动转静两大升级!一键转静成功率领先,重点模型训练提速18%+
目前主流深度学习框架支持的编程方式有两种,分别为动态图和静态图。动态图的Pythonic编程体验更佳、更易调试,但性能方面与静态图有一定差距。静态图先组网再执行,预先拥有完整网络结构,更利于全局优化,虽调试难度大,但执行性能更佳。
百度飞桨采用动静统一的技术架构设计,提供了动转静(@to_static)模块功能,支持用户动态图编程,并可一键切换静态图训练和部署。2022年11月,飞桨框架 2.4 版本(以下简称飞桨v2.4)正式发布,动转静“转换成功率”和“训练性能”迎来全面升级,带来了全新的用户使用体验。
- 动转静成功率明显提升,一键转换成功率达到92.1%。
- 动转静训练加速效果明显,重点模型训练可提速18%+。
一键转静成功率明显提升
动转静的转换成功率是动转静功能的一个重要指标,与用户的使用体验息息相关,飞桨v2.4从“动转静语法完善”和“API动静行为统一”两个方面进行了重点优化和升级:
动转静语法完善
JIT 式动态执行
新增 Shape、Len、Attr、List、Unpack、Indexable等JIT 形式接口,提升语法转写的鲁棒性。
控制流语法重构
重构了控制流IF/For/While语法转写逻辑,完备支持复杂嵌套场景下变量名解析等疑难问题。
关键字语法优化
优化了控制流中提前return、break、continue 等关键字语法转写机制,有效减少了静态图中间表示多余算子的引入,提升执行效率。
API动静行为统一
属性参数可变
完成了20多个中高频动态图API参数的升级,如
Reduce系列的paddle.mean/sum/max/min API的参数 axis ,新增支持为Tensor类型,动态可变。
接口动静统一
补齐了Tensor类静态图下缺失的接口,升级了paddle.to_tensor、paddle.grad等高频API 功能,支持静态图调用。
Einsum 升级
实现了动静统一爱因斯坦求和算子,并支持Python二元、多元输入,训推一体。
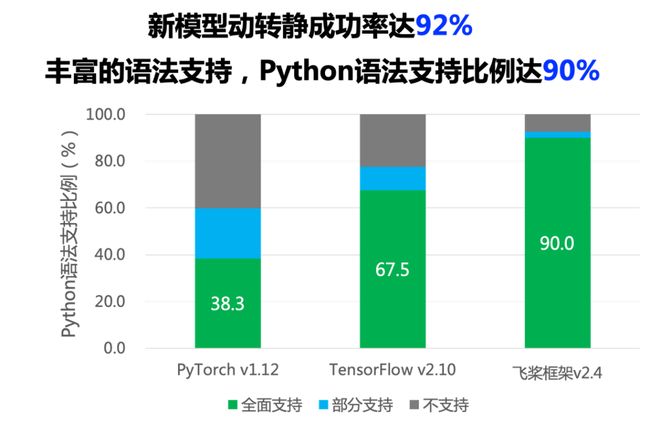 飞桨v2.4下,动转静具备了更丰富的语法支持,Python语法支持比例达到了90%,在80多个外部用户真实论文复现模型集合上,动转静一键转写成功率提升至92.1%,功能完备性和易用性都有明显提升。 如下是一个动转静导出预测模型的样例代码:
飞桨v2.4下,动转静具备了更丰富的语法支持,Python语法支持比例达到了90%,在80多个外部用户真实论文复现模型集合上,动转静一键转写成功率提升至92.1%,功能完备性和易用性都有明显提升。 如下是一个动转静导出预测模型的样例代码:
import paddle
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
@paddle.jit.to_static # step 1: 添加装饰器
def forward(self, x):
out = self.linear(x)
out = out + 1
return out
net = SimpleNet()
train(net) # 此处略去了训练过程
# step 2: 切换到 eval() 模式
net.eval()
# step 3: 调用 jit.save 接口
paddle.jit.save(net, path='./simple_net')
执行上述代码样例后,在当前目录下会生成三个文件,即代表成功导出预测模型:
simple_net.pdiparams // 存放模型中所有的权重数据
simple_net.pdmodel // 存放模型的网络结构
simple_net.pdiparams.info // 存放额外的其他信息
动转静导出模型一般包括三个步骤:
- 添加装饰器
将@to_static装饰器装饰在forward函数上。
- 切换 eval 模式
如Dropout 、LayerNorm 接口在 train() 和 eval() 模式下行为存在较大的差异,在模型导出前,请务必确认模型已切换到正确的模式。
- 调用 save 接口
调用 paddle.jit.save接口导出其对应的模型文件和参数文件。飞桨动转静@to_staitc更多功能用法,可参考【扩展阅读—动转静使用样例】
动转静训练加速效果明显
在飞桨框架中,通常情况下使用动态图训练即可满足大部分场景需求。飞桨v2.4优化了动转静训练的相关逻辑,面向重点模型,动态图训练的性能已经可以和静态图媲美,例如在ResNet50、Transformer、YOLOv3等模型上,动转静训练相较于动态图有18.6%~21.5%的显著加速效果。
 重点模型加速效果在如下场景中,开发者可以考虑使用动转静方式进行模型训练,将会获得较明显的性能提升效果。
重点模型加速效果在如下场景中,开发者可以考虑使用动转静方式进行模型训练,将会获得较明显的性能提升效果。
场景一: 重调度模型
即每个API背后的GPU Kernel 计算耗时较少,在CPU端拉起后很快就执行完了,此类任务的特点:
- PU 利用率较低(可通过watch -n 1 nvidia-smi命令查看)。
- 常见于NLP 领域或AMP/FP16 任务。
- 训练性能瓶颈点主要是Host端调度开销。
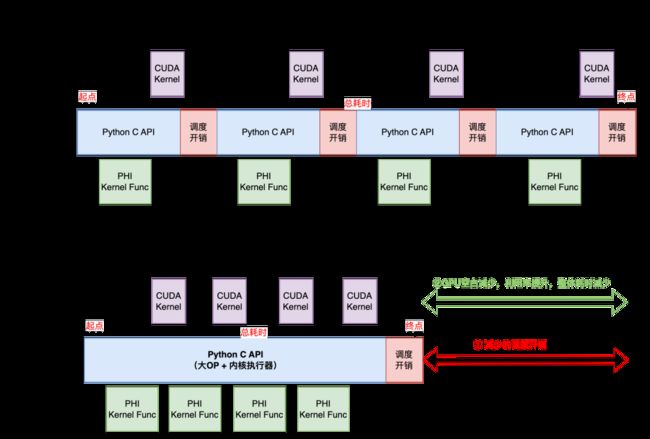
如上图是重调度模型的动态图和动转静 Timeline 示意图。从图中可以看出:
-
一个Batch的训练耗时取决于 Host 端总耗时。
-
动态图每个Python API在运行时,都会产生一次Python 和C++交互,会产生较大的调度开销。
-
动转静之后,整体上切分为执行前向和反向的两个Python C API,故减少了很多个API间的调度开销。
-
动转静内核执行器也经过了极致的优化(如Instruction缓存等),Kernel launch效率也会比纯动态图模式要高。
对于想使用动态图训练代码的用户来说,只需要在组网入口的forward函数处添加装饰器@to_static,其他代码无需改动就可以一键切换为动转静训练。@to_static装饰器会将此函数内的所有subLayers 转化为一个静态子图并执行。如下是一个动转静训练样例代码:
import paddle
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
@paddle.jit.to_static # 仅需一行代码
def forward(self, x):
out = self.linear(x)
out = out + 1
return out
# create network
net = SimpleNet()
adam = opt.Adam(learning_rate=0.001, parameters=net.parameters())
for batch_id, x in enumerate(data_loader()):
out = net(x)
loss = paddle.mean(out)
loss.backward()
opt.step()
opt.clear_grad()
场景二:调度+计算共存模型
即模型训练时同时存在计算量小和计算量大的GPU Kernel,且一个Batch的起始位置常为小Kernel,此类任务的特点:
- GPU 利用率波动比较大(可通过watch -n 1 nvidia-smi命令查看)。
- 训练性能瓶颈点同时受局部调度和局部 Kernel 计算效率影响。
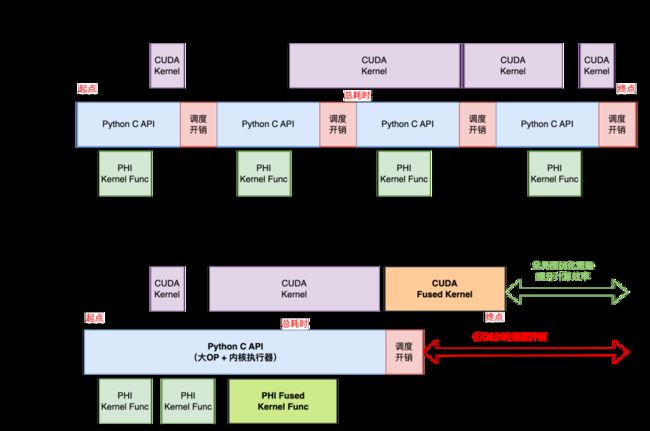 如上图是调度+计算共存的动态图和动转静Timeline示意图。从图中可以看出:
如上图是调度+计算共存的动态图和动转静Timeline示意图。从图中可以看出:
- 一个Batch的训练耗时取决于 Max(Host端,GPU端)。
- 动转静降低了Python C API 调度开销,收益点大多在Batch前半部分,后半部分可能会被overlap,调度方面的收益会打折扣。
- 动转静可借助全局图优化技术,通过算子融合等技术提升模型训练的吞吐。
在此种场景下,飞桨动转静@to_static API 提供build_strategy参数,在动转静的全图视角下,用户可以通过build_strategy参数开启不同的全局图优化策略。通过装饰器@to_static(build_strategy=get_build_strategy())或者API调用paddle.jit.to_static(net, build_strategy=get_build_strategy())两种方式开启全局图优化策略,如下是一个简单的使用样例:
import numpy as np
import paddle
import paddle.nn as nn
def get_build_strategy():
build_strategy = paddle.static.BuildStrategy()
# 算子融合策略
build_strategy.fuse_elewise_add_act_ops = True
# 梯度 addto 策略
build_strategy.enable_addto = True
os.environ['FLAGS_max_inplace_grad_add'] = "8"
return build_strategy
class ResNet(paddle.nn.Layer):
# 此处省略了模型定义
@to_static(build_strategy=get_build_strategy()) # 方式一
def forward(self, image):
# 省略前向代码
# create network
net = ResNet()
# 借助 build_strategy 参数自定义开启「全局图优化」策略
net = paddle.jit.to_static(net, build_strategy=get_build_strategy()) # 方式二
adam = opt.Adam(learning_rate=0.001, parameters=net.parameters())
for batch_id, image in enumerate(data_loader()):
out = layer(image)
loss = paddle.mean(out)
loss.backward()
opt.step()
opt.clear_grad()
飞桨动转静@to_static开启更多全局图优化用法,可参考【扩展阅读—动转静训练图优化策略】
拓展阅读
[1]动转静使用样例https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/jit/basic_usage_cn.html
[2] 动转静训练图优化策略https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/jit/basic_usage_cn.html#sidongzhuanjinggengduoyongfa
[3]动转静转换原理https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/jit/principle_cn.html
[4] 动转静报错调试https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/jit/debugging_cn.html
[5] 动转静Limitationshttps://www.paddlepaddle.org.cn/documentation/docs/zh/develop/guides/jit/limitations_cn.html