【图像分类】猫狗分类实战—基于pytorch框架的迁移学习(ResNet50模型实现分类实战)
说明:
ResNet50模型实现分类实战,数据集是猫狗分类数据集,讲解的特别详细,适合零基础入门。
一、前置准备
1、pytorch环境搭建
pytorch环境安装:Start Locally | PyTorch

复制这个代码到pytorch到pycharm环境进行安装:
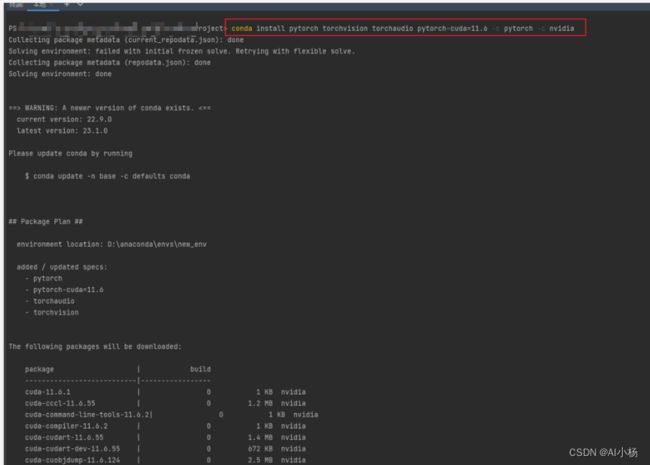
2、数据集介绍
在当前目录创建一个dataset文件夹,用来存放数据集。
在dataset文件夹下创建train、val、test文件夹。
在train文件夹下创建cat()、dog()文件夹,这是当前猫狗实验分类创建的,假如是猫狗猪分类还需要创建一个pig文件夹,以此类推,对应的文件夹下放对应的图片,比如说cat文件夹下放的都是猫的图片。
val、test文件夹与train文件夹相同。
文件夹结构如下:
dataset
|——train
|——dog
|——cat
|——val
|——dog
|——cat
|——test
|——dog
|——cat
我实验的数据集放置在此处:
链接:https://pan.baidu.com/s/1QrNFBdOhdPVic_fn38PFmA?pwd=h6sb
提取码:h6sb
3、创建jupyter notebook实验环境
本次实验是用jupyter notebook环境运行的
(1)、pycharm终端输入jupyter notebook启动notebook实验环境

(2)、jupyter notebook中上传数据集,和创建的.ipynb

二、ResNet50模型代码实现
1、导包
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models
from torch.autograd import Variable
from tqdm import tqdm
import os
from PIL import Image
import cv2
#判断环境是CPU运行还是GPU
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
DEVICE
- 运行截图:

2、数据增强
建好的数据集在输入网络之前先进行数据增强,包括随机 resize 裁剪到 256 x 256,随机旋转,随机水平翻转,中心裁剪到 224 x 224,转化成 Tensor,正规化等。
transform111 = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
transform111
- 运行截图:

3、加载数据
torchvision.transforms包DataLoader是 Pytorch 重要的特性,它们使得数据增加和加载数据变得非常简单。 使用 DataLoader 加载数据的时候就会将之前定义的数据 transform 就会应用的数据上了。
import shutil
modellr = 1e-3
BATCH_SIZE = 64
EPOCHS = 100
# 删除隐藏文件/文件夹
for root, dirs, files in os.walk('./dataset'):
for file in files:
if 'ipynb_checkpoints' in file:
os.remove(os.path.join(root, file))
if 'ipynb_checkpoints' in root:
shutil.rmtree(root)
# 读取数据
dataset_train = datasets.ImageFolder('dataset/train', transform111)
print(dataset_train.imgs)
# 对应文件夹的label
print(dataset_train.class_to_idx)
dataset_test = datasets.ImageFolder('dataset/val', transform111)
# 对应文件夹的label
print(dataset_test.class_to_idx)
dataset = './dataset'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'val')
batch_size = 32
num_classes = 6
print(train_directory)
data = {
'train': datasets.ImageFolder(root=train_directory, transform=transform111['train']),
'val': datasets.ImageFolder(root=valid_directory, transform=transform111['val'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['val'])
train_loader = torch.utils.data.DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
test_loader = torch.utils.data.DataLoader(data['val'], batch_size=batch_size, shuffle=True, num_workers=8)
print(train_data_size, valid_data_size)
- 运行截图:

4、迁移学习
# 下载预训练模型
model = torchvision.models.resnet50(pretrained=False)#不使用训练好的预训练模型
model
- 运行截图:

5、模型调优
为了适应自己的数据集,将ResNet-50的最后一层替换为,将原来最后一个全连接层的输入喂给一个有256个输出单元的线性层,接着再连接ReLU层和Dropout层,然后是256 x 6的线性层,输出为 6 通道的softmax层。
# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
num_ftrs = model.fc.in_features
# model.fc = nn.Linear(num_ftrs, 10)
model.fc = nn.Sequential(
nn.Linear(num_ftrs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 6),
nn.LogSoftmax(dim=1)
)
model.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model.parameters(), lr=modellr)
def adjust_learning_rate(optimizer, epoch):
modellrnew = modellr * (0.1 ** (epoch // 50))
print("lr:", modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
- 运行截图:

6、定义训练过程和验证过程
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
train_acc = 0
total_num = len(train_loader.dataset)
# print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(tqdm(train_loader)):
data, target = Variable(data).to(device), Variable(target).to(device)
im = Variable(data)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
out_t = output.argmax(dim=1) #取出预测的最大值
num_correct = (out_t == target).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
ave_acc = train_acc / len(train_loader)
print('epoch:{}, train_acc: {}, loss:{}'.format(epoch, ave_acc, ave_loss))
return ave_acc, ave_loss
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
# print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('Val set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
return acc, avgloss
7、模型训练
train_acc_list, train_loss_list, val_acc_list, val_loss_list = [], [], [], []
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train_acc, train_loss = train(model, DEVICE, train_loader, optimizer, epoch)
val_acc, val_loss = val(model, DEVICE, test_loader)
train_acc_list.append(train_acc)
val_acc_list.append(val_acc)
train_loss_list.append(train_loss)
val_loss_list.append(val_loss)
torch.save(model, 'model.pth')
- 运行截图:

8、模型评估
import matplotlib.pyplot as plt
epochs_range = range(EPOCHS)
print(epochs_range, train_acc_list)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc_list, label='Training Accuracy')
plt.plot(epochs_range, val_acc_list, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss_list, label='Training Loss')
plt.plot(epochs_range, val_loss_list, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.savefig('./acc-loss.jpg')
- 运行截图:
9、模型推理预测
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.autograd import Variable
from pathlib import Path
classes = ('cat', 'dog')
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)
dataset_test = datasets.ImageFolder('dataset/test', transform_test)
print(len(dataset_test))
# 对应文件夹的label
y_true, y_sore = [], []
for index in range(len(dataset_test)):
item = dataset_test[index]
img, label = item
img.unsqueeze_(0)
data = Variable(img).to(DEVICE)
output = model(data)
_, pred = torch.max(output.data, 1)
y_true.append(label)
y_sore.append(pred.data.item())
print('Image Name:{}, label:{}, predict:{}'.format(dataset_test.imgs[index][0], classes[label], classes[pred.data.item()]))
index += 1
- **运行截图:
