Seq2Seq端到端神经网络介绍
Seq2Seq端到端神经网络介绍
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
- Seq2Seq端到端神经网络介绍
- 前言
- 一、Seq2Seq原理介绍
- 二、Seq2Seq代码实战
-
- 获取encoder的状态输出
- 总结
前言
Seq2Seq技术,全称Sequence to Sequence,该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型(DNNs)运用于翻译与智能问答这一类序列型(Sequence Based,项目间有固定的先后关系)任务的先河,并被证实在机器翻译、对话机器人、语音辨识的应用中有着不俗的表现。下面就详细讲一下其原理和实现。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Seq2Seq原理介绍
传统的Seq2Seq是使用两个循环神经网络,将一个语言序列直接转换到另一个语言序列。是循环神经网络的升级版,其联合了两个循环神经网络。一个神经网络负责接收源句子;另一个循环神经网络负责将句子输出成翻译的语言。这两个过程分别称为编码和解码的过程,如图7.38所示:
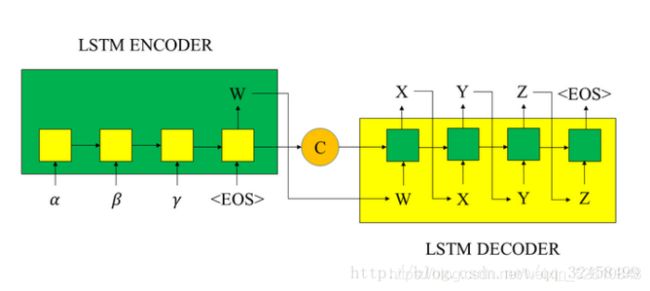
1)编码过程
编码过程实际上使用了循环神经网络记忆的功能,通过上下文的序列关系,将词向量依次输入网络。对于循环神经网络,每一次网络都会输出一个结果,但是编码的不同之处在于,其只保留最后一个隐藏状态,相当于将整句话浓缩在一起,将其存为一个内容向量(context)供后面的解码器(decoder)使用。
2)解码过程
解码和编码网络结构几乎是一样的,唯一不同的是在解码过程中,是根据前面的结果来得到后面的结果。编码过程中输入一句话,这一句话就是一个序列,而且这个序列中的每个词都是已知的,而解码过程相当于什么也不知道,首先需要一个标识符表示一句话的开始,然后接着将其输入网络得到第一个输出作为这句话的第一个词,接着通过得到的第一个词作为网络的下一个输入,得到的输出作为第二个词,不断循环,通过这种方式来得到最后网络输出的一句话。
3)使用序列到序列网络结构的原因
翻译的每句话的输入长度和输出长度一般来讲都是不同的,而序列到序列的网络结构的优势在于不同长度的输入序列能够能到任意长度的输出序列。使用序列到序列的模型,首先将一句话的所有内容压缩成一个内容向量然后通过一个循环网络不断地将内容提取出来,形成一句新的话。
二、Seq2Seq代码实战
了解了Seq2Seq原理和介绍,我们来做一个实践应用,做一个单词的字母排序,比如输入单词是’acbd’,输出单词是’abcd’,要让机器学会这种排序算法,就可以使用seq2seq的模型来完成,接下来我们分析一下核心步骤,最后会给予一个能直接运行的完整代码给大家学习
1) 数据集的准备
这里有两个文件分别是source.txt和target.txt,对应的分别是输入文件和输出文件,代码如下所示:
#读取输入文件
with open(‘data/letters_source.txt’, ‘r’, encoding=‘utf-8’) as f:
source_data = f.read()
#读取输出文件
with open(‘data/letters_target.txt’, ‘r’, encoding=‘utf-8’) as f:
target_data = f.read()
2) 数据集的预处理
填充序列,序列字符和ID的转换,代码如下所示:
#数据预处理
def extract_character_vocab(data):
使用特定的字符进行序列的填充
special_words = [’’, ‘’, ‘’, ‘’]
set_words = list(set([character for line in data.split(’\n’) for character in line]))
#这里要把四个特殊字符添加进词典
int_to_vocab = {idx: word for idx, word in enumerate(special_words + set_words)}
vocab_to_int = {word: idx for idx, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
source_int_to_letter, source_letter_to_int = extract_character_vocab(source_data)
target_int_to_letter, target_letter_to_int = extract_character_vocab(target_data)
#对字母进行转换
source_int = [[source_letter_to_int.get(letter, source_letter_to_int[’’])
for letter in line] for line in source_data.split(’\n’)]
target_int = [[target_letter_to_int.get(letter, target_letter_to_int[’’])
for letter in line] + [target_letter_to_int[’’]] for line in target_data.split(’\n’)]
print(‘source_int_head’,source_int[:10])
填充字符含义:
< PAD>: 补全字符。
< EOS>: 解码器端的句子结束标识符。
< UNK>: 低频词或者一些未遇到过的词等。
< GO>: 解码器端的句子起始标识符。
3) 创建编码层
创建编码层代码如下所示:
#创建编码层
def get_encoder_layer(input_data, rnn_size, num_layers,source_sequence_length, source_vocab_size,encoding_embedding_size):
#Encoder embedding
encoder_embed_input = layer.embed_sequence(ids=input_data, vocab_size=source_vocab_size,embed_dim=encoding_embedding_size)
RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
指定多个lstm
cell = rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
#返回output,state
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell=cell, inputs=encoder_embed_input,sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
参数变量含义:
-
input_data: 输入tensor
-
rnn_size: rnn隐层结点数量
-
num_layers: 堆叠的rnn cell数量
-
source_sequence_length: 源数据的序列长度
-
source_vocab_size: 源数据的词典大小
-
encoding_embedding_size: embedding的大小
4) 创建解码层
对编码之后的字符串进行处理,去除最后一个没用的字符串,代码如下所示:
#对编码数据进行处理,移除最后一个字符
def process_decoder_input(data, vocab_to_int, batch_size):
‘’’
补充,并移除最后一个字符
‘’’
#cut掉最后一个字符
ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1])
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int[’’]), ending], 1)
return decoder_input
创建解码层代码如下所示:
#创建解码层
def decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers, rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state, decoder_input):
#1 构建向量
#目标词汇的长度
target_vocab_size = len(target_letter_to_int)
#定义解码向量的维度大小
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
#解码之后向量的输出
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
- 构造Decoder中的RNN单元
def get_decoder_cell(rnn_size):
decoder_cell = rnn.LSTMCell(num_units=rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
#3. Output全连接层
output_layer = Dense(units=target_vocab_size,kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
#4. Training decoder
with tf.variable_scope(“decode”):
#得到help对象
training_helper = seq2seq.TrainingHelper(inputs=decoder_embed_input,sequence_length=target_sequence_length,time_major=False)
#构造decoder
training_decoder = seq2seq.BasicDecoder(cell=cell,helper=training_helper,initial_state=encoder_state,output_layer=output_layer)
training_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length)
- Predicting decoder
#与training共享参数
with tf.variable_scope(“decode”, reuse=True):
#创建一个常量tensor并复制为batch_size的大小
start_tokens = tf.tile(tf.constant([target_letter_to_int[’’]], dtype=tf.int32), [batch_size],name=‘start_tokens’)
predicting_helper = seq2seq.GreedyEmbeddingHelper(decoder_embeddings,start_tokens,target_letter_to_int[’’])
predicting_decoder = seq2seq.BasicDecoder(cell=cell,helper=predicting_helper,initial_state=encoder_state,output_layer=output_layer)
predicting_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=predicting_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length)
return training_decoder_output, predicting_decoder_output
在构建解码这一块使用到了,参数共享机制 tf.variable_scope(""),方法参数含义:
-
target_letter_to_int: target数据的映射表
-
decoding_embedding_size: embed向量大小
-
num_layers: 堆叠的RNN单元数量
-
rnn_size: RNN单元的隐层结点数量
-
target_sequence_length: target数据序列长度
-
max_target_sequence_length: target数据序列最大长度
-
encoder_state: encoder端编码的状态向
-
decoder_input: decoder端输入
5)构建seq2seq模型
把解码和编码串在一起,代码如下所示:
#构建序列模型
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
encoder_embedding_size, decoder_embedding_size,
rnn_size, num_layers):
获取encoder的状态输出
_, encoder_state = get_encoder_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
#预处理后的decoder输入
decoder_input = process_decoder_input(targets, target_letter_to_int, batch_size)
#将状态向量与输入传递给decoder
training_decoder_output, predicting_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state,
decoder_input)
return training_decoder_output, predicting_decoder_output
6)创建模型输入参数
创建模型输入参数代码如下所示:
#创建模型输入参数
def get_inputs():
inputs = tf.placeholder(tf.int32, [None, None], name=‘inputs’)
targets = tf.placeholder(tf.int32, [None, None], name=‘targets’)
learning_rate = tf.placeholder(tf.float32, name=‘learning_rate’)
#定义target序列最大长度(之后target_sequence_length和source_sequence_length会作为feed_dict的参数)
target_sequence_length = tf.placeholder(tf.int32, (None,), name=‘target_sequence_length’)
max_target_sequence_length = tf.reduce_max(target_sequence_length, name=‘max_target_len’)
source_sequence_length = tf.placeholder(tf.int32, (None,), name=‘source_sequence_length’)
return inputs, targets, learning_rate, target_sequence_length, max_target_sequence_length, source_sequence_length
7)训练数据准备和生成
数据填充代码如下所示:
#对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length
def pad_sentence_batch(sentence_batch, pad_int):
‘’’
参数:
-
sentence batch
-
pad_int: 对应索引号
‘’’
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
批量数据获取代码如下所示:
#批量数据生成
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
‘’’
定义生成器,用来获取batch
‘’’
for batch_i in range(0, len(sources) // batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
#补全序列
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
记录每条记录的长度
pad_targets_lengths = []
for target in pad_targets_batch:
pad_targets_lengths.append(len(target))
pad_source_lengths = []
for source in pad_sources_batch:
pad_source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
到此核心步骤基本上就分析完了,最后还剩训练和预测,如代码7.3所示:
【代码7.3】 seq2seq.py
#-- coding: utf-8 --
#description train seq2seq model for sort word of key
from tensorflow.python.layers.core import Dense
import numpy as np
import time
import tensorflow as tf
import tensorflow.contrib.layers as layer
import tensorflow.contrib.rnn as rnn
import tensorflow.contrib.seq2seq as seq2seq
#读取输入文件
with open(‘data/letters_source.txt’, ‘r’, encoding=‘utf-8’) as f:
source_data = f.read()
#读取输出文件
with open(‘data/letters_target.txt’, ‘r’, encoding=‘utf-8’) as f:
target_data = f.read()
print(‘source_data_head’,source_data.split(’\n’)[:10])
#数据预处理
def extract_character_vocab(data):
#使用特定的字符进行序列的填充
special_words = [’’, ‘’, ‘’, ‘’]
set_words = list(set([character for line in data.split(’\n’) for character in line]))
#这里要把四个特殊字符添加进词典
int_to_vocab = {idx: word for idx, word in enumerate(special_words + set_words)}
vocab_to_int = {word: idx for idx, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
source_int_to_letter, source_letter_to_int = extract_character_vocab(source_data)
target_int_to_letter, target_letter_to_int = extract_character_vocab(target_data)
#对字母进行转换
source_int = [[source_letter_to_int.get(letter, source_letter_to_int[’’])
for letter in line] for line in source_data.split(’\n’)]
target_int = [[target_letter_to_int.get(letter, target_letter_to_int[’’])
for letter in line] + [target_letter_to_int[’’]] for line in target_data.split(’\n’)]
print(‘source_int_head’,source_int[:10])
创建模型输入参数
def get_inputs():
inputs = tf.placeholder(tf.int32, [None, None], name=‘inputs’)
targets = tf.placeholder(tf.int32, [None, None], name=‘targets’)
learning_rate = tf.placeholder(tf.float32, name=‘learning_rate’)
#定义target序列最大长度(之后target_sequence_length和source_sequence_length会作为feed_dict的参数)
target_sequence_length = tf.placeholder(tf.int32, (None,), name=‘target_sequence_length’)
max_target_sequence_length = tf.reduce_max(target_sequence_length, name=‘max_target_len’)
source_sequence_length = tf.placeholder(tf.int32, (None,), name=‘source_sequence_length’)
return inputs, targets, learning_rate, target_sequence_length, max_target_sequence_length, source_sequence_length
‘’’
构造Encoder层
参数说明:
-
input_data: 输入tensor
-
rnn_size: rnn隐层结点数量
-
num_layers: 堆叠的rnn cell数量
-
source_sequence_length: 源数据的序列长度
-
source_vocab_size: 源数据的词典大小
-
encoding_embedding_size: embedding的大小
‘’’
#创建编码层
def get_encoder_layer(input_data, rnn_size, num_layers,source_sequence_length, source_vocab_size,encoding_embedding_size):
#Encoder embedding
encoder_embed_input = layer.embed_sequence(ids=input_data, vocab_size=source_vocab_size,embed_dim=encoding_embedding_size)
#RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
#指定多个lstm
cell = rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
#返回output,state
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell=cell, inputs=encoder_embed_input,sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
#对编码数据进行处理,移除最后一个字符
def process_decoder_input(data, vocab_to_int, batch_size):
‘’’
补充,并移除最后一个字符
‘’’
#cut掉最后一个字符
ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1])
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int[’’]), ending], 1)
return decoder_input
‘’’
构造Decoder层
参数:
-
target_letter_to_int: target数据的映射表
-
decoding_embedding_size: embed向量大小
-
num_layers: 堆叠的RNN单元数量
-
rnn_size: RNN单元的隐层结点数量
-
target_sequence_length: target数据序列长度
-
max_target_sequence_length: target数据序列最大长度
-
encoder_state: encoder端编码的状态向量
-
decoder_input: decoder端输入
‘’’
#创建解码层
def decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers, rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state, decoder_input):
#1 构建向量
目标词汇的长度
target_vocab_size = len(target_letter_to_int)
#定义解码向量的维度大小
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
#解码之后向量的输出
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
#2. 构造Decoder中的RNN单元
def get_decoder_cell(rnn_size):
decoder_cell = rnn.LSTMCell(num_units=rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
#3. Output全连接层
output_layer = Dense(units=target_vocab_size,kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
#4. Training decoder
with tf.variable_scope(“decode”):
#得到help对象
training_helper = seq2seq.TrainingHelper(inputs=decoder_embed_input,sequence_length=target_sequence_length,time_major=False)
#构造decoder
training_decoder = seq2seq.BasicDecoder(cell=cell,helper=training_helper,initial_state=encoder_state,output_layer=output_layer)
training_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length)
#5. Predicting decoder
#与training共享参数
with tf.variable_scope(“decode”, reuse=True):
#创建一个常量tensor并复制为batch_size的大小
start_tokens = tf.tile(tf.constant([target_letter_to_int[’’]], dtype=tf.int32), [batch_size],name=‘start_tokens’)
predicting_helper = seq2seq.GreedyEmbeddingHelper(decoder_embeddings,start_tokens,target_letter_to_int[’’])
predicting_decoder = seq2seq.BasicDecoder(cell=cell,helper=predicting_helper,initial_state=encoder_state,output_layer=output_layer)
predicting_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=predicting_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length)
return training_decoder_output, predicting_decoder_output
#构建序列模型
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
encoder_embedding_size, decoder_embedding_size,
rnn_size, num_layers):
#获取encoder的状态输出
_, encoder_state = get_encoder_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
#预处理后的decoder输入
decoder_input = process_decoder_input(targets, target_letter_to_int, batch_size)
#将状态向量与输入传递给decoder
training_decoder_output, predicting_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
encoder_state,
decoder_input)
return training_decoder_output, predicting_decoder_output
#超参数
#Number of Epochs
epochs = 60
#Batch Size
batch_size = 128
#RNN Size
rnn_size = 50
#Number of Layers
num_layers = 2
#Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
#Learning Rate
learning_rate = 0.001
#构造graph
train_graph = tf.Graph()
with train_graph.as_default():
#获得模型输入
input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_inputs()
training_decoder_output, predicting_decoder_output = seq2seq_model(input_data,
targets,
lr,
target_sequence_length,
max_target_sequence_length,
source_sequence_length,
len(source_letter_to_int),
len(target_letter_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers)
training_logits = tf.identity(training_decoder_output.rnn_output, ‘logits’)
predicting_logits = tf.identity(predicting_decoder_output.sample_id, name=‘predictions’)
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name=‘masks’)
with tf.name_scope(“optimization”):
#Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
#Optimizer
optimizer = tf.train.AdamOptimizer(lr)
#Gradient Clipping 基于定义的min与max对tesor数据进行截断操作,目的是为了应对梯度爆发或者梯度消失的情况
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
#对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length
def pad_sentence_batch(sentence_batch, pad_int):
‘’’
参数:
-
sentence batch
-
pad_int: 对应索引号
‘’’
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
#批量数据生成
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
‘’’
定义生成器,用来获取batch
‘’’
for batch_i in range(0, len(sources) // batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
#补全序列
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
#记录每条记录的长度
pad_targets_lengths = []
for target in pad_targets_batch:
pad_targets_lengths.append(len(target))
pad_source_lengths = []
for source in pad_sources_batch:
pad_source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
#将数据集分割为train和validation
train_source = source_int[batch_size:]
train_target = target_int[batch_size:]
#留出一个batch进行验证
valid_source = source_int[:batch_size]
valid_target = target_int[:batch_size]
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size,
source_letter_to_int[’’],
target_letter_to_int[’’]))
display_step = 50 # 每隔50轮输出loss
checkpoint = “model/trained_model.ckpt”
#准备训练模型
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(1, epochs + 1):
for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate(
get_batches(train_target, train_source, batch_size,
source_letter_to_int[’’],
target_letter_to_int[’’])):
_, loss = sess.run(
[train_op, cost],
{input_data: sources_batch,
targets: targets_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths})
if batch_i % display_step == 0:
#计算validation loss
validation_loss = sess.run(
[cost],
{input_data: valid_sources_batch,
targets: valid_targets_batch,
lr: learning_rate,
target_sequence_length: valid_targets_lengths,
source_sequence_length: valid_sources_lengths})
print(‘Epoch {:>3}/{} Batch {:>4}/{} - Training Loss: {:>6.3f} - Validation loss: {:>6.3f}’
.format(epoch_i,
epochs,
batch_i,
len(train_source) // batch_size,
loss,
validation_loss[0]))
#保存模型
saver = tf.train.Saver()
saver.save(sess, checkpoint)
print(‘Model Trained and Saved’)
#对源数据进行转换
def source_to_seq(text):
sequence_length = 7
return [source_letter_to_int.get(word, source_letter_to_int[’’]) for word in text] + [source_letter_to_int[’’]]*(sequence_length-len(text))
#输入一个单词
input_word = ‘acdbf’
text = source_to_seq(input_word)
checkpoint = “model/trained_model.ckpt”
loaded_graph = tf.Graph()
#模型预测
with tf.Session(graph=loaded_graph) as sess:
#加载模型
loader = tf.train.import_meta_graph(checkpoint + ‘.meta’)
loader.restore(sess, checkpoint)
input_data = loaded_graph.get_tensor_by_name(‘inputs:0’)
logits = loaded_graph.get_tensor_by_name(‘predictions:0’)
source_sequence_length = loaded_graph.get_tensor_by_name(‘source_sequence_length:0’)
target_sequence_length = loaded_graph.get_tensor_by_name(‘target_sequence_length:0’)
answer_logits = sess.run(logits, {input_data: [text] * batch_size,
target_sequence_length: [len(text)] * batch_size,
source_sequence_length: [len(text)] * batch_size})[0]
pad = source_letter_to_int[""]
print(‘原始输入:’, input_word)
print(’\nSource’)
print(’ Word 编号: {}’.format([i for i in text]))
print(’ Input Words: {}’.format(" ".join([source_int_to_letter[i] for i in text])))
print(’\nTarget’)
print(’ Word 编号: {}’.format([i for i in answer_logits if i != pad]))
print(’ Response Words: {}’.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))
然后我们看看最终的运行效果,如图7.39所示:
图7.39 代码运行效果(图片来源于CSDN)
发现机器已经学会对输入的单词进行字母排序了,但是遗憾的是如果输入字符太长比如 20 甚至30个大家再测试一下,会发现排序不是那么准确了,原因是因为序列太长了,这也是基础的seq2seq的不足,所以需要优化它,怎么优化呢?就是加上attetion机制,那么什么是attetion机制呢?下面讲一下。
3.Attention机制在seq2seq模型中的运用
由于encoder-decoder模型在编码和解码阶段始终由一个不变的语义向量C来联系着,编码器要将整个序列的信息压缩进一个固定长度的向量中去。这就造成了语义向量无法完全表示整个序列的信息、最开始输入的序列容易被后输入的序列给覆盖掉,会丢失许多细节信息。在长序列上表现的尤为明显。
1)Attention模型的引入
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
下图为seq2seq模型加入了Attention注意力机制,如图7.40所示:
图7.40 Attention注意力机制的seq2seq模型(图片来源于CSDN)
2)Attention求解方式
通过一个小示例来具体讲解attention的应用过程。
(1)问题
一个简单的序列预测问题,输入是x1, x2, x3,输出是预测一步y1。
在本例中,我们将忽略编码器和解码器中使用的RNN类型,而忽略双向输入层的使用。这些元素对于理解解码器中注意力的计算并不显著。
(2)编码
在编码器 - 解码器模型中,输入将被编码为单个固定长度矢量。这是最后一个步骤的编码器模型的输出。
h1 = Encoder(x1, x2, x3)
注意模型需要在每个输入时间步长访问编码器的输出。本文将这些称为每个时间步的“ 注释 ”(annotations)。在这种情况下:
h1, h2, h3 = Encoder(x1, x2, x3)
(3)对齐(Alignment)
解码器一次输出一个值,在最终输出当前输出时间步长的预测(y)之前,该值可能会经过许多层。
对齐模型评分(e)评价了每个编码输入得到的(h)与解码器的当前输出匹配的程度。
分数的计算需要解码器从前一输出时间步长输出的结果,例如s(t-1)。当对解码器的第一个输出进行评分时,这将是0。
使用函数a()执行评分。我们可以对第一输出时间步骤的每个注释(h)进行如下评分:
e11 = a(0, h1)
e12 = a(0, h2)
e13 = a(0, h3)
对于这些分数,我们使用两个下标,例如,e11,其中第一个“1”表示输出时间步骤,第二个“1”表示输入时间步骤。
我们可以想象,如果我们有两个输出时间步的序列到序列问题,那么稍后我们可以对第二时间步的注释评分如下(假设我们已经计算过s1):
e21 = a(s1, h1)
e22 = a(s1, h2)
e23 = a(s1, h3)
本文将函数a()称为对齐模型,并将其实现为前馈神经网络。
这是一个传统的单层网络,其中每个输入(s(t-1)和h1、h2和h3)被加权,使用双曲正切(tanh)激活函数并且输出也被加权。
(4)加权
接下来,使用softmax函数标准化对齐分数。
分数的标准化允许它们被当作概率对待,指示每个编码的输入时间步骤(注释)与当前输出时间步骤相关的可能性。
这些标准化的分数称为注释权重。
例如,给定计算的对齐分数(e),我们可以计算softmax注释权重(a)如下:
a11=exp(e11)/(exp(e11)+exp(e12)+exp(e13))
a12=exp(e12)/(exp(e11)+exp(e12)+exp(e13))
a13=exp(e13)/(exp(e11)+exp(e12)+exp(e13))
如果我们有两个输出时间步骤,则第二输出时间步骤的注释权重将计算如下:
a21 = exp(e21) / (exp(e21) + exp(e22) + exp(e23))
a22 = exp(e22) / (exp(e21) + exp(e22) + exp(e23))
a23 = exp(e23) / (exp(e21) + exp(e22) + exp(e23))
(5)上下文向量(context vector)
接下来,将每个注释(h)与注释权重(a)相乘以产生新的具有注意力的上下文向量,从中可以解码当前时间步骤的输出。
为了简单起见,我们只有一个输出时间步骤,因此可以如下计算单个元素上下文向量(为了可读性,使用括号):
c1 = (a11 * h1) + (a12 * h2) + (a13 * h3)
上下文向量是注释和标准化对齐得分的加权和。
如果我们有两个输出时间步骤,上下文向量将包括两个元素[c1,c2],计算如下:
c1 = a11 * h1 + a12 * h2 + a13 * h3
c2 = a21 * h1 + a22 * h2 + a23 * h3
(6)解码
然后,按照编码器-解码器模型执行解码,在本例中为当前时间步骤使用带注意力的上下文向量。
本文将解码器的输出称为隐藏状态。
s1 = Decoder(c1)
此隐藏状态可以在作为时间步长的预测(y1)最终输出模型之前,被喂到其他附加层。
3)Attention的好处
有以下几个方面:
(1)更丰富的编码。编码器的输出被扩展,以提供输入序列中所有字的信息,而不仅仅是序列中最后一个字的最终输出。
(2)对齐模型。新的小神经网络模型用于使用来自前一时间步的解码器的参与输出来对准或关联扩展编码。
(3)加权编码。对齐的加权,可用作编码输入序列上的概率分布。
(4)加权的上下文矢量。应用于编码输入序列的加权然后可用于解码下一个字。
注意,在所有这些编码器 - 解码器模型中,模型的输出(下一个预测字)和解码器的输出(内部表示)之间存在差异。解码器不直接输出字; 通常,完全连接的层连接到解码器,该解码器输出单词词汇表上的概率分布,然后使用启发式的搜索进一步搜索。
总结
上面我们详细讲了Seq2Seq模型,实际上Seq2Seq模型不仅仅可以用RNN来实现,也可以用CNN来实现。由Facebook人工智能研究院提出来的完全基于卷积神经网络的seq2seq框架,seq2seq我在之前的推送中已经讲过好多次了,传统的seq2seq模型是基于RNN来实现的,特别是LSTM,这就带来了计算量复杂的问题。Facebook作出大胆改变,将编码器、解码器、注意力机制甚至是记忆单元全部替换成卷积神经网络,想法是不是简单粗暴?虽然单层CNN只能看到固定范围的上下文,但是将多个CNN叠加起来就可以很容易将有效的上下文范围放大。Facebook将此模型成功地应用到了英语-法语机器翻译、英语-德语机器翻译,不仅刷新了二者前期的记录,而且还将训练速度提高了一个数量级,无论是GPU还是CPU上。
除了推荐Seq2Seq端到端神经网络
其它深度学习框架也有不错的开源实现,比如MXNet,
此文章有对应的配套视频,其它更多精彩文章请大家下载充电了么app,可获取千万免费好课和文章,配套新书教材请看陈敬雷新书:《分布式机器学习实战》(人工智能科学与技术丛书)
【新书介绍】
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目
【新书介绍视频】
分布式机器学习实战(人工智能科学与技术丛书)新书【陈敬雷】
视频特色:重点对新书进行介绍,最新前沿技术热点剖析,技术职业规划建议!听完此课你对人工智能领域将有一个崭新的技术视野!职业发展也将有更加清晰的认识!
【精品课程】
《分布式机器学习实战》大数据人工智能AI专家级精品课程
【免费体验视频】:
人工智能百万年薪成长路线/从Python到最新热点技术
从Python编程零基础小白入门到人工智能高级实战系列课
视频特色: 本系列专家级精品课有对应的配套书籍《分布式机器学习实战》,精品课和书籍可以互补式学习,彼此相互补充,大大提高了学习效率。本系列课和书籍是以分布式机器学习为主线,并对其依赖的大数据技术做了详细介绍,之后对目前主流的分布式机器学习框架和算法进行重点讲解,本系列课和书籍侧重实战,最后讲几个工业级的系统实战项目给大家。 课程核心内容有互联网公司大数据和人工智能那些事、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)、就业/面试技巧/职业生涯规划/职业晋升指导等内容。
【充电了么公司介绍】
充电了么App是专注上班族职业培训充电学习的在线教育平台。
专注工作职业技能提升和学习,提高工作效率,带来经济效益!今天你充电了么?
充电了么官网
http://www.chongdianleme.com/
充电了么App官网下载地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行业职位】 - 专注职场上班族职业技能提升
覆盖所有行业和职位,不管你是上班族,高管,还是创业都有你要学习的视频和文章。其中大数据智能AI、区块链、深度学习是互联网一线工业级的实战经验。
除了专业技能学习,还有通用职场技能,比如企业管理、股权激励和设计、职业生涯规划、社交礼仪、沟通技巧、演讲技巧、开会技巧、发邮件技巧、工作压力如何放松、人脉关系等等,全方位提高你的专业水平和整体素质。
【牛人课堂】 - 学习牛人的工作经验
1.智能个性化引擎:
海量视频课程,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习课程。
2.听课全网搜索
输入关键词搜索海量视频课程,应有尽有,总有适合你的课程。
3.听课播放详情
视频播放详情,除了播放当前视频,更有相关视频课程和文章阅读,对某个技能知识点强化,让你轻松成为某个领域的资深专家。
【精品阅读】 - 技能文章兴趣阅读
1.个性化阅读引擎:
千万级文章阅读,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习文章。
2.阅读全网搜索
输入关键词搜索海量文章阅读,应有尽有,总有你感兴趣的技能学习文章。
【机器人老师】 - 个人提升趣味学习
基于搜索引擎和智能深度学习训练,为您打造更懂你的机器人老师,用自然语言和机器人老师聊天学习,寓教于乐,高效学习,快乐人生。
【精短课程】 - 高效学习知识
海量精短牛人课程,满足你的时间碎片化学习,快速提高某个技能知识点。