Hadoop基础【HDFS、Yarn、MapReduce框架概述、框架的搭建】
1、Hadoop是什么
是一个由Apache基金会所开发的分布式系统基础架构;主要解决海量数据的存储和海量数据的分析计算问题;hadoop通常是指一个更加宽泛的概念,Hadoop生态圈。
最先遇到大数据问题的是一些搜索引擎,Google在大数据方面的三篇论文,称为Hadoop的思想之源。
GFS(分布式存储)---> HDFS;Map-Reduce(分布式计算框架)---> MR;BigTable(分布式数据库)---> HBase
2、Hadoop的四个优势
数据的存储高可靠,当给框架发送一份数据时,这个数据会在集群中保存三份,如果一份数据丢失,不会造成整个数据的丢失。
框架的高扩展性,随着业务的增长,集群的扩展十分方便。
高效性,在分布式计算MapReduce的思想下(并行计算),数据的运算十分快速。
高容错性,并行计算的过程中,多个任务中的一个任务失败,不会造成全部任务的瘫痪,Hadoop能够将失败的任务重启。
3、Hadoop的组成
Hadoop由四部分组成,如下图:
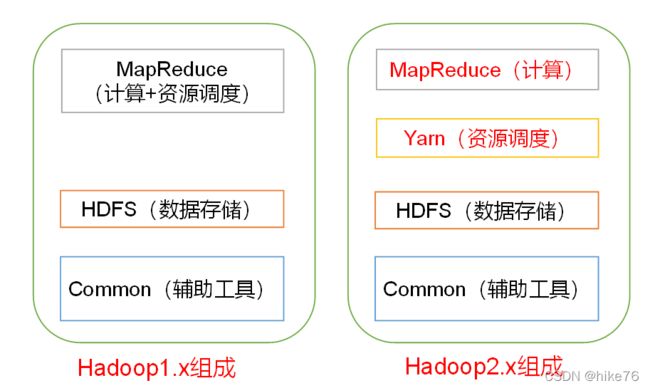
分布式计算一定会涉及到资源调度:简单理解完成一份工作,需要不同的资源,那么用谁的资源,用多少资源,怎么使用这些资源,称为资源的调度。
在Hadoop2.x Yarn专门负责资源调度,这种思想称为解耦,解耦的好处是可以将MapReduce计算框架进行替换,比如spark框架。但是2.x比1.x的效率要略低一些。
4、HDFS架构概述
HDFS(Hadoop Distributed File System):Hadoop分布式文件系统,是一个巨大的硬盘,适合一次读入,多次读出,多用于数据的分析。
NameNode(nn):master,管理者,相当于一个目录,配置副本策略(副本安排哪几个DataNode上,以及挂了要不要备份),管理数据块,存储数据的元数据(文件名,文件目录结构,文件属性)、每个文件的块列表和块所在的DataNode,处理客户端的读写请求。
DataNode(dn):存储一个一个的数据块,并执行对数据块的读写操作,在本地文件系统存储文件块数据,块数据的校验和。
NameNode(主)之间的关系DataNode(从):一主N从。
Secondary NameNode(2nn):nn在集群中只有一个,如果nn挂了,就会造成文件的查询出现问题,当nn出现问题时,重启整个集群。在HA架构中,会有多个nn。2nn不是nn的热备份,2nn隔一段时间对nn元数据进行备份,是nn的助手。
client:客户端,文件切分(文件分几块,每块分多大),与nn交互(下载需要知道块在哪里),直连DN。
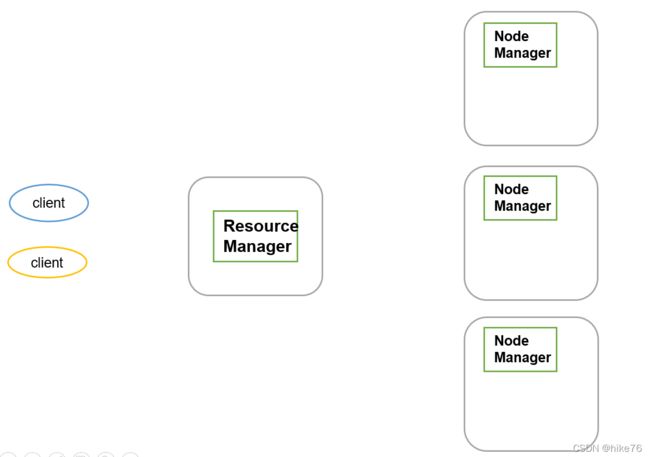
5、Yarn架构概述
Yarn负责资源调度,计算机的CPU,内存可以称作资源,磁盘的调度由HDFS完成。当执行一个任务时,分配多少CPU、多少内存由Yarn完成。
主机称为Resource Manager,从机叫做Node Manager,一主n从。
NodeManager负责这个节点的资源(CPU和内存),一个节点可以做什么事情,由NodeManager决定,每个节点将自己能做什么事情,告诉Resource Manager ,即为整个集群可以完成的工作。
当client需要某一资源时,先向RM进行请求,RM之后再去通知NM,这里需要注意,RM不会事事亲为,当RM接收到一个用户请求时,在某几个节点内部启动Application Master,可以理解为临时负责人,由AM完成具体资源的调度,并向RM发起资源申请,RM执行最后的决定,之后AM功成身退,请客户完成验收,将资源返还给RM。
一个NM在同一时间可能做很多的事情,这时就需要将节点资源进行划分,以Container的形式划分,Container是一项虚拟化技术,类比虚拟机,它封装了某个节点上的多维度资源,如内存,CPU,磁盘,网络等。
所以RM的主要作用是处理客户端请求、监控NM、启动或监控ApplicationMaster、资源的分配与调度。
NM管理单个节点上的资源、处理来自RM的命令、处理来自AM的命令。
AM负责数据切分、为应用程序申请资源并分配给内部的任务、任务的监控与容错。
6、MapReduce架构概述
MapReduce与HDFS、Yarn最大的不同在于MapReduce实际上是一个计算的思想,是一个流程,是一个普通的java程序,并不是一个集群。
MapReduce将计算过程分为两个阶段:Map和Reduce。Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
对一个任务而言,需要将其进行划分,分开处理,之后再将结果进行汇总,分的过程称为Map,汇总的过程称为Reduce。
7、框架搭建
实验室环境下Hadoop平台的搭建