记一个基于JEECG-BOOT的比较复杂的增删改功能的实现
做了分布式数据库,跨库调字典数据,多表增删改,需要存冗余字段,界面如下:
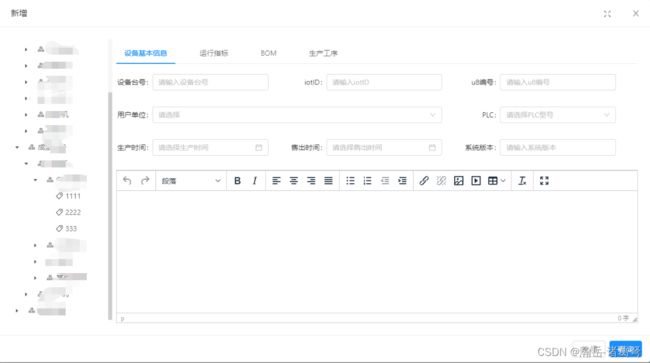
需求:
(1)list页面可以复用
(2)增、删自定义页面完成
1、JEECG-BOOT生成的前端页面的理解
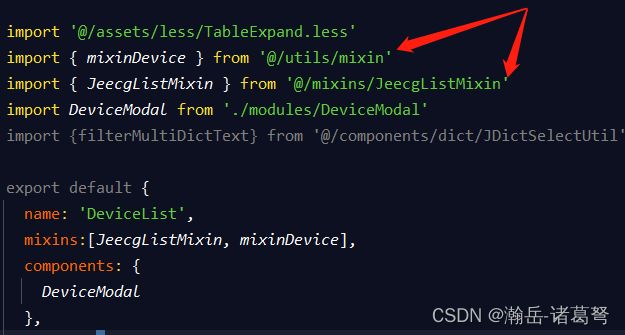
(1)混入脚本

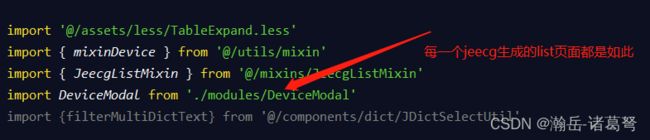
前端自定义页面List是列表页无疑,但是里面一些方法、函数并没有出现,是因为JEECG为了前端代码简单,进行了混入封装,主要包括两个混入脚本:@/utils/mixin和@/mixins/JeecgListMixin
(2)J-modal
此外,增加、删除,JEECG-BOOT在ant-design-vue的a-modal基础上进行了修改,故:所有的弹出窗口通过插槽实现,如下:
跳转到DeviceModal.vue再看:
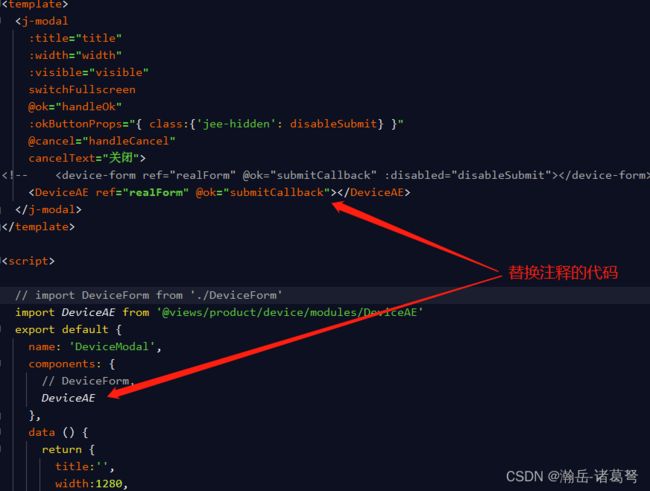
DeviceModal.vue页面不需要做其它修改。所有代码非必要均可保持与生成时的一致。
通过上图,可以完成默认页面的替换
2、跨库访问数据
JEECG当中虽然用的是微服务方式,但是数据库依然没有分开。这能够很好地延续SOA的开发思想。所以,在开发过程中需要对数据库进行分布式处理。配合nacos的在线配置,实现不同应用访问不同数据库。
(1)数据库的设置

从上图可以看出,每一个子系统均是独立的数据库,这样的好处很多,一是降低耦合(库表分离),二是提高系统的健壮性(一个库出问题或卡死,不影响其他业务系统运行),三是提高系统的性能(实现分布式)
(2)在nacos中做好配置
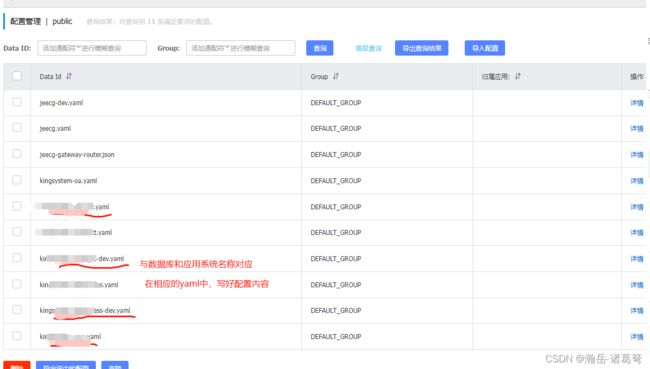
记住springboot的配置加载顺序:
读取优先级:bootstrap.yml(本地) > application.yml (全局共用,即:test/dev/prod通用)> application-dev.yml > order-service.yaml >order-service-dev.yaml
作用优先级:与上面顺序相反,即:最后读取的覆盖前面读取的配置
具体应用与哪一个nacos配置相关联,在start模块中的bootstrap.yml配置中指定,如下图:
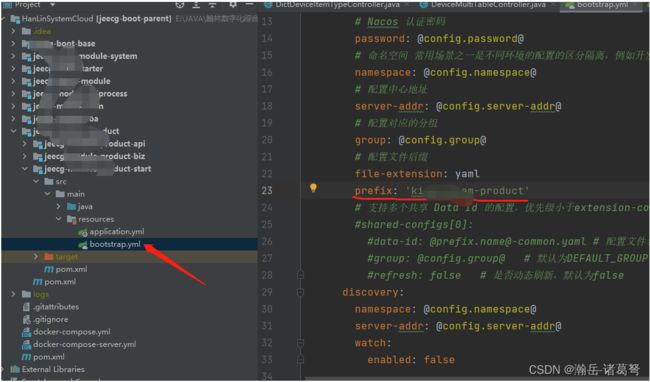
这是官方推荐的做法,理论上可以全部配置到本地,或者配置到nacos,具体为什么这么做,还没有深入研究,有待进一步学习。
3、功能实现
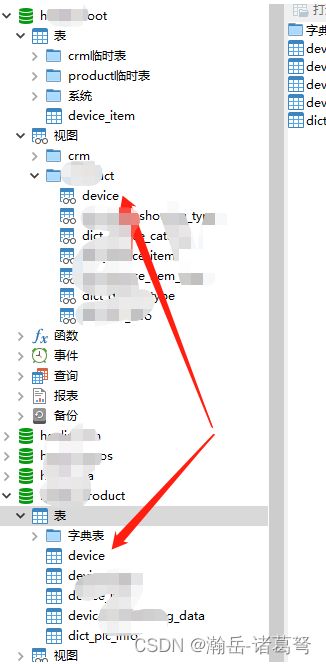
(1)通过视图实现数据库的跨库数据读取共享
上文已述,JEECG-BOOT虽然做了微服务,但在数据库端依然是单体数据库,所以其生成的代码、控件,均是从boot库中提取数据(默认控件读数据在boot),而我们在其基础之上进行了数据库的分布式设计(写数据在具体业务库),虽然可以完全抛弃jeecg-boot的生成代码,自定义各种控件实现完全的分库目的,但是工作量比较大,在时间比较紧张的情况下没有必要(后续可修改jeecg-boot底层,使生成代码也满足自身个性化需要)。
为了符合jeecg-boot的默认读需求,非常简单,通过视图跨库共享数据即可,以下图的device表为例,在jeecg的boot库中,只需按:select * from hanlin_product.device生成一个名为device的视图即可。
(2)自定义多表实体类,满足反序列化需求
这次实现的功能如下图所示:
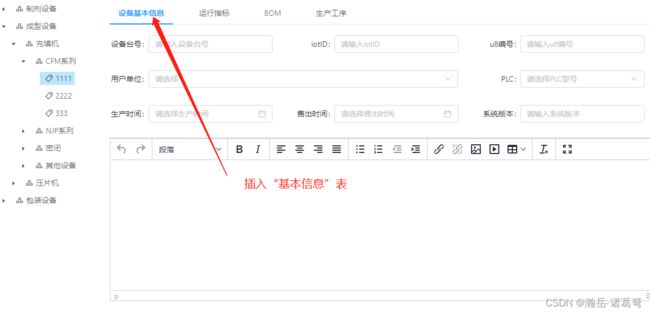
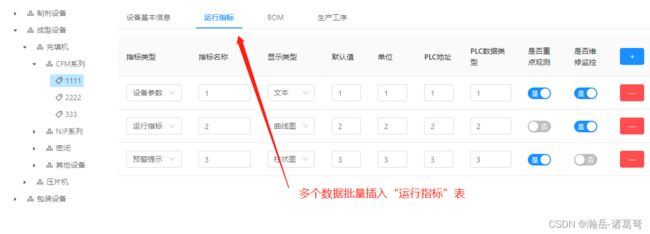
这是一个典型的“1对多”,主附表的插入。
JEECG并没有提供很好的方式实现这种高度定制化的功能。所以前后端需要根据交互设计重新开发。
首先,Jeecg的反序列化封装的很好,很方便,比JQuery中直接用json2来的简单,与所有的反序列化思路一致:先建立实体类,再进行反序列化。故后端代码在JEECG生成的基础之上做如下构建:
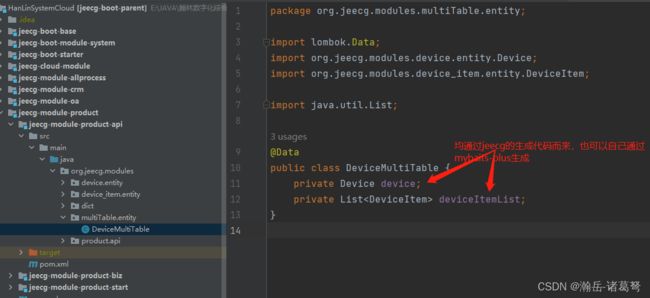
此处,个人建议是建立一个多表的包,将所有涉及多表的实体全部放在此文件夹,方便运维和管理。如上图中,所建立的包名为:multiTable
其次,建立多表的后端操作,依然基于jeecg生成的代码即可,编写非常高效、简单

这里需要注意的是:jeecg生成的saveBatch操作(jeecg也是通过mybatis-plus生成的代码)并不是真正意义上的批量保存,在大并发写入时存在效率瓶颈。在小批量内容写入时没有问题,一旦并发过高,要用redis+mq突破瓶颈(这个后面再说,要自己写)。
(3)前端代码,以及前后端调用
先看前端的data,注释如
data() {
return {
showPopMsg: false,//控制彈出窗口
deviceId:'',//当前设备id,增加的时候默认分配guid,编辑的时候是当前编辑的记录的id
model: {},//沿用生成代码,放的是当前表的实体,即:各种表属性以model.xx存在
labelCol: {
xs: { span: 24 },
sm: { span: 5 }
},
wrapperCol: {
xs: { span: 24 },
sm: { span: 16 }
},
confirmLoading: false,//是否提示正在加载,大批量数据操作时使用
validatorRules: {},
url: {
add: '/jeecg-product/deviceMultiTable/saveWhole',
edit: '/jeecg-product/deviceMultiTable/editWhole',
queryById: '/jeecg-product/device/device/queryById'
},//编辑、删除的后端controller接口地址
columns: [
{
title: '指标类型',
dataIndex: 'itemTypeId',
key: 'itemTypeId',
width: 80,
scopedSlots: { customRender: 'itemTypeId' }
},
{
title: '指标名称',
dataIndex: 'itemName',
key: 'itemName',
width: 120,
scopedSlots: { customRender: 'itemName' }
},
{
title: '显示类型',
dataIndex: 'dataShowingTypeId',
key: 'dataShowingTypeId',
width: 80,
scopedSlots: { customRender: 'dataShowingTypeId' }
},
{
title: '默认值',
dataIndex: 'defaultValue',
key: 'defaultValue',
width: 80,
scopedSlots: { customRender: 'defaultValue' }
},
{ title: '单位', dataIndex: 'unit', key: 'unit', width: 80, scopedSlots: { customRender: 'unit' } },
{
title: 'PLC地址',
dataIndex: 'plcPlace',
key: 'plcPlace',
width: 80,
scopedSlots: { customRender: 'plcPlace' }
},
{
title: 'PLC数据类型',
dataIndex: 'plcType',
key: 'plcType',
width: 100,
scopedSlots: { customRender: 'plcType' }
},
{
title: '是否重点观测',
dataIndex: 'isObservingItem',
key: 'isObservingItem',
width: 80,
scopedSlots: { customRender: 'isObservingItem' }
},
{
title: '是否维修监控',
dataIndex: 'isMaintainingItem',
key: 'isMaintainingItem',
width: 80,
scopedSlots: { customRender: 'isMaintainingItem' }
},
{
dataIndex: 'oper',
key: 'oper',
width: 80,
scopedSlots: { customRender: 'oper' },
slots: { title: 'operTitle' }
}
],//list列表的字段
deviceItemData: [],//自定义属性,用于批量生成的内容
selectedDeviceTypeId: ''//自定义属性,用于保存自定义控件的值
}
},Methods代码不一一展示(具体可看附件)
此处须注意的是submitForm()的修改:

4、改进思路
(1)saveBatch在大并发过程中可以提供真正的批量保存实现,也可通过redis+mq的方式稳定写入数据库(避免数据库的“写”阻塞),现mybatis-plus生成的代码是“循环+插入”,大并发时肯定存在写瓶颈。
(2)数据库在分布式的基础上,再次进行读写分离,可大大提高并发效率
(3)前端代码虽然完成了功能,但写的比较稀碎,不利于维护,可在现有代码基础上做好封装,包括js封装和单文件组件封装。