试集的数据可能给训练集的特征范围等带来影响,进而影响模型效果。
3. 模型拟合和选取
3.1 模型调用
将目标变量提取出来,命名为y_train, y_test,余下变量则命名为X_train,X_test。采用决策树、KNN近邻、支持向量机(SVM)几种常用的算法训练模型,并选取最优算法。
这里涉及参数多采用sklearn中的默认参数,以简化工作。当然,随着对机器学习的了解深入,可以通过调参、模型融合等方式进一步提升预测效果。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
model = [KNeighborsClassifier(), SVC(), DecisionTreeClassifier()]
model_names = ["KNN", "SVM", "Decision tree"]
for i in range(0, 3):
y_pred = model[i].fit(X_train, y_train).predict(X_test)
accuracy = accuracy_score(y_pred, y_test)*100
print(model_names[i], ":", accuracy, "%")
3.2 最佳预测模型
三种模型在测试集中的预测准确率分别如下:

发现支持向量机SVM模型的效果最好,故选取该模型。对测试集的预测准确率达84.2%,可以推测用该模型对银行客户流失情况预测具有一定准确率,预测结果具备重要的参考价值。
3.3 预测模型意义
银行客户流失情况预测模型的建立,能够给银行业务提供有效的预警。对有流失倾向的客户做出标记,能使银行在客户管理和策略制定上更有针对性,用较低成本实现客户挽留率的改善,减少客户流失带来的损失。