【Scikit-Learn】k-近邻算法实例
现在我们有一个糖尿病数据集(数据集下载地址:www.kaggle.com/uciml/pima-indians-diabetes-database),共有768个样本、8个特征。其中最后列outcome为标记值(0表示没有糖尿病,1表示有糖尿病)。
本文首先通过交叉验证来选择模型从3种模型中选择出最优模型KNN,然后绘画出KNN的学习曲线。
由于该糖尿病数据集含有8个特征,并不能进行可视化。因此本文选择相关性最大的两个特征进行可视化。
1.读入数据集
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 加载数据
data = pd.read_csv('datasets/pima-indians-diabetes/diabetes.csv')
print('dataset shape {}'.format(data.shape))
data.head()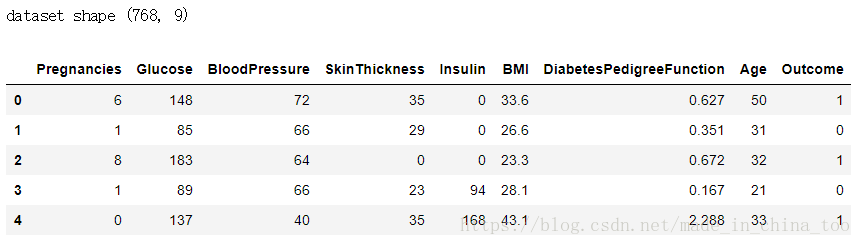
# 查看数据集中阳性、阴性样本的个数
data.groupby("Outcome").size()
'''
Outcome
0 500
1 268
dtype: int64
'''
X = data.iloc[:, 0:8]
Y = data.iloc[:, 8]
print('shape of X {}; shape of Y {}'.format(X.shape, Y.shape))
'''
shape of X (768, 8); shape of Y (768,)
'''2.通过交叉验证来选择模型
这里共有三种不同的模型,并对比常规方法(直接使用测试集来计算模型性能)和10折交叉验证法(将数据集分成10分,每次取1份作为测试集,其余9份作为训练集。最后由该10次测试集对应的分类准确率的平均值作为模型的最终性能)的异同。
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifier
models = []
models.append(("KNN", KNeighborsClassifier(n_neighbors=2)))
models.append(("KNN with weights", KNeighborsClassifier(
n_neighbors=2, weights="distance")))
models.append(("Radius Neighbors", RadiusNeighborsClassifier(
n_neighbors=2, radius=500.0)))
# 使用常规的方法来计算各模型的准确率
results = []
for name, model in models:
model.fit(X_train, Y_train)
results.append((name, model.score(X_test, Y_test)))
for i in range(len(results)):
print("name: {}; score: {}".format(results[i][0],results[i][1]))
'''
name: KNN; score: 0.6818181818181818
name: KNN with weights; score: 0.6818181818181818
name: Radius Neighbors; score: 0.6038961038961039
'''
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# 进行10折交叉验证来对比各模型的性能
results = []
for name, model in models:
kfold = KFold(n_splits=10)
# 将数据集分成10分,每次取1份作为测试集,其余9份作为训练集。最后返回10次测试集对应的分类准确率
cv_result = cross_val_score(model, X, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print("name: {}; cross val score: {}".format(
results[i][0],results[i][1].mean()))
'''
name: KNN; cross val score: 0.7147641831852358
name: KNN with weights; cross val score: 0.6770505809979495
name: Radius Neighbors; cross val score: 0.6497265892002735
'''3.绘画学习曲线
通过上面交叉验证法分别评估三种模型的性能,模型KNN的性能最好,因此以下以模型KNN为分析对象,画出其学习曲线。
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, Y_train)
train_score = knn.score(X_train, Y_train)
test_score = knn.score(X_test, Y_test)
print("train score: {}; test score: {}".format(train_score, test_score))
'''
train score: 0.8387622149837134; test score: 0.6818181818181818
'''
from sklearn.model_selection import ShuffleSplit
from common.utils import plot_learning_curve
'''
其中plot_learning_curve是封装好在common.utils中的函数,其实现如下:
def plot_learning_curve(plt, estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o--', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
'''
knn = KNeighborsClassifier(n_neighbors=2)
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
plt.figure(figsize=(10, 6), dpi=200)
plot_learning_curve(plt, knn, "Learn Curve for KNN Diabetes",
X, Y, ylim=(0.0, 1.01), cv=cv);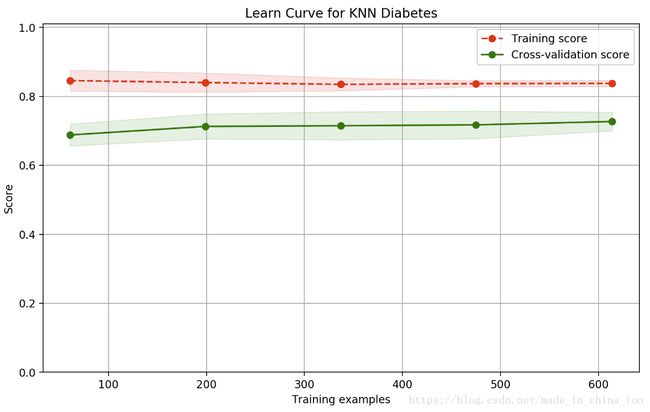
4.选择相关性最大的两个特征进行可视化
由于该糖尿病数据集含有8个特征,并不能进行可视化。因此选择相关性最大的两个特征进行可视化。
from sklearn.feature_selection import SelectKBest
# 返回X 中相关性最大的 2 个特征。
selector = SelectKBest(k=2)
X_new = selector.fit_transform(X, Y)
#经过观察,相关性最大的2个特征为Glucose和BMI
X_new[0:5]
'''
array([[ 148. , 33.6],
[ 85. , 26.6],
[ 183. , 23.3],
[ 89. , 28.1],
[ 137. , 43.1]])
'''
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X_new, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print("name: {}; cross val score: {}".format(
results[i][0],results[i][1].mean()))
'''
name: KNN; cross val score: 0.725205058099795
name: KNN with weights; cross val score: 0.6900375939849623
name: Radius Neighbors; cross val score: 0.6510252904989747
'''
# 画出数据
plt.figure(figsize=(10, 6), dpi=200)
plt.ylabel("BMI")
plt.xlabel("Glucose")
plt.scatter(X_new[Y==0][:, 0], X_new[Y==0][:, 1], c='r', s=20, marker='o'); # 画出样本
plt.scatter(X_new[Y==1][:, 0], X_new[Y==1][:, 1], c='g', s=20, marker='^'); # 画出样本