大数据(hadoop分布式搭建--尚硅谷)手把手教学
二 Hadoop 运行环境搭建
1.创建虚拟机,创建名称为hadoop100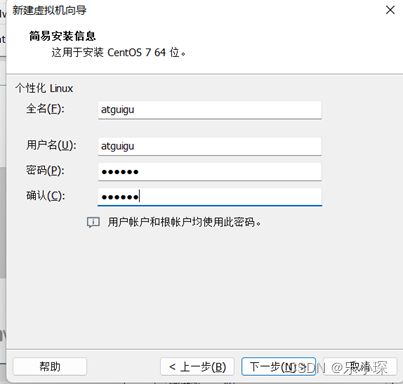
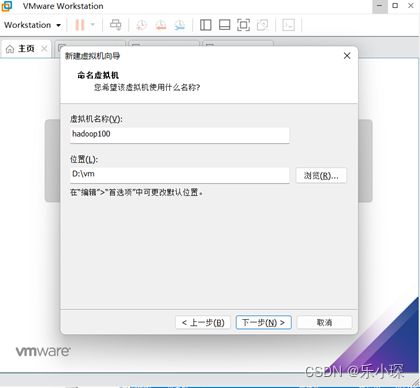
 点击编辑—>虚拟网络编辑器,进行网络编辑,点击更改配置
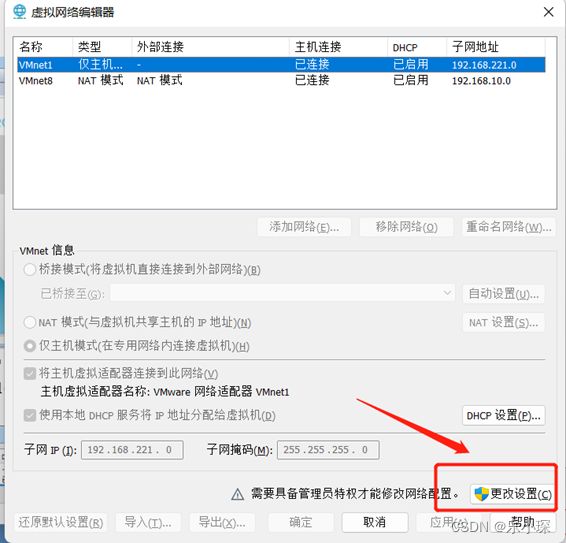
将VMnet8网络模式改为NET模式,并且将子网IP地址配置为192.168.10.0,将子网掩码设置为:255.255.255.0


(2) 更改本机的ip地址配置
在设置中选择网络和Internet,选择拨号,点击更改适配器选项,
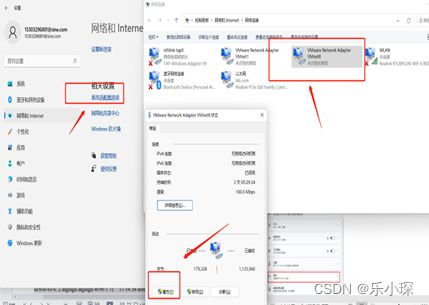
双击IPV4,将配置改为如图所示:
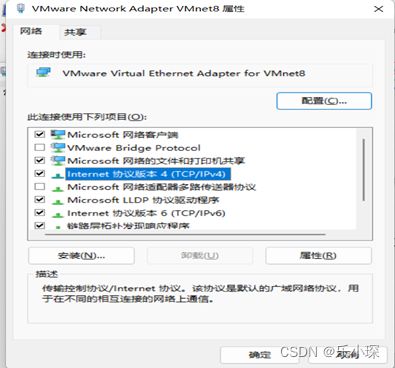
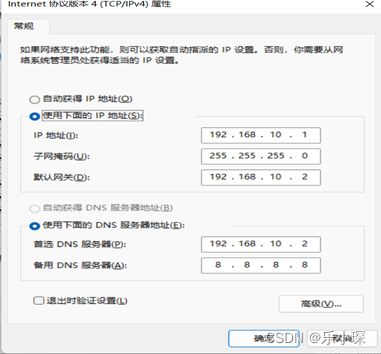
(3) 更改虚拟机的网络配置
1).使用命令切换到root用户下
[atguigu@localhost ~]$ su root
2).使用vim命令编辑ifcfg-ens33文件,编辑完成ESC退出,输入:WQ 保存
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
将其中内容改为:
TYPE=“Ethernet”
PROXY_METHOD=“none”
BROWSER_ONLY=“no”
BOOTPROTO=“static”
DEFROUTE=“yes”
IPV4_FAILURE_FATAL=“no”
IPV6INIT=“yes”
IPV6_AUTOCONF=“yes”
IPV6_DEFROUTE=“yes”
IPV6_FAILURE_FATAL=“no”
IPV6_ADDR_GEN_MODE=“stable-privacy”
NAME=“ens33”
UUID=“668f3287-8be7-4d72-a7bc-959b68eb1ab2”
DEVICE=“ens33”
ONBOOT=“yes”
#根据自己的IP地址更改下边的IP即可,其余的不用动
IPADDR=192.168.10.102
GATEWAY=192.168.10.2
DNS1=192.168.10.2
(4) 更改主机名为hadoop100,修改主机映射名
[root@localhost ~]# vim /etc/hostname
[root@localhost ~]# vim /etc/hosts
在hosts文件下追加以下内容:
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
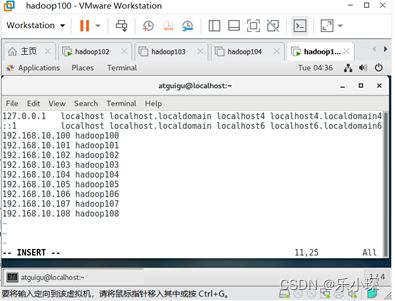
配置完ip地址和host文件名之后,输入reboot 重启虚拟机
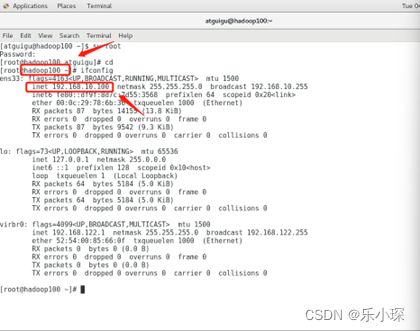
(5) 验证配置成功
使用ifconfig命令查看ip地址:
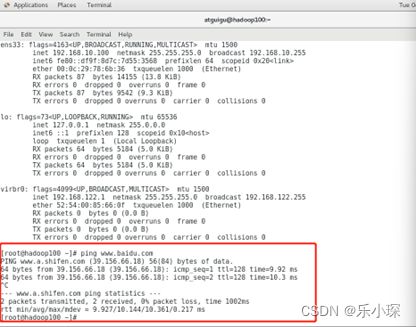
使用命令 ping www.baidu.com 查看是否可以连接外网,ctrl+c 退出ping命令
3 虚拟机环境准备
1.使用xshell远程登录和xftp远程传输文件,免费下载链接:
https://www.xshell.com/zh/free-for-home-school/
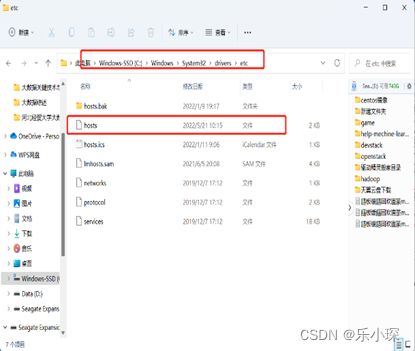
2.配置本地hosts文件C:\Windows\System32\drivers\etc 在hosts文件中追加内容为:
192.168.10.100 hadoop100
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104

3.使用xshell远程登录hadoop100,名称填写hadoop100,点击连接->接受并保存->输入用户名 root ->输入密码(000000)

- 进入到远程登陆界面,安装epel-release
[root@hadoop100 ~]# yum install -y epel-release

显示安装成功。
5.关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service
6.创建atguigu用户,并修改atguigu用户密码
[root@hadoop100 ~]# useradd atguigu
[root@hadoop100 ~]# passwd atguigu
7.配置atguigu用户具有的root权限,方便后期加sudo执行root权限命令
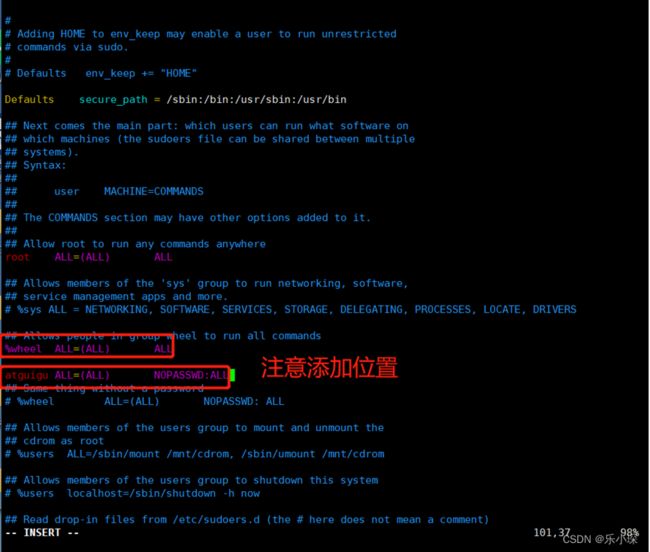
[root@hadoop100 ~]# vim /etc/sudoers
在文件下添加(注意添加位置): atguigu ALL=(ALL) NOPASSWD:ALL
8卸载现有 JDK
8.1查询是否安装 Java 软件:
[atguigu@hadoop100 ~]$ rpm -qa | grep java

8.2如果安装的版本低于 1.7,卸载该 JDK:
首先切换到root用户下,其次删除jdk
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e –nodeps
重启虚拟机:reboot
9.在/opt 目录下创建文件夹
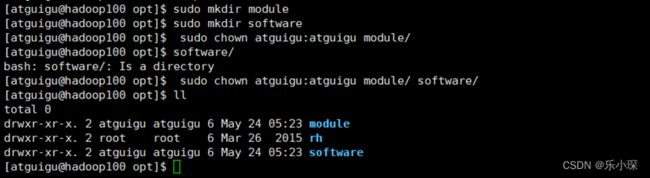
(1)在/opt 目录下创建 module、software 文件夹
[atguigu@hadoop100 opt]$ sudo mkdir module
[atguigu@hadoop100 opt]$ sudo mkdir software
(2)修改 module、software 文件夹的所有者 cd
[atguigu@hadoop100 opt]$ sudo chown atguigu:atguigu module/ software/
[atguigu@hadoop100 opt]$ ll
- 克隆虚拟机(使用模板机hadoop100 克隆出三台虚拟机)点击 创建完整克隆,虚拟机名称为hadoop102,依次克隆出来hadoop102,hadoop103,hadoop104并修改三个虚拟机的ip地址(vim /etc/sysconfig/network-scripts/ifcfg-ens33),hostname(vim /etc/hostname)
Reboot重启
11.配置jdk
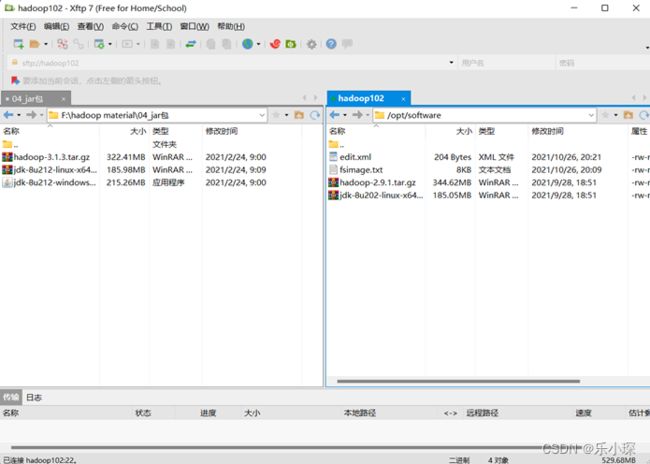
(1)用 xftp工具将 JDK ,hadoop导入到 opt 目录下面的 software 文件夹下面
(2) 解压 JDK 到/opt/module 目录下
[atguigu@hadoop101 software]$ tar -zxvf jdk-8u144-linux-
x64.tar.gz -C /opt/module/
(3) 配置 JDK 环境变量
·先获取 JDK 路径
[atguigu@hadoop102 jdk1.8.0_202]$ pwd
/opt/module/jdk1.8.0_202
·进入到profile.d文件下,新建my_env.sh配置文件
[atguigu@hadoop102 jdk1.8.0_202]$ cd /etc/profile.d/
[atguigu@hadoop102 jdk1.8.0_202]$ sudo vim my_env.sh
在文件下添加以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
·让修改后的文件生效
[atguigu@hadoop102 jdk1.8.0_202]$ source /etc/profile
·测试 JDK 是否安装成功
[atguigu@hadoop101 jdk1.8.0_202]# java -version
java version " jdk1.8.0_202"
注意:重启(如果 java -version 可以用就不用重启)
[atguigu@hadoop101 jdk1.8.0_144]$ sync
[atguigu@hadoop101 jdk1.8.0_144]$ sudo reboot
12.配置hadoop环境变量
·进入到 Hadoop 安装包路径下
[atguigu@hadoop101 ~]$ cd /opt/software/
·解压安装文件到/opt/module 下面
[atguigu@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
·查看是否解压成功
[atguigu@hadoop101 software]$ ls /opt/module/
hadoop-2.7.2
·获取 Hadoop 安装路径
[atguigu@hadoop101 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.9.1
·进入到profile.d文件下,修改my_env.sh配置文件
[atguigu@hadoop102 jdk1.8.0_202]$ sudo vim /etc/profile.d/my_env.sh
在文件下添加以下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.9.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
·让修改后的文件生效
[atguigu@ hadoop101 hadoop-2.9.1]$ source /etc/profile
·测试是否安装成功
[atguigu@hadoop101 hadoop-2.9.1]$ hadoop version
Hadoop 2.9.1
· 重启(如果 Hadoop 命令不能用再重启)
[atguigu@ hadoop101 hadoop-2.9.1]$ sync
[atguigu@ hadoop101 hadoop-2.9.1]$ sudo reboot
13分发jdk与hadoop
(1)使用scp安全拷贝,将配置好的jdk,hadoop分发给hadoop103,hadoop104.
·[atguigu@hadoop102 module]$ scp -r jdk1.8.0_202/ atguigu@hadoop103:/opt/module/
·[atguigu@hadoop102 module]$ scp -r jdk1.8.0_202/ atguigu@hadoop104:/opt/module/
·[atguigu@hadoop102 module]$ scp -r hadoop-2.9.1/ atguigu@hadoop103:/opt/module/
·[atguigu@hadoop102 module]$ scp -r hadoop-2.9.1/ atguigu@hadoop104:/opt/module/
(2)创建xsync脚本,实现分发功能
·[atguigu@hadoop102 ~]$ mkdir bin
·[atguigu@hadoop102 ~]$ cd bin/
·[atguigu@hadoop102 bin]$vim xsync
在xsync文件下添加如下内容:
#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ============ $host =============
#3. 遍历所有目录,逐个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
·修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 xsync
·使用xsync同步分发
[atguigu@hadoop102 ~]$ xsync bin/
·分发环境变量配置文件
[atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
·在hadoop103、hadoop104上执行:
[atguigu@hadoop103 ~]$ source /etc/profile
14 ssh无秘登录(此操作需要在hadoop102、hadoop103、hadoop104上均需要配置)
·[atguigu@hadoop102 ~]$ cd ~/.ssh
·[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到hadoop103、hadoop104上去。
·[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
·[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
·[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
15 配置文件
首先使用命令进入到hadoop文件夹下:
·[atguigu@hadoop102 ~]$ cd /opt/module/hadoop-2.9.1/etc/hadoop/
·[atguigu@hadoop102 hadoop]$ vim core-site.xml
在core-site.xml添加内容为:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop102:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.9.1/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>atguiguvalue>
property>
configuration>
·[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
在hdfs-site.xml添加如下内容:
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop102:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop104:9868value>
property>
configuration>
·[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop103value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hadoop102:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
·[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop102:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop102:19888value>
property>
configuration>
16.将配置好的文件分发给hadoop103,hadoop104
·[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.9.1/etc/hadoop/
在去hadoop103、hadoop104上查看配置情况
17.启动集群
配置slaves
·[atguigu@hadoop102 ~]$ vim /opt/module/hadoop-2.9.1/etc/hadoop/slaves
将slaves内容改为:
hadoop102
hadoop103
hadoop104
并将slaves分发给hadoop103、hadoop104
·[atguigu@hadoop102 ~]$ xsync /opt/module/hadoop-2.9.1/etc/hadoop/slaves
集群第一次启动,需要初始化
·[atguigu@hadoop102 hadoop-2.9.1]$ hdfs namenode -formate
在hadoop102上启动hdfs:
·[atguigu@hadoop102 ~]$ cd /opt/module/hadoop-2.9.1/
·[atguigu@hadoop102 hadoop-2.9.1]$ sbin/start-dfs.sh
在hadoop103上启动yarn:
·[atguigu@hadoop103 ~]$ cd /opt/module/hadoop-2.9.1/
·[atguigu@hadoop103 hadoop-2.9.1]$ sbin/start-yarn.sh
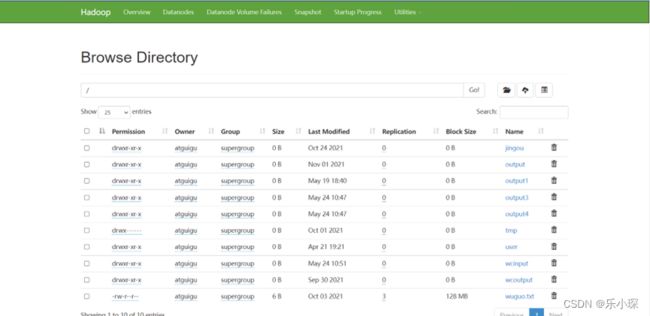
在网页查看HDFS的namendoe:http://hadoop102:9870
在网页查看YERN的resourcemanager: http://hadoop103:8088
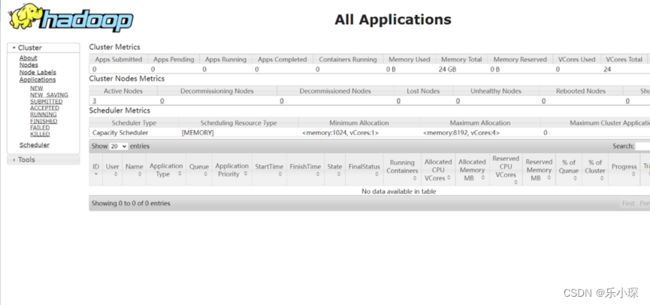
·使用jps命令查看三个虚拟机的集群启动情况
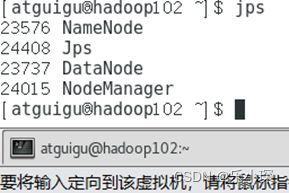
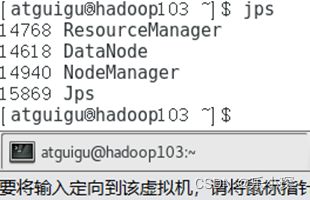
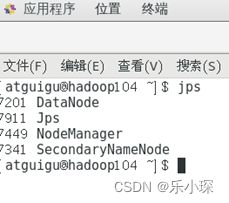
18 编写两个常用脚本
(1)集群启动脚本:首先进入到bin目录下,
·[atguigu@hadoop102 ~]$ cd bin/
·[atguigu@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input ..."
exit;
fi
case $1 in
"start")
echo "============启动hadoop集群=========="
ssh hadoop102 "/opt/module/hadoop-2.9.1/sbin/start-dfs.sh"
echo "============启动yarn==============="
ssh hadoop103 "/opt/module/hadoop-2.9.1/sbin/start-yarn.sh"
;;
"stop")
echo "============关闭yarn==============="
ssh hadoop103 "/opt/module/hadoop-2.9.1/sbin/stop-yarn.sh"
echo "============关闭hadoop集群=========="
ssh hadoop102 "/opt/module/hadoop-2.9.1/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
激活脚本:
·[atguigu@hadoop102 bin]$ chmod 777 myhadoop.sh
使用脚本一键开启或关闭集群:
·[atguigu@hadoop102 ~]$ myhadoop.sh stop
·[atguigu@hadoop102 ~]$ myhadoop.sh start

(2)编写查看所有集群状态脚本
·[atguigu@hadoop102 bin]$ vim jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo ================== $host ===========
ssh $host jps
done
使用jpsall命令查看集群启动情况
