一文认知并发安全的几种解决方案与性能对比
Kotlin协程基本套餐:
协程的基本使用
协程的上下文理解
协程的作用域管理
协程的常见进阶使用
之前的系列文章我们讲的是一些 Kotlin 协程的基本概念和一些实用与常用的技巧与方法。其实明白之后,基本的使用是没有问题了。
那么今天我想探讨一下,没有那么常用,但是也很重要的一个点,协程的并发与安全。
为什么并发这么重要,还放在这一篇单独讲呢?使用我们客户端其实并发的场景并不多,除了一些指定的特殊场景,我们一般并发也只是同时执行一些任务而已,很少会在并发的场景中去修改同一个值,当然如果真的有这种操作,我这不是来了吗?
下面我们一起来看看并发中操作同一个值的时候我们该如何保证数据安全问题。
关于如何在协程并发我们在之前的文章已经讲解过,创建协程就是并发,但是之前的文章我们只是大致的说了不推荐使用同步锁,我们使用的是 mutex 互斥锁来做的演示。
那么我们这一期一开始我们就详细的讲一下线程锁/同步锁与协程的互斥锁的一些用法,它们之间的区别。
1.1 异步并发的实现
那么我们先来一段代码,实现一个并发,由于数据量很大,这些计算我们在子线程实现,我们就以并发+异步来举例了:
runBlocking {
var count = 0val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
count++
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
count--
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
}
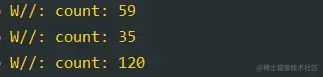
复制代码打印结果: 无锁耗时为165ms左右
1.2 synchronized 关键字
可以看到结果是不会为0的,可能有同学很快的反应过来了,需要加锁,线程同步锁我们最先想到的是 synchronized 关键字,我们看看如何使用:
runBlocking {
var count = 0val lock = "lock"// 需要保证锁的是同一个对象val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
synchronized(lock) {
count++
}
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
synchronized(lock) {
count--
}
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
}
}
YYLogUtils.w("count:执行耗时:$time")
复制代码打印结果:
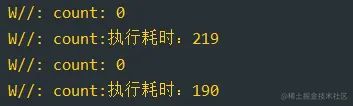
可以看到确实加了锁之后就能保证运行的结果为0,但是耗时会增加。这也都是正常的。
那么我们想优化一下使用 launch 替代 runBlocking 看看效果,能起到优化的作用吗?
launch {
val start = System.currentTimeMillis()
var count = 0val lock = "lock"val job1 = async(Dispatchers.IO) {
repeat(99999) {
synchronized(lock) {
count++
}
}
}
val job2 = async(Dispatchers.IO) {
repeat(99999) {
synchronized(lock) {
count--
}
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码打印结果:
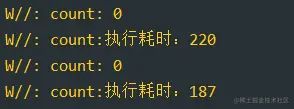
可以看到这是线程的同步操作,我们改协程的启动方式,是否阻塞协程这些东西是没有效果的
1.3 自行实现 ReentrantLock 可重入锁
那么除了 synchronized 关键字,我们还有没有其他的办法加锁,有的,我们可以自行实现锁的逻辑,例如我们可以使用 ReentrantLock 可重入锁来实现
val time = measureTimeMillis {
runBlocking {
var count = 0val lock = ReentrantLock()
val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
lock.lock()
count++
lock.unlock()
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
lock.lock()
count--
lock.unlock()
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
}
}
YYLogUtils.w("count:执行耗时:$time")
复制代码打印的结果:
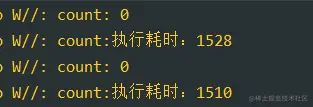
这种锁和读写锁有点类似,我们需要手动的加锁,释放锁。那么首先可以看到结果确实是我们预期的,但是这个效率太慢了,是不如 synchronized 关键字的。
那么这种线程同步锁的操作,是否可以通过修改协程的阻塞启动方式来优化呢?试试
launch {
val start = System.currentTimeMillis()
var count = 0val lock = ReentrantLock()
val job1 = async(Dispatchers.IO) {
repeat(99999) {
lock.lock()
count++
lock.unlock()
}
}
val job2 = async(Dispatchers.IO) {
repeat(99999) {
lock.lock()
count--
lock.unlock()
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码打印结果:
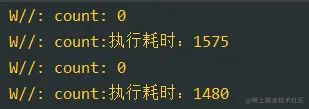
可以看到线程的锁的方式,如果修改协程的启动方式是没有优化效果的。
1.4 mutex的实现
之前的方式都是我们线程同步的概念,接下来我们可以看看协程专用同步工具 mutex 如何使用:
val time = measureTimeMillis {
runBlocking {
var count = 0val mutex = Mutex()
val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
mutex.withLock {
count++
}
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
mutex.withLock {
count--
}
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
}
}
YYLogUtils.w("count:执行耗时:$time")
复制代码打印的结果:
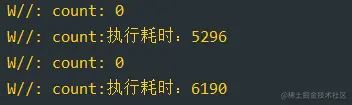
可以看到结果是我们预期的,达到了我们想要的效果,mutex.withLock 内部也是实现了加锁,释放锁的逻辑。但是这个耗时还不如 ReentrantLock 锁呢...
之前的线程同步方式我们修改启动模式貌似并不能起到优化作用,那么协程的锁呢?
我们已经使用 mutex 限制协程了,那么我们不需 runBlocking 来阻塞协程了,我们试试 launch 的方式,看看是否有所缓解。
launch {
val start = System.currentTimeMillis()
var count = 0val mutex = Mutex()
val job1 = async {
repeat(99999) {
mutex.withLock {
count++
}
}
}
val job2 = async {
repeat(99999) {
mutex.withLock {
count--
}
}
}
job1.await()
job2.await()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码改善之后的结果:
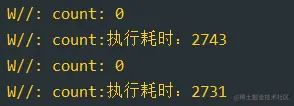
协程的锁的方式,我们可以通过修改启动方式来优化效率,优化效果很明显
1.5 Semaphore 指定通道数量
Semaphore是协程中的信号量 ,我们指定通行的数量为1,那么就可以保证并发的数量为1,这样异曲同工达到锁的效果。
val time = measureTimeMillis {
runBlocking {
var count = 0val semaphore = Semaphore(1)
val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
semaphore.withPermit {
count++
}
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
semaphore.withPermit {
count--
}
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
}
}
YYLogUtils.w("count:执行耗时:$time")
复制代码打印如下:
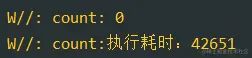
结果如预期,但是这也太慢了,我们已经使用 semaphore 限制运行协程的数量,那么我们不需 runBlocking 来阻塞协程了,我们试试 launch 的方式
launch {
val start = System.currentTimeMillis()
var count = 0val semaphore = Semaphore(1)
val job1 = async {
repeat(99999) {
semaphore.withPermit {
count++
}
}
}
val job2 = async {
repeat(99999) {
semaphore.withPermit {
count--
}
}
}
job1.await()
job2.await()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码打印结果有所优化:
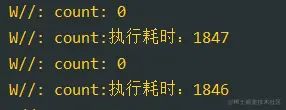
协程的锁的方式,我们可以通过修改启动方式来优化效率,优化效果很明显
1.6 AtomicInteger 保证原子操作
除了线程锁和协程锁的方法,我们还能使用 AtomicInteger 包装count,实现原子操作,从而间接的实现锁的效果。
launch {
val start = System.currentTimeMillis()
val count = AtomicInteger(0)
val job1 = async (Dispatchers.IO) {
repeat(99999) {
count.incrementAndGet()
}
}
val job2 = async (Dispatchers.IO) {
repeat(99999) {
count.decrementAndGet()
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码效果也是相当不错的:

1.7 单线程池实现同步效果
上面的一些方法主流都是给线程或协程加同步锁,就是当有程序在执行的时候,你等等,等你前面的程序执行完成之后你再执行,只是效率和开销有所不同而已。
那么我们能不能换一个思路,我保证协程运行在一个单独的线程池不就行了吗?之前的协程基础文章中我们讲到过,线程池的扩展方法可以转为一个协程上下文对象,我们初始化一个 newSingleThread 的线程池不就行了吗?一样的可以到达锁的效果。
试试看行不行:
val singleDispatcher = Executors.newSingleThreadExecutor {
Thread(it, "SingleThread").apply { isDaemon = true }
}.asCoroutineDispatcher()
lifecycleScope.launch {
val start = System.currentTimeMillis()
var count = 0val job1 = launch(singleDispatcher) {
repeat(99999) {
count++
}
}
val job2 = launch(singleDispatcher) {
repeat(99999) {
count--
}
}
job1.join()
job2.join()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $count")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码打印日志:
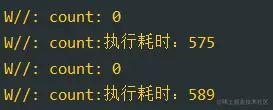
确实能保证结果是我们想要的,并且效率还不低呢,不错不错。注意这里原理是基于单线程实现的,所以修改协程的启动方式 launch runBlocking 效果是一致的。
1.8 actor并发同步模型
actor 是创建协程的一种,但是是特殊的协程,他是继承Channel,关于通道或者叫协程的通信的理解,可以参考我的这一篇文章 Kotlin协程-协程之间的通信与广播。
我们看看 actor 的部分源码:
publicfun CoroutineScope.actor(
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = 0, // todo: Maybe Channel.DEFAULT here?
start: CoroutineStart = CoroutineStart.DEFAULT,
onCompletion: CompletionHandler? = null,
block: suspendActorScope.() -> Unit
): SendChannel {
复制代码 这里我们简单的理解为并发的2个协程与actor的协程通信,actor是一个特殊的协程,保证了单一的原则。从而间接达到锁的效果
这里直接上代码:
runBlocking {
val start = System.currentTimeMillis()
var count = 0suspendfunaddActor() = actor {
for (msg in channel) {
when (msg) {
0 -> count++
1 -> count--
}
}
}
val actor = addActor()
val job1 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
actor.send(0)//加
}
}
val job2 = CoroutineScope(Dispatchers.IO).launch {
repeat(99999) {
actor.send(1)//减
}
}
job1.join()
job2.join()
val deferred = CompletableDeferred()
deferred.complete(count)
val result = deferred.await()
actor.close()
//等待Job1 Job2执行完毕打印结果
YYLogUtils.w("count: $result")
YYLogUtils.w("count:执行耗时:${System.currentTimeMillis() - start}")
}
复制代码 打印结果为:

简直不能接受,我们修改构造参数加入缓存机制 Channel.BUFFERED
suspendfunaddActor() = actor(capacity = Channel.BUFFERED) {
for (msg in channel) {
when (msg) {
0 -> count++
1 -> count--
}
}
}
复制代码 打印的结果:加入容量为64的缓存,效率提升10倍
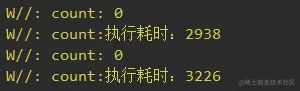
我们换一种容器为Max的缓存,看看效果:
suspendfunaddActor() = actor(capacity = Channel.UNLIMITED) {
for (msg in channel) {
when (msg) {
0 -> count++
1 -> count--
}
}
}
复制代码 打印效果:效率提升就没有那么大了,遇到了性能瓶颈

就算如此,他的效率优化之后也满足不了我们的使用,对排名并没有的影响,它还是最耗时的。可能它的作用只是用于 Channel 中通信的场景下保证安全吧,我们这么直接暴力的使用它老保证普通的并发安全并不是很合适。
总结
优化完成之后我们可以看到并发锁的效率 synchronized(线程同步锁) > AtomicInteger(原子操作) >SingleThreadExecutor(单线程) > ReentrantLock(可重入锁) > Semaphore(协程信号量限制) > Mutex(协程互斥锁)> actor通信并发同步模型
有同学可能会说,都协程了还用 synchronized ?喽不喽啊。。。好吧,其实谷歌自己都用,Flow是运行在协程上的,Flow的源码中几乎都是用 synchronized 来加锁的。我就不一一举例了。
Ok,协程的并发与并发过程中的数据一致性解决方案就讲到这里了。
相信大家理解之后在开发的过程中更能得心应手,关于并发与安全全网很少有比较性能相关的文章,如果有错漏或者使用不当的地方,还望大家指正。
如果大家看的过程有不明白的我更推荐你从系列的第一篇开始看,内部概念与难度是一步一步层层递进的。