日均处理 10000+ 工作流实例,Apache DolphinScheduler 在 360 数科的实践
点击上方 ![]() 蓝字关注我们
蓝字关注我们

从 2020 年起,360 数科全面将调度系统从 Azkaban 迁移到 Apache DolphinScheduler。作为 DolphinScheduler 的资深用户,360 数科如今每天使用 DolphinScheduler 日均处理 10000+ 工作流实例。
为了满足大数据平台和算法模型业务的实际需求,360 数科在 DolphinScheduler 上进行了依赖组件、Master 与 Worker 状态监控、多机房等多项改造,以更加方便运维。
他们具体是如何进行二次开发的呢?360 数科大数据工程师 刘建敏在不久前的 Apache DolphinScheduler 2 月份 Meetup 进行了详细的分享。
![]()
PROFILE
刘建敏
360 数科 大数据工程师,主要从事 ETL 任务与调度框架的研究,大数据平台以及实时计算平台的开发。
===
01
从 Azkaban 迁移到 DolphinScheduler
2019 年之前,360 数科采用 Azkaban 调度进行大数据处理。
这是一个由 Linkedin 开源的批量工作流任务调度器。其安装简单,只需安装 web 与 executor server,就可以创建任务,并通过上传 zip 包实现工作流调度。
Azkaban 的 web-executor 架构如下图所示:
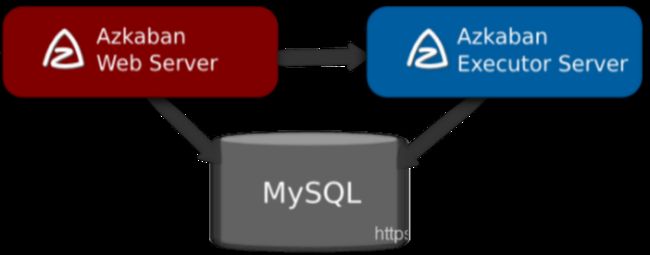
01
Azkaban 的缺点
Azkaban 适用于场景简单的调度,经过三年时间的使用,我们在发现它存在三个重要缺陷:
1. 体验性差
没有可视化创建任务功能,创建与修改任务都需要通过上传 zip 包来实现,这并不方便;另外,Azkaban 没有管理资源文件功能。
2. 功能不够强大
Azkaban 缺乏一些生产环境中不可或缺的功能,比如补数、跨任务依赖功能;用户与权限管理太弱,调度配置不支持按月,在生产上我们需要用很多其他方式进行弥补。
3. 稳定性不够好
最重要的一点是 Azkaban 稳定性不够,当 executor 负载过高时,任务经常会出现积压;小时级别或分钟级别的任务容易出现漏调度;没有超时告警,虽然我们自己开发了有限的短信告警,但还是容易出现生产事故。

针对这些缺陷,我们在 2018 曾进行过一次改造,但由于 Azkaban 源码复杂,改造的过程很是痛苦,因此我们决定重新选型。当时,我们测试了 Airflow、DolphinScheduler 和 XXL-job,但 Airflow Python 的技术栈与我们不符,而 XXL-job 功能又过于简单,显然,DolphinScheduler 是更好的选择。
2019 年,我们 Folk 了 EasyScheduler 1.0 的代码,在 2020 年进行改造与调度任务的部分迁移,并上线运行至现在。
02
DolphinScheduler 选型调研
为什么我们选择 DolphinScheduler?因为其有四点优势:
-
去中心化结构,多 Master 多 Worker;
-
调度框架功能强大,支持多种任务类型,具备跨项目依赖、补数功能;
-
用户体验性好,可视化编辑 DAG 工作流,操作方便;
-
Java 技术栈,扩展性好。
改造过程非常流畅,我们顺利地将调度系统迁移到了 DolphinScheduler。
02
DolphinScheduler 的使用
===
在 360 数科,DolphinScheduler 不仅用于大数据部门,算法部门也在使用其部分功能。为了让算法模型部们更方便地使用 DolphinScheduler 的功能,我们将其整合进了我们自己的毓数大数据平台。
01
毓数大数据平台
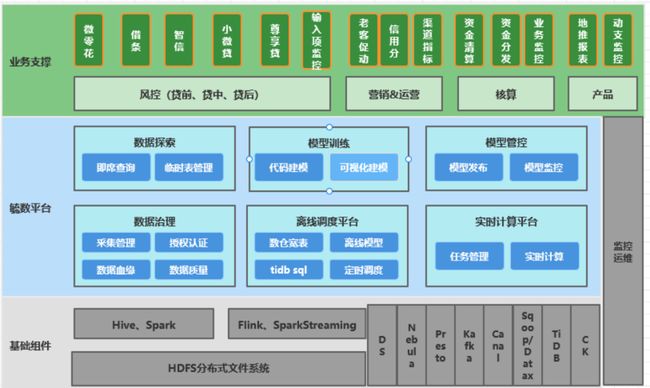
毓数是一个由基础组件、毓数平台、监控运维和业务支撑层组成的大数据平台,可实现查询、数据实时计算、消息队列、实时数仓、数据同步、数据治理等功能。其中,离线调度部分便是通过 DolphinScheduler 调度数据源到 Hive 数仓的 ETL 任务,以及支持 TiDB 实时监控,以实时数据报表等功能。
02
DolphinScheduler 嵌套到毓数
为了支持公司算法建模的需求,我们抽取了常用的一些节点,并嵌套了一层 UI,并调用 API。
算法部门多用 Python 脚本和 SQL 节点,用框表逻辑进行定时,再配置机器学习算法进行训练,组装数据后用 Python 调用模型生成模型分。我们封装了一些 Kafka 节点,通过 Spark 读取 Hive 数据并推送到 Kafka。
03
任务类型
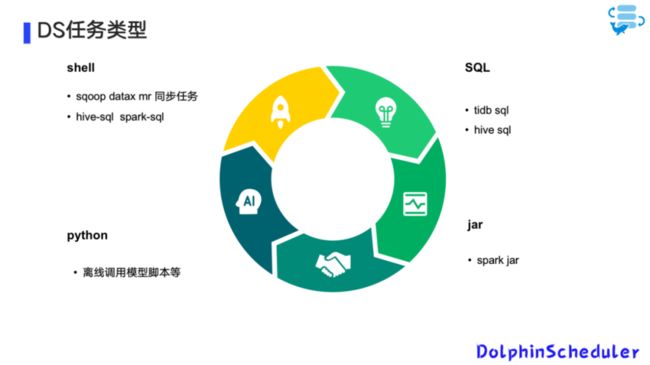
DolphinScheduler 支持的任务类型有 Shell、SQL、Python 和 Jar。其中,Shell 支持 Sqoop DataX mr 同步任务和 Hive-SQL、Spark-SQL;SQL 节点主要是支持 TiDB SQL(处理上游分库分表的监控) 和 Hive SQL;Python 任务类型支持离线调用模型脚本等;Jar 包主要支持 Spark Jar 离线管理。
04
任务场景
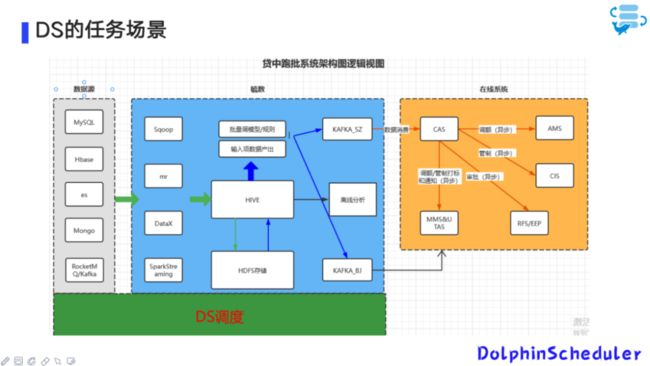
DolphinScheduler 的任务场景主要是将各种数据源,如 MySQL、Hbase 等数据源调度同步至 Hive,再通过 ETL 工作流直接生成 DW。通过 Python 脚本组装或调用,生成模型和规则结果,再推送到 Kafka。Kafka 会给出风控系统调额、审批和分析,并将结果反馈给业务系统。这就是 DolphinScheduler 调度流程的一个完整工作流示例。
05
DolphinScheduler 的运维
目前 ,DolphinScheduler 日均处理工作流已达到 10000+ 的规模,很多离线报表依赖于 DolphinScheduler,因此运维非常重要。
在 360 数科,对 DolphinScheduler 的运维主要分为三部分:
- DS 依赖组件运维
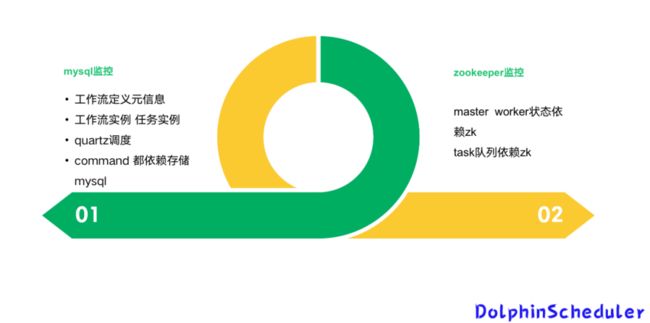
DolphinScheduler 依赖组件的运维主要是针对 MySQL 监控和 Zookeeper 监控。
因为工作流定义元信息、工作流实例和任务实例、Quartz 调度、Command 都依赖 MySQL,因此 MySQL 监控至关重要。曾经有一次机房网络中断,导致很多工作流实例出现漏调度,之后通过 MySQL 监控才得以排查。
Zookeeper 监控的重要性也不言而喻,Master worker 状态和 task 队列都依赖 Zookeeper,但运行至今,Zookeeper 都比较稳定,还未有问题发生。
- Master 与 Worker 状态监控
我们都知道,Master 负责的是任务切分,实际上对业务的影响并不是很大,因此我们采用邮件监控即可;但 Worker 挂掉会导致任务延迟,增加集群压力。另外,由于之前 Yarn 运行任务不一定被成功地 kill,任务容错还可能导致 Yarn 任务重复运行,因此我们对 Worker 状态采用电话告警。
06
Grafana 大盘监控工作流实例状态
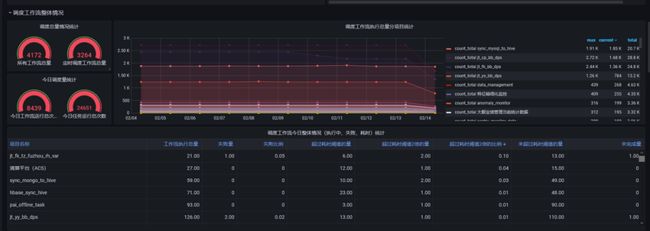
此外,我们还为运维创建了 Grafana 监控看板,可以实时监控工作流实例的状态,包括工作流实例的数量,各项目工作流实例运行状态,以及超时预警设置等。
03
DolphinScheduler 改造
===
01
体验性改造
-
增加个人可以授权资源文件与项目,资源文件区分编辑与可读权限,方便授权;
-
扩展全局变量(流程定义id, 任务id等放到全局变量中),提交到yarn上任务可追踪到调度的任务,方便集群管理,统计工作流实例锁好资源,利于维护;
-
工作流复制、任务实例查询接口优化,提高查询速度,以及 UI 优化。
02
增加短信告警改造
因为原有的邮箱告警不足以保证重要任务的监控,为此我们在 UI 上增加了 SMS 告警方式,保存工作流定义。另外,我们还把告警 receivers 改造成用户名,通过 AlertType 扩展成短信、邮箱等告警方式关联到用户信息,如手机号等,保证重要性任务失败后可以及时收到告警。
03
Worker 增加维护模式改造
此外,当 worker 机器需要维护时,需要这台 worker 上不会有新的运行任务提交过来。为此,我们对 worker 增加了维护模式改造,主要包括 4 点:
-
UI 设置 worker 进行维护模式,调用 API 写入worker 指定的 zk 路径;
-
WorkerServer 进行定时调度轮询是否维护模式;
-
WorkerServer 进行维护模式 ,FetchTaskThread 不获取新增任务;
-
worker 任务运行结束,可进行重启。
经过以上改造,我们运维的压力大大减轻。
04
多机房改造
最后,我们还进行了多机房改造。因为我们之前有 2 套集群,分布在不同的机房,我们的改造目标是在调度中设置多机房,这样当某一个机房出现故障后,可一键切换到其他机房使用,实现多机房使用同一套调度框架。
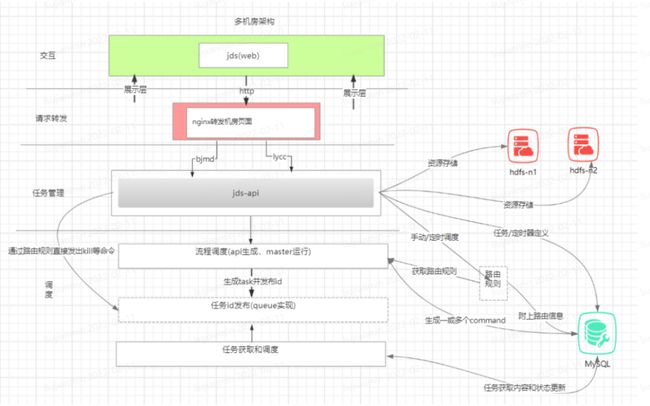
改造的切入点就是在调度中设置多机房,以保证某一任务可以在多机房启动。改造流程如下:
-
在各机房分别部署 ZK,Master 与 Worker 注册到对应的机房,Master 负责任务切分,Worker 负责任务处理,各自处理各机房的任务;
-
schedule 与 command 带上 datacenter 信息
-
为保证双机房任务切换,资源文件进行上机房任务上传,同时改动任务接口,任务依赖、Master容错都需要改造过滤对应机房。

参与开源
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
![]()
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。

海豚调度
Apache DolphinScheduler 是一个分布式、易扩展并带有强大可视化界面的大数据工作流调度平台。已在 600+ 家公司的生产环境上稳定运行。
98篇原创内容
公众号
社区官网
https://dolphinscheduler.apache.org/
代码仓地址****https://github.com/apache/dolphinscheduler
您的 Star,是 Apache DolphinScheduler 为爱发电的动力❤️ ~
投稿请添加****社区小助手微信
(Leonard-ds)
![]()

☞Apache DolphinScheduler 2.0.5 发布,Worker 容错流程优化
☞Apache DolphinScheduler 版本控制核心原理揭
☞喜讯 | Apache DolphinScheduler PMC Chair 代立冬,PMC 郭强获邀成为 ASF Member
☞途家大数据平台基于 Apache DolphinScheduler 的探索与实践
☞Apache DolphinScheduler 2.0 时代 API 接口变化
☞海豚调度在 Kubernetes 体系中的技术实战
☞Apache 基金会中国项目活跃度分析 Top20 发布,DolphinScheduler 位列第四